

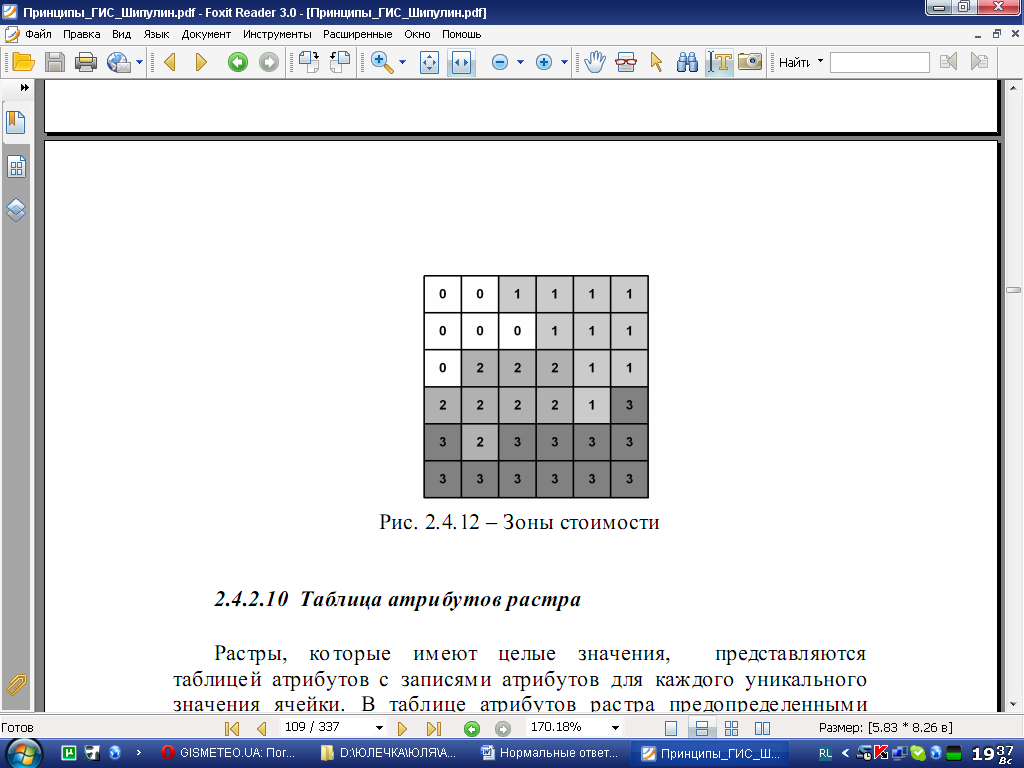
6. Таблица атрибутов растра
Растры, которые имеют целые значения, представляются таблицей атрибутов с записями атрибутов для каждого уникального значения ячейки. В таблице атрибутов растра предопределенными полями являются Значение (Value) и Количество ячеек (Count). В таблице может быть добавлено пользовательское поле.

Растры с целыми значениями предоставляют возможность выполнения операций с таблицами – добавление полей, вычисления, модификация значений и др. Растры с действительными значениями такой возможности не предоставляют.
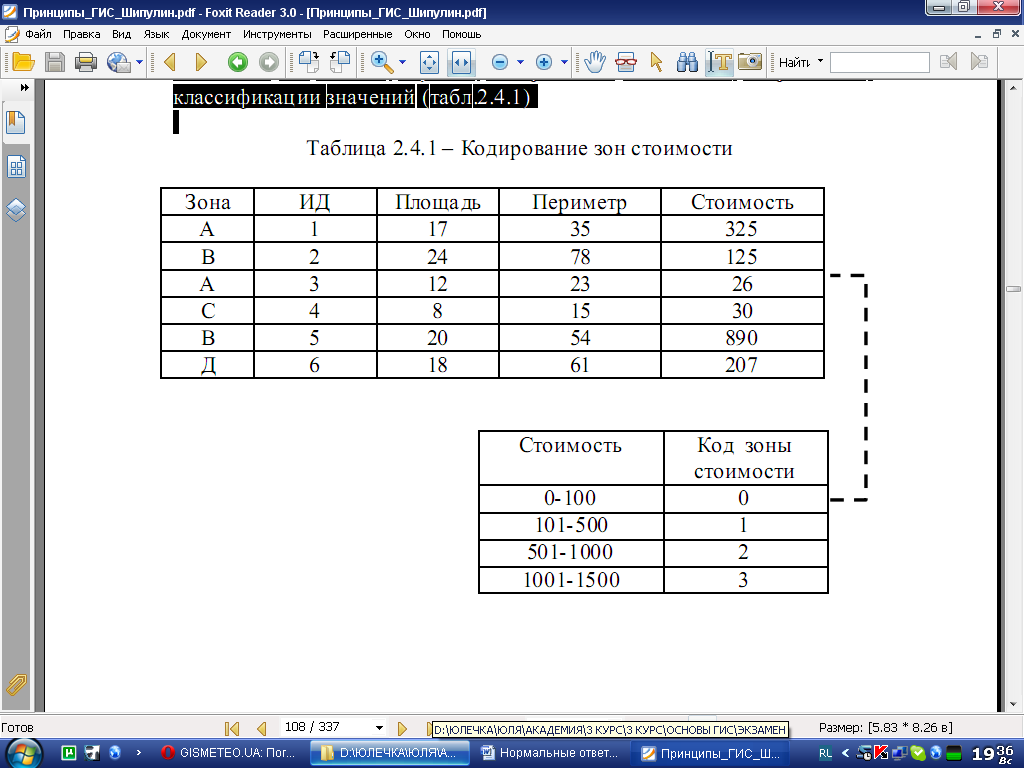
7. Зонирование
В растровой модели зона – это целостный объект, который определяется множеством смежных ячеек, имеющих одинаковые значения. Во многих случаях зонирование выполняют посредством
классификации
значений (табл.2.4.1)
8. Хранение растровых данных
Растры применяются для хранения и обработки данных дистанционного зондирования, для создания и анализа цифровых моделей поверхности, при визуализации геоданных и т.д. Для
хранения растровых данных разработано множество вариантов кодирования растровых структур. Некоторые из них более экономно расходуют память, другие позволяют получать более быстрые алгоритмы.
Способ полного представления (Exhaustive representation) – это прямой ввод одной ячейки за другой. Растровое изображение обычно разлагается по строке сверху – слева. При этом порядке сканирования в конце каждой строки происходит скачок на начало следующей строки. Таким образом, двумерное ячеистое изображение хранится в памяти компьютера в виде одномерной последовательности значений. Это самый простой способ ввода данных растровых моделей.

Способ последовательного кодирования (Run-length encoding) основан на фиксировании повторяющегося значения и позиции – номера колонки с последним э тим значением.

9. Методы сжатия растровых данных
Самый простой способ ввода данных растровых моделей - прямой ввод одной ячейки за другой. Недостатками э того подхода являются требования большого объема памяти в компьютере и значительного времени для организации процедур ввода-вывода.
Сжатие данных (Data compression) - процесс, обеспечивающий уменьшение объема данных путем сокращения их избыточности. Сжатие данных связано с компактным расположением порций данных стандартного размера. Различают сжатия с потерей и без потери информации.
Метод группового кодирования.
В некоторых форматах графических файлов используется сжатие изображения, основанное на замене длительных последовательностей повторяющихся значений парой -"значение, количество повторов".
Для сжатия информации, полученной со снимка или карты, применяется кодирование участков развертки или метод группового кодирования, учитывающий то, что значения повторяются в
нескольких ячейках. Суть метода группового кодирования состоит в том, что данные вводятся парой чисел, первое обозначает длину группы, второе - значение. Изображение просматривается построчно, и как только определенный тип элемента или ячейки встречается впервые, он помечается признаком начала. Если за данной ячейкой следует цепочка ячеек того же типа, то их число подсчитывается, а последняя ячейка помечается признаком конца. В этом случае в памяти хранятся только позиции помеченных ячеек и значения соответствующих счетчиков. Применение такого метода значительно упрощает хранение и воспроизведение изображений (карт), когда однородные участки (как правило) превосходят размеры одной ячейки. Обычно ввод осуществляют слева направо, сверху вниз. Рассмотрим, например, бинарный массив матрицы 5x6 (Рис. 2.6.16):
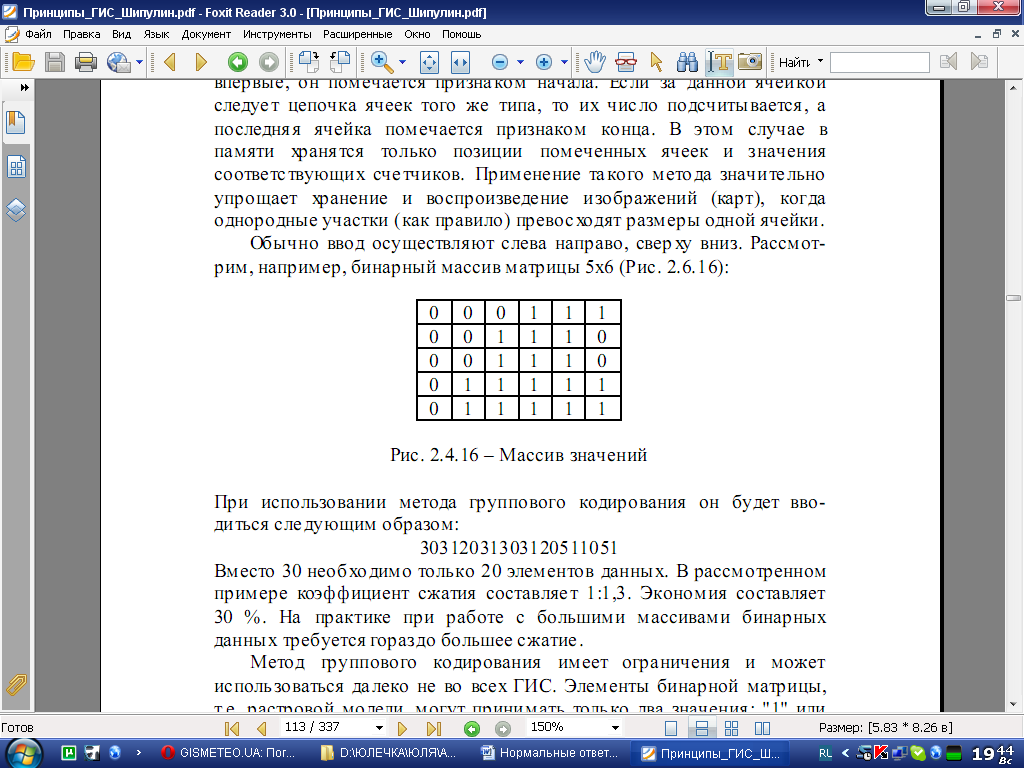
При использовании метода группового кодирования он будет вводиться следующим образом:
30312031303120511051
Вместо 30 необходимо только 20 элементов данных. В рассмотренном примере коэффициент сжатия составляет 1:1,3. Экономия составляет 30 %. На практике при работе с большими массивами бинарных данных требуется гораздо большее сжатие.
Метод группового кодирования имеет ограничения и может использоваться далеко не во всех ГИС. Элементы бинарной матрицы, т.е. растровой модели, могут принимать только два значения: "1" или "О". Эта матрица соответствует черно-белому изображению. На практике возможно полутоновое или цветное изображение. В э тих случаях значения в ячейках растровой модели могут различаться по типам. Тип значений в ячейках растра определяется как исходными данными, так и особенностями программных средств ГИС. В качестве значений растровых данных могут быть применены целые числа, действительные (десятичные) значения, буквенные значения.
Методы, основанные на порядке сканирования
Географические данные обычно автокоррелированны. Это означает, что соседние ячейки растровой модели имеют большую вероятность быть одинаковыми, чем разобщенные, а географические объекты образуют на растровом изображении пятна. Способ двунаправленного сканирования строк (способ Boustrophedon – по названию быка, вспахивающего поле) основан на изменении порядка кодирования: нечетные строки кодируются слева направо, а четные – в обратном направлении. Теперь при переходе к новой строке первая ячейка является смежной последней ячейке старой строки.
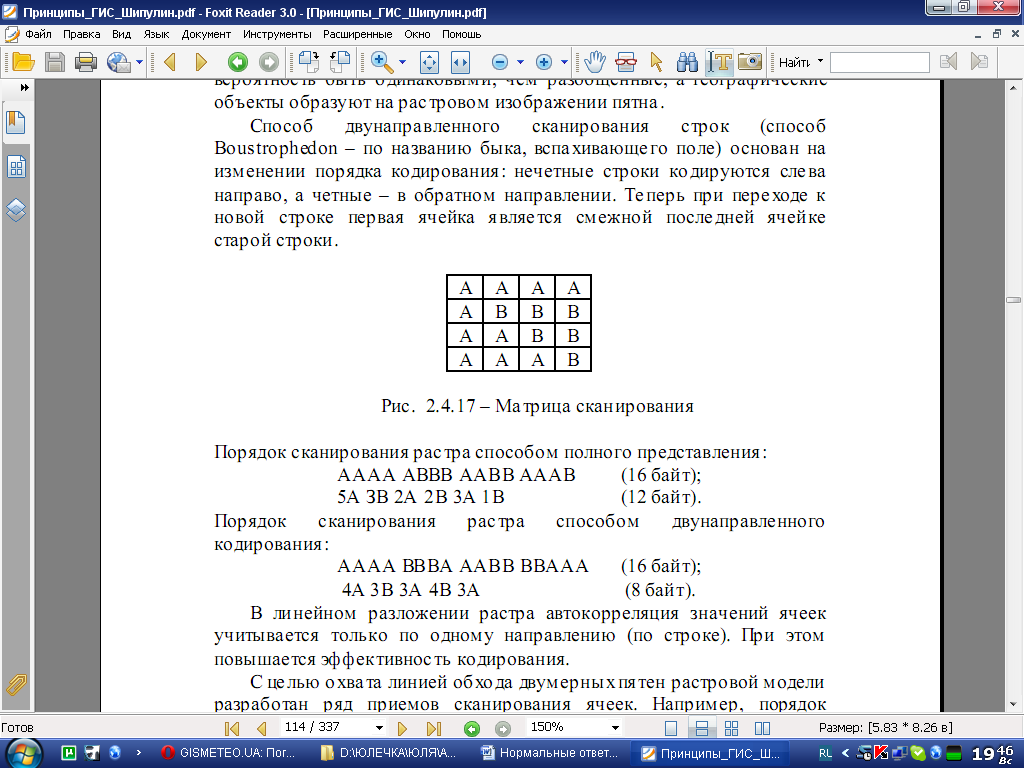
Порядок сканирования растра способом полного представления:
АААА АВВВ ААВВ АААВ (16 байт);
5А ЗВ 2А 2В 3А 1В (12 байт).
Порядок сканирования растра способом двунаправленного кодирования:
АААА ВВВА ААВВ ВВААА (16 байт);
4А 3В 3А 4В 3А (8 байт).
В линейном разложении растра автокорреляция значений ячеек учитывается только по одному направлению (по строке). При этом повышается эффективность кодирования.
С целью охвата линией обхода двумерных пятен растровой модели разработан ряд приемов сканирования ячеек. Например, порядок сканирования Мортона (Morton, впервые использовавшего этот способ в Canada GIS) основан на иерархическом разбиении карты. При сканировании растра по Мортону линия сканирования представляет собой фрактал (геометрическая фигура, части которой подобны ей самой). Недостатками этого порядка сканирования являются присутствие скачков между ячейками и возможность кодировать только растры размера, кратного двум. В порядке сканирования Пеано отсутствуют скачки между ячейками. Ломаная линия Дж. Пеано (1890) имеет базовый П-образный шаблон, который поворачивается от уровня к уровню так, чтобы обеспечить непрерывность линии сканирования.
Квадротомическое дерево
Квадротомическое представление (Quadtree) - один из способов представления пространственных объектов в виде иерархической древовидной структуры, основанный на декомпозиции пространства на квадратные участки, или квадратные блоки, квадранты (quarters, quads), каждый из которых делится рекурсивно на 4 вложенных до достижения некоторого уровня - числа Мортона (Morton order), обеспечивающего требуемую детальность описания объектов, эквивалентную разрешению растра [16].
Квадротомическое дерево обычно используется как средство снижения времени доступа, повышения эффективности обработки и компактности хранимых данных по сравнению с растровыми представлениями. Квадроструктура описывается иерархической системой вложенных квадратов.

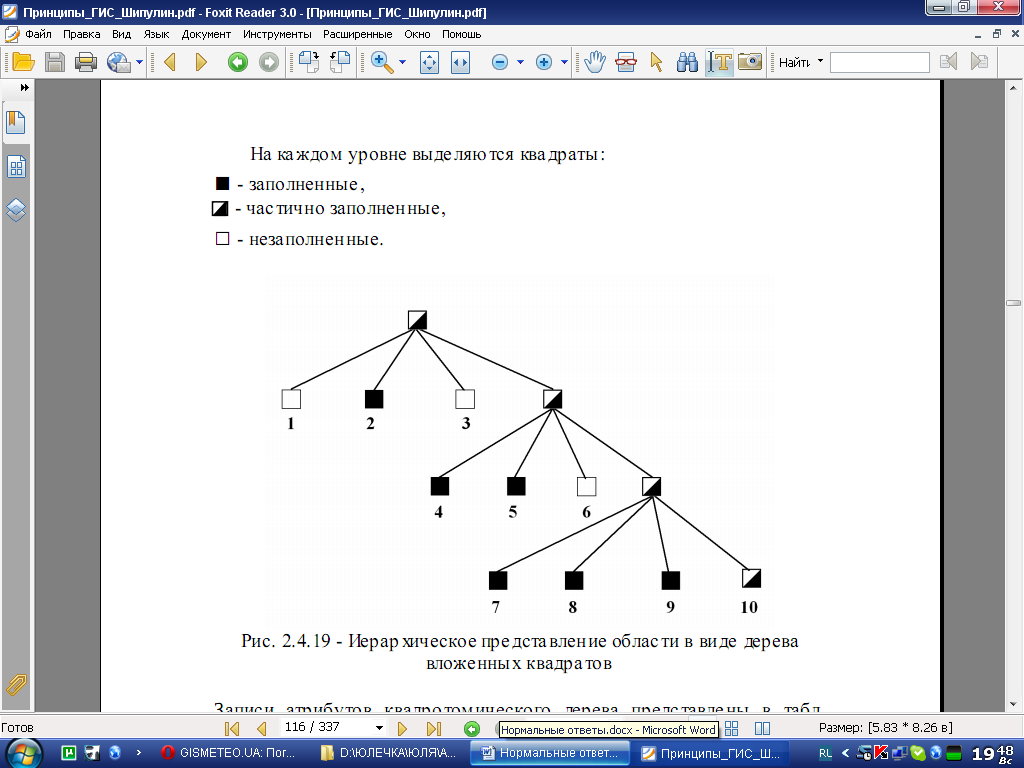
Записи атрибутов квадротомического дерева представлены в табл. 2.4.2.
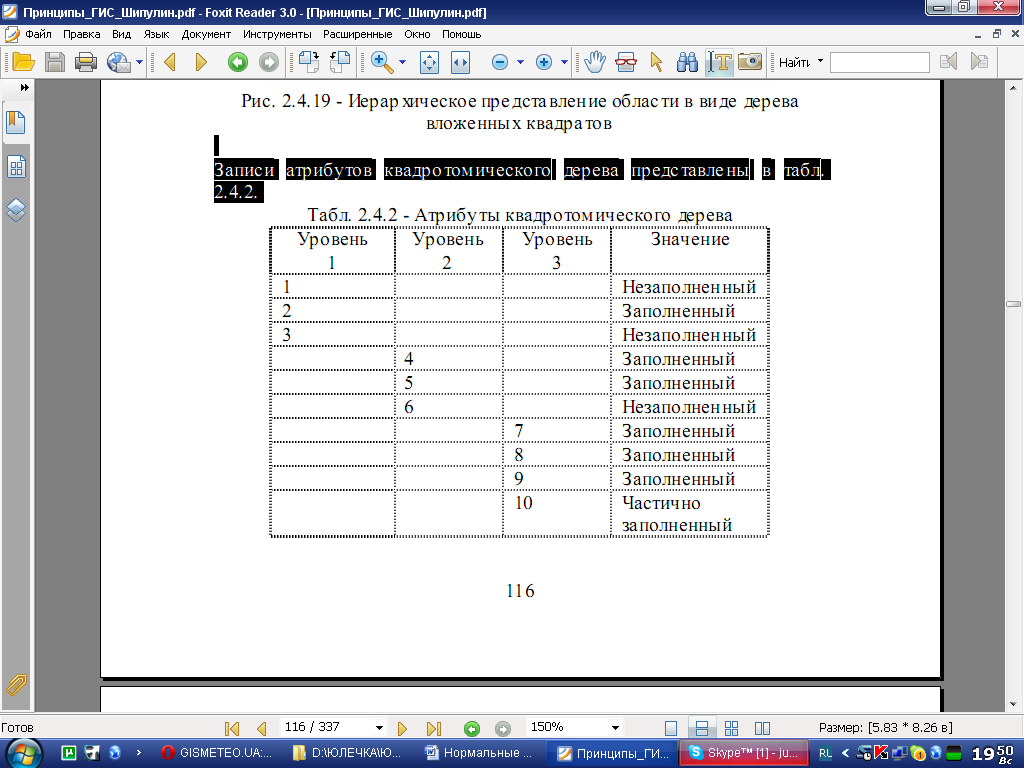
В этом примере коэффициент сжатия составляет 1:6,4 (10 записей вместо 64). Основное преимущество иерархической организации данных на квадродеревьях заключается в том, что она позволяет получать быстрые способы доступа к пространственным данным.