

Формальная постановка задачи кластеризации
Формальная постановка
задачи кластеризации осуществляется
следующим образом. Определяется множество
объектов данных
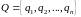 .
Каждый объект
.
Каждый объект
 характеризуется набором атрибутов:
характеризуется набором атрибутов:
 .
.
Примером такого множества объектов может быть коллектив преподавателей высшего учебного заведения, каждый из которых характеризуется набором показателей (атрибутов) о квалификации, учебно-методической и научной деятельности, внеаудиторной работе.
Каждая переменная
из набора
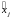 принимает значения из множества
действительных чисел
принимает значения из множества
действительных чисел
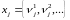 .
Решением задачи кластеризации является
множество сформированных кластеров
.
Решением задачи кластеризации является
множество сформированных кластеров
 ,
,
где
 -
кластер, содержащий
похожие объекты из множества
-
кластер, содержащий
похожие объекты из множества
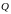 ,
,
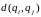 -
мера близости между объектами,
-
мера близости между объектами,
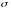 -
величина, определяющая меру близости
между объектами.
-
величина, определяющая меру близости
между объектами.
Мера близости должна отвечать следующим условиям [1, 2]:
а)
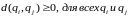 ;
;
б)
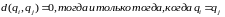 ;
;
в)
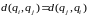 ;
;
г)
 .
.
При выполнении
неравенства
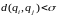 объекты из множества
рассматриваются как близкие и помещаются
в один кластер. Иначе объекты помещаются
в разные кластеры.
объекты из множества
рассматриваются как близкие и помещаются
в один кластер. Иначе объекты помещаются
в разные кластеры.
Меры близости в кластерном анализе
В задачах кластеризации
выбор меры близости предполагает
представление объектов в виде точек
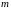 -
мерного пространства
-
мерного пространства
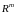 .
При этом меры близости определяют
расстояние между двумя точками
пространства
.
Наибольшее применение находят следующие
меры: евклидово
расстояние, расстояние по Хеммингу,
расстояние Чебышева, расстояние
Махаланобиса.
.
При этом меры близости определяют
расстояние между двумя точками
пространства
.
Наибольшее применение находят следующие
меры: евклидово
расстояние, расстояние по Хеммингу,
расстояние Чебышева, расстояние
Махаланобиса.
Евклидово расстояние между объектами вычисляется по формуле:
 .
.
Данная мера придаёт большие веса более отдалённым друг от друга объектам из заданного множества .
Расстояние по Хеммингу вычисляется следующим образом:
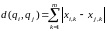 .
.
Эта мера в отличие от расстояния Евклида снижает влияние больших разностей по отдельным атрибутам на результаты кластеризации.
Для оценки расстояния по Чебышеву используется формула:
 .
.
Как правило, формула Чебышева используется при необходимости разнести объекты по кластерам, имеющим существенное различие только по одному атрибуту (измерению).
Расстояние Махаланобиса вычисляется по формуле:
 ,
,
где – ковариационная
матрица размерности
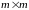 ,
,
 - символ транспонирования [1].
- символ транспонирования [1].
К настоящему времени известно более 100 алгоритмов кластерного анализа. Все алгоритмы разделяют на иерархические и неиерархические алгоритмы.
Иерархические алгоритмы кластеризации
Иерархические алгоритмы кластерного анализа в свою очередь разделяют на агломеративные и дивизимные.
В иерархических
агломеративных алгоритмах кластеризации
исходное множество объектов
представляется как множество кластеров
 .
Таким образом, на первом шаге алгоритма
имеем:
.
Таким образом, на первом шаге алгоритма
имеем:
 и
и
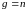 .
.
На втором
шаге алгоритма, используя выбранную
меру близости
 ,
находят кластеры с наименьшим удалением
друг от друга и осуществляют слияние
кластеров
,
находят кластеры с наименьшим удалением
друг от друга и осуществляют слияние
кластеров
 в общий кластер
в общий кластер
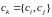 .
Процесс поиска кластеров с наименьшим
удалением и их слияние повторяют. В
результате формируются множества
кластеров мощностью
.
Процесс поиска кластеров с наименьшим
удалением и их слияние повторяют. В
результате формируются множества
кластеров мощностью
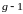 ,
,
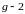 ,
,
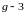 ,
…. Пересчет расстояния между кластером
,
…. Пересчет расстояния между кластером
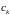 и кластером
и кластером
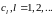 выполняют по формуле:
выполняют по формуле:
 ,
,
где
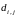 –
расстояние между кластерами
–
расстояние между кластерами
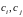 ,
,
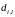 –
расстояние между кластерами
–
расстояние между кластерами
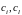 ,
,
 –
расстояние между кластерами
–
расстояние между кластерами
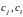 ,
,
 –
весовые коэффициенты. В методе медиан
используются следующие значения
коэффициентов:
–
весовые коэффициенты. В методе медиан
используются следующие значения
коэффициентов:
 [1].
[1].
В дивизимных алгоритмах исходное множество представляется как единственный кластер. Таким образом, на первом шаге имеем:
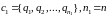 .
.
На втором
шаге алгоритма выбирается объект
 ,
который наиболее удален от других
объектов в этом кластере. Удаление
объекта
определяется как наибольшее среднее
расстояния до других объектов кластера
и рассчитывается по формуле:
,
который наиболее удален от других
объектов в этом кластере. Удаление
объекта
определяется как наибольшее среднее
расстояния до других объектов кластера
и рассчитывается по формуле:
 .
.
Формируется
новый кластер
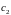 .
Выбранный объект
удаляется из кластера
.
Выбранный объект
удаляется из кластера
 и помещается в кластер
(
и помещается в кластер
( ).
На последующих шагах алгоритма объекты
из кластера
,
у которых разность значений между
средним расстоянием до объектов в
и средним расстоянием до объектов в
наибольшая, переносятся в
.
Перенос объектов из
в
продолжается до тех пор, пока разности
средних расстояний не станут отрицательными.
В результате выполнения последовательности
шагов формируются два кластера.
).
На последующих шагах алгоритма объекты
из кластера
,
у которых разность значений между
средним расстоянием до объектов в
и средним расстоянием до объектов в
наибольшая, переносятся в
.
Перенос объектов из
в
продолжается до тех пор, пока разности
средних расстояний не станут отрицательными.
В результате выполнения последовательности
шагов формируются два кластера.
К одному из сформированных кластеров применяют рассмотренную выше процедуру разделения. Выбор кластера для разделения может осуществляться на основе оценки диаметров кластеров. Оценка диаметра кластеров выполняется с применением формулы:
 ,
,
 .
.
Разделение кластеров производится до тех пор, пока все члены одного кластера не будут отвечать требованию близости или все кластеры будут содержать по одному объекту.