

Организация хранилищ данных
Основой концепции хранилищ данных (ХД) является необходимость разделения наборов данных, предназначенных для транзакционной обработки, и наборов данных для анализа в системах поддержки принятия решений (СППР). Это разделение осуществляется интеграцией, согласованием и агрегацией разъединенных данных из OLTP-систем и внешних источниках данных в ХД. Автор концепции W. Inmon определяет ХД как предметно-ориентированные, интегрированные, неизменчивые, поддерживающие хронологию средства хранения данных [2,3].
Концепция ХД обеспечивает единую модель представления данных предприятия, организации и реализацию интегрированного источника данных. В соответствие с этой реализацией в ХД собираются данные из транзакционных БД и других источников. В ХД поддерживается хронология данных: сохраняются данные о времени. Концептуально модель ХД можно представить в виде схемы на рисунке 2.3. Данные из различных источников помещаются в ХД, а их описания в репозиторий метаданных. Пользователь, используя средства визуализации, построения отчетов, статистической обработки и другие, анализирует данные в хранилище. Выбор средств работы пользователя с ХД теоретически не должен влиять на его структуру и функции поддержания в актуальном состоянии. Физическая реализация приведённой концептуальной схемы может быть самой разнообразной.
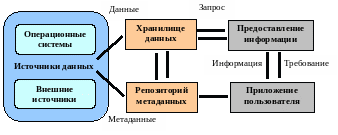
Рисунок 2.3 – Концептуальная модель хранилища данных
Виртуальное ХД эмулируют работу с данными в информационной системе, как с хранилищем данных. Виртуальное ХД можно организовать, создав ряд «представлений» (view) в БД или применив специальные средства доступа. Главными достоинствами такого подхода являются простота и малая стоимость реализации, единая платформа с источником информации, отсутствие сетевых соединений между источником информации и ХД. Существенный недостаток в том, что создается не ХД как таковое, а иллюзия его существования. Структура хранения и само хранение не претерпевают изменений, и остаются проблемы с производительностью системы, трансформацией данных, интеграцией данных с другими источниками, отсутствие истории и чистоты данных, зависимость от характеристик основной БД.
Известна двухуровневая архитектура ХД, предполагающая построение витрин данных (Data mart) без создания центрального хранилища. При этом вся информация, поступающая из OLTP-систем, ограничена конкретной предметной областью. При построении витрин данных используются основные принципы построения ХД, которые можно рассматривать как ХД в миниатюре. Достоинства этого подхода состоит в простоте и малой стоимости реализации, высокой производительности за счет физического разделения регистрирующих и аналитических систем, поддержке истории данных и возможности добавления метаданных. Концепция витрин данных предложена Forrester Research в 1991 году [4]. Главная идея витрин данных – сохранение тематического подмножества заранее агрегированных данных. Размер тематического подмножества данных намного меньше множества данных ХД, что значительно снижает уровень требования к производительности компьютерной техники.
Построение ХД предприятия, как правило, выполняется в трехуровневой архитектуре. На первом уровне расположены разнообразные источники данных и справочные системы. Второй уровень ХД содержит центральное хранилище и, возможно, оперативный склад данных. В центральном хранилище консолидируется информация от всех источников с первого уровня. Оперативный склад данных не содержит исторических данных и выполняет две функции: хранения аналитической информации для оперативного управления и подготовки данных для последующей загрузки в центральное хранилище. Третий уровень ХД представляет собой набор предметно-ориентированных витрин данных, данные в которые загружаются из центрального хранилища данных. Таким образом, ХД представляет собой предметно-ориентированное, интегрированное, связанное со временем и неизменное во времени собрание данных. Предметная ориентация коллекции данных означает, что данные отражают существенные аспекты деятельности организации. Интеграция данных предполагает собрание данных в целостную структуру, обеспечивающую анализ данных.
Концепция ХД в первую очередь ориентирована на хранение данных и во вторую – на обработку данных. Архитектура аналитических систем, в том числе СППР, не предопределяется концепцией ХД. Применение концепции позволяет проектировщику и разработчику сосредоточится на требованиях к данным с учетом функциональности аналитической системы. Типичная структура ХД отличается от структуры реляционной СУБД. Как правило, структура ХД (витрины данных) не нормализована и может допускать избыточность данных.
Основными составляющими структуры хранилищ данных являются таблица фактов (Fact table) и таблицы измерений (Dimension tables).
Таблица фактов. Таблица фактов является основной таблицей хранилища данных. Как правило, она содержит сведения об объектах или событиях, совокупность которых будет в дальнейшем анализироваться. Обычно выделяют четыре встречающихся типа фактов:
факты, связанные с транзакциями (Transaction facts). Они основаны на отдельных событиях;
факты, связанные с «моментальными снимками» (Snapshot facts). Основаны на состоянии объекта;
факты, связанные с элементами документа (Line-item facts). Основаны на том или ином документе;
факты, связанные с событиями или состоянием объекта (Event or state facts), представляюobt возникновение события без подробностей.
Таблица фактов, как правило, содержит уникальный составной ключ, объединяющий первичные ключи таблиц измерений. Чаще всего это целочисленные значения либо значения типа «дата/время» — ведь таблица фактов может содержать сотни тысяч или даже миллионы записей, и хранить в ней повторяющиеся текстовые описания, как правило, невыгодно — лучше поместить их в меньшие по объему таблицы измерений. При этом как ключевые, так и некоторые неключевые поля должны соответствовать будущим измерениям OLAP-куба. Помимо этого таблица фактов содержит одно или несколько числовых полей, на основании которых в дальнейшем будут получены агрегатные данные.
Таблица фактов, которая может быть построена на основе БД Valuation Works, приведена на рисунке 2.4. В рассматриваемом примере измерениям будущего куба соответствуют первые шесть полей, а агрегатным данным — последние четыре. В таблице фактов нет никаких сведений о том, как группировать записи при вычислении агрегатных данных. В ней есть идентификаторы продуктов или клиентов. Эти сведения, в дальнейшем используемые для построения иерархий в измерениях куба, содержатся в таблицах измерений.

Рисунок 2.4 – Пример таблицы фактов
Таблицы измерений содержат неизменяемые либо редко изменяемые данные. В подавляющем большинстве случаев эти данные представляют собой по одной записи для каждого члена нижнего уровня иерархии в измерении. Таблицы измерений также содержат как минимум одно описательное поле (обычно с именем члена измерения) и, как правило, целочисленное ключевое поле (обычно это суррогатный ключ) для однозначной идентификации члена измерения. Если будущее измерение, основанное на данной таблице измерений, содержит иерархию, то таблица измерений также может содержать поля, указывающие на «родителя» данного члена в этой иерархии. Таблица измерений может содержать и поля, указывающие на «прародителей», и иных «предков» в данной иерархии. Каждая таблица измерений должна находиться в отношении «один ко многим» с таблицей фактов (рисунок 2.5).

Рисунок 2.5 – Пример таблицы измерений
Одно измерение куба может содержаться как в одной таблице, так и в нескольких связанных таблицах, соответствующих различным уровням иерархии в измерении (рисунок 2.6). Если каждое измерение содержится в одной таблице, такая схема хранилища данных носит название «звезда».
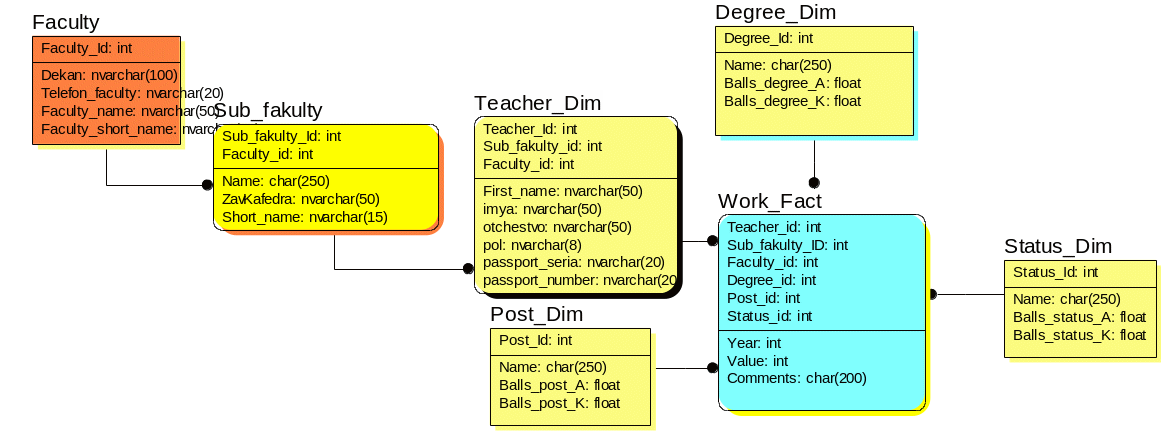
Рисунок 2.6 – Пример схемы «снежинка»
Если же хотя бы одно измерение содержится в нескольких связанных таблицах, такая схема хранилища данных носит название «снежинка». Дополнительные таблицы измерений в такой схеме, обычно соответствующие верхним уровням иерархии измерения и находящиеся в соотношении «один ко многим» в главной таблице измерений, соответствующей нижнему уровню иерархии, иногда называют консольными таблицами (рисунок 2.6). Даже в случае иерархических измерений в модели данных с целью повышения скорости выполнения запросов к ХД нередко предпочтение отдается схеме «звезда».