

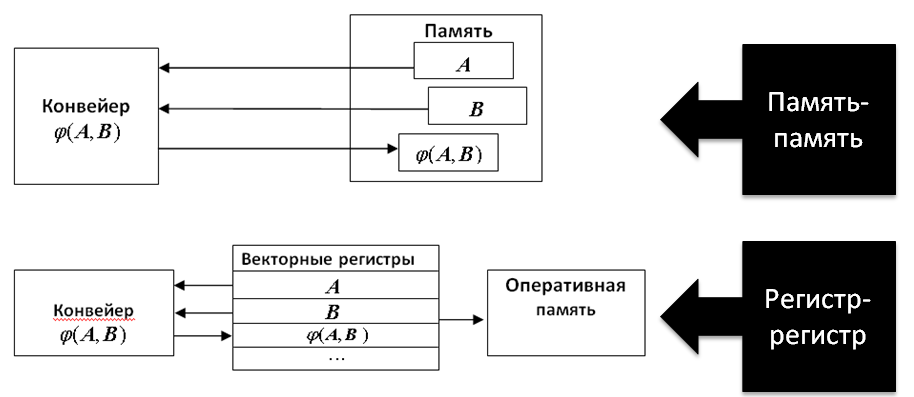
5. Структуры типа «память-память» и «регистр-регистр»
Принципиальное различие архитектур векторных процессоров проявляется в том, каким образом осуществляется доступ к операндам. При организации «память-память» элементы векторов поочередно извлекаются из памяти и сразу же направляются в функциональный блок. По мере обработки получающиеся элементы вектора результата сразу же заносятся в память. В архитектуре типа «регистр-регистр» операнды сначала загружаются в векторные регистры, каждый из которых может хранить сегмент вектора, например 64 элемента. Векторная операция реализуется путем извлечения операндов из векторных регистров и занесения результата в векторные регистры.
- Advanced Scientific Computer фирмы Texas Instruments Inc.
- Control Data Corporation (Star 100, Cyber 200)
Все эти вычислительные системы появились в середине 70-х прошлого века после длительного цикла разработки, но к середине 80-х годов от них отказались. Причиной послужило слишком большое время запуска - порядка 100 циклов процессора. Это означает, что операции с короткими векторами выполняются очень неэффективно, и даже при длине векторов в 100 элементов процессор достигал только половины потенциальной производительности.
В вычислительных системах типа «регистр-регистр» векторы имеют сравнительно небольшую длину (в ВС семейства Cray - 64), но время запуска значительно меньше чем в случае «память-память». Преимущество ВС с режимом «регистр-регистр» - эффективная обработка коротких векторов Недостаток: обработка длинных векторов (векторные регистры должны загружаться сегментами несколько раз). В настоящее время ВП типа «регистр-регистр» доминируют на компьютерном
Реализация систем типа «регистр-регистр»
- Cray Research Inc. Y-MP и С-90
- фирмы Fujitsu, Hitachi и NEC
Это вычислительные системы фирмы, в частности модели Y-MP и С-90. Аналогичный подход заложен в системы фирм Fujitsu, Hitachi и NEC. Время цикла в современных ВС варьируется от 2,5 нс (NEC SX-3) до 4,2 нс (Cray C90), а производительность, измеренная по тесту UNPACK, лежит в диапазоне от 1000 до 2000 MFLOPS (от 1 до 2 GFLOPS).
6. Обработка длинных векторов и матриц
Аппаратура векторных процессоров типа «регистр-регистр» ориентирована на обработку векторов, длина которых совпадает с длиной векторных регистров (ВР), поэтому обработка коротких векторов не вызывает проблем — достаточно записать фактическую длину вектора в регистр длины вектора.
Если размер векторов превышает емкость ВР, используется техника разбиения исходного вектора на сегменты одинаковой длины, совпадающей с емкостью векторных регистров (последний сегмент может быть короче), и последовательной обработки полученных сегментов. В английском языке этот прием называют strip-mining. Процесс разбиения обычно происходит на стадии компиляции, но в ряде ВП данная процедура производится по ходу вычислений с помощью аппаратных средств на основе информации, хранящейся в регистре максимальной длины вектора.
Ускорение вычислений
Для повышения скорости обработки векторов все функциональные блоки векторных процессоров строятся по конвейерной схеме, причем так, чтобы каждая ступень любого из конвейеров справлялась со своей операцией за один такт (число ступеней в разных функциональных блоках может быть различным). В некоторых векторных ВС, например Cray C90, этот подход несколько усовершенствован — конвейеры во всех функциональных блоках продублированы.
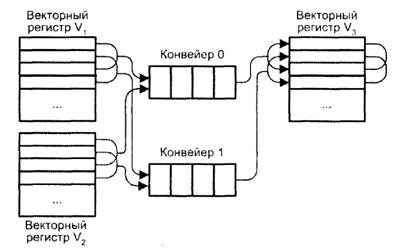
На конвейер 0 всегда подаются элементы векторов с четными номерами, а на конвейер 1 – с нечетными. В начальный момент на первую ступень конвейера 0 из ВР V1 и V2 поступают нулевые элементы векторов. Одновременно первые элементы векторов из этих регистров подаются на первую ступень конвейера 1. На следующем такте на конвейер 0 подаются вторые элементы из V1иV2, а на конвейер 2 - третьи элементы и т. д. Аналогично происходит распределение результатов в выходном векторном регистре V. В итоге функциональный блок при максимальной загрузке в каждом такте выдает не один результат, а два. Добавим, что в скалярных операциях работает только конвейер 0.
Интересной особенностью некоторых ВП типа «регистр-регистр», например ВС фирмы Cray Research Inc., является так называемое сцепление векторов (vector chaining или vector linking), когда ВР результата одной векторной операции используется в качестве входного регистра для последующей векторной операции. Для примера рассмотрим последовательность из двух векторных команд, предполагая, что длина векторов равна 64: V2=VoxV1, V4=V2+V3.
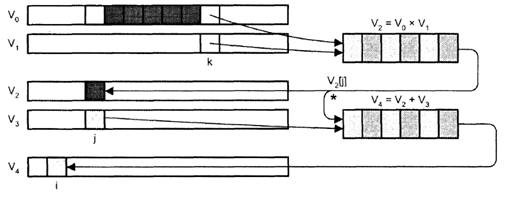
Результат первой команды служит операндом для второй. Напомним, что поскольку команды являются векторными, первая из них должна послать в конвейерный умножитель до 64 пар чисел. Примерно в середине выполнения команды складывается ситуация, когда несколько начальных элементов вектора V2 будут уже содержать недавно вычисленные произведения; часть элементов V2 все еще будет находиться в конвейере, а оставшиеся элементы операндов V0 и V1 еще остаются во входных векторных регистрах, ожидая загрузки в конвейер. Такая ситуация показана на рис., где элементы векторов V0 и V1, находящиеся в конвейерном умножителе, имеют темную закраску. В этот момент система извлекает элементы V0[k]и V1[k] с тем, чтобы направить их на первую ступень конвейера, в то время какV2[j] покидает конвейер. Сцепление векторов иллюстрирует линия, обозначенная звездочкой. Одновременно с занесением V2[j] в ВР этот элемент направляется и в конвейерный сумматор, куда также подается и элемент V3[j]. Как видно из рисунка, выполнение второй команды может начаться до завершения первой, и поскольку одновременно выполняются две команды, процессор формирует два результата за цикл (V4[i] и V2[j]) вместо одного. Без сцепления векторов пиковая производительность Сгау-1 была бы 80 MFLOPS (один полный конвейер производит результат каждые 12,5 не). При сцеплении трех конвейеров теоретический пик производительности - 240 MFLOPS. В принципе сцепление векторов можно реализовать и в векторных процессорах типа «память-память», но для этого необходимо повысить пропускную способность памяти. Без сцепления необходимы три «канала»: два для входных потоков операндов и один — для потока результата. При использовании сцепления требуется обеспечить пять каналов: три входных и два выходных.
Завершая обсуждение векторных и векторно-конвейерных ВС, следует отметить, что с середины 90-х годов прошлого века этот вид ВС стал уступать свои позиции другим более технологичным видам систем. Тем не менее одна из последних разработок корпорации NEC (2002 год) - вычислительная система «Модель Земли» (The Earth Simulator), - являющаяся на сегодняшний момент самой производительной вычислительной системой в классе, по сути представляет собой векторно-конвейерную ВС. Система включает в себя 640 вычислительных узлов по 8 векторных процессоров в каждом. Пиковая производительность суперкомпьютера превышает 40 TFLOPS.
7. STAR-100
Разработка конвейерной вычислительной системы STAR-100 (STAR – STring ARray computer – векторный компьютер) осуществлялась фирмой CDC с 1965 по 1973 гг. Система была анонсирована в 1970 г., а первая ее поставка была произведена в августе 1973 г. Быстродействие 108оп./с, стоимость – 15 млн. $.
Система STAR-100 создавалась под непосредственным влиянием языка программирования APL (A Programming Language). Язык APL (или АПЛ) – диалоговый язык программирования, характеризуется развитыми средствами работы с регулярными структурами данных (векторами, матрицами, массивами) и богатым набором базовых операций и компактностью записи.
Вычислительная система STAR-100 состояла из двух подсистем:
- первая осуществляла переработку данных,
- вторая – функции операционной системы.
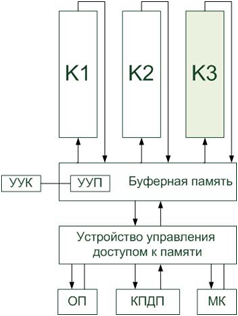
Ядром первой подсистемы являлся процессор, образуемый из нескольких конвейеров (в типовых конфигурацияx – 3 конвейера).
Особенности конвейеров
Конвейеры были специализированными: два из них (К1 и К2) служили для выполнения векторных операций, выполняли основной объем вычислений, а третий К3 – для реализации операций над скалярными операндами.
Конвейеры имели программируемую структуру (были с изменяемой конфигурацией), следовательно, в них можно было (на одном и том же множестве элементарных блоков обработки) выполнять различные арифметические операции. Однако до начала новой операции конвейер следовало перенастраивать (программировать на выполнение очередной операции).
В конвейерах К1 и К2 путем введения служебного булевского вектора была обеспечена избирательная обработка компонентов векторов-операндов. Единица в i-м разряде булевского вектора означала, что операция над i-ми компонентами соответствующей пары векторов производиться не будет.
В каждом конвейере была заложена возможность реализации операции сложения, а в двух из них К1 и К2 – операций умножения и деления. Состав элементарных блоков обработки информации конвейеров был выбран с учетом распределения вероятностей использования микроопераций различных типов.
Каждый конвейер К1, К2 и К3 мог включать в себя приблизительно 30 блоков обработки информации. Все блоки работали параллельно, но каждый из них оперировал с вполне определенными элементами векторов данных либо со своими скалярными операндами.
Любой конвейер воспринимал 64-разрядный код либо как один 64-разрядный операнд, либо как два 32-разрядных операнда. Время выполнения операции над парой операндов в любом из блоков конвейеров не превышало 40 нс. Следовательно, данные могли поступать в процессор (точнее, только в конвейеры К1 и К2) со скоростью 100 млн. операндов в секунду.
Система STAR-100 имела набор из 230 команд, из которых 65 команд предназначалось для работы с векторами данных и 130 команд – для работы со скалярами.
Средства управления подсистемой переработки данных были представлены композицией из устройства управления командами (УУК), устройства управления потоками (УУП) и устройства управления доступом к памяти (УУДП).
Оперативная память предназначалась для хранения программ и данных. Она была реализована на магнитных сердечниках и имела емкость 512 – 1024 К 64-разрядных слов, т.е. до 8 Мбайт. Память могла включать в себя до 32 модулей и относилась к классу памятей с перемежающимися адресами. Время цикла памяти было равно 1,28 мкс, однако допускались одновременные обращения к составляющим модулям.
Буферная память – следствие того, что быстродействие памяти было существенно ниже быстродействия процессора. Буферная память представляла собой совокупность регистров с временем цикла 40 нс. Назначение канала прямого доступа в память (КПДП) и мультиплексного канала (МК) следует из их названий и структуры связей между устройствами STAR-100.
Операционная система (ОС) STAR-100 относилась к классу распределенных. Ее функции, включая управление внешними запоминающими устройствами и устройствами ввода-вывода информации, реализовывались специальной вычислительной сетью из 9 мини-машин. Система программирования STAR-100 включала компиляторы с языков APL-STAR, COBOL и FORTRAN.
8. CRAY C-90
Наряду с фирмой CDC разработкой и производством конвейерных вычислительных систем занималась Cray Research Inc., которая была основана в 1972 г. главным конструктором систем CDC 6600 и 7600 Сеймором P. Креем (Seymour R. Cray, 1925 – 96). Однако конвейерные ВС фирмы Cray Research существенно отличались по архитектуре от систем STAR-100 и CYBER-203 и CYBER-205.
Архитектура первых систем Cray относилась к типу «регистр-регистр»: Cray-1, Cray X-MP, Cray Y-MP, Cray C90, Cray T90.
В этом ряду только первая модель, т.е. Cray-1, была однопроцессорной, а остальные члены ряда – мультипроцессорные ВС. Процессор в любой из этих систем ориентирован на реализацию векторных операций. Он по сути является мультиконвейером, т.е. представляется программируемой композицией из специализированных конвейеров.
Следует особо отметить, что в процессе разработок мультипроцессорных ВС фирма Cray Research сильно отошла от изначального архитектурного канона. Каждая очередная разработка была заметным эволюционным развитием архитектуры предшествующей системы, и в конце концов фирма Cray Research с диалектической неизбежностью встала на платформу распределенных вычислительных систем. Подтверждением сказанному служит семейство вычислительных систем с массовым параллелизмом или MPP-систем: Cray T3D, Cray T3E, Cray T3E-900, Cray T3E-1200, Cray T3E-1350
Особенности CRAY C90
- 16 процессоров, работающих над общей памятью;
- ОП с чередованием адресов, 4 порта доступа (по 2 слова за 1 такт каждый) для каждого процессора
- 3 типа каналов с разной скоростью передачи (Low-speed (LOSP) channels - 6 Mbytes/s, High-speed (HISP) channels - 200 Mbytes/s, Very high-speed (VHISP) channels - 1800 Mbytes/s)
- Секция межпроцессорного взаимодействия (Регистры, Семафоры)
- Вычислительная секция процессора
- Регистры
- A-регистры, B-регистры для адресов
- S-регистры, T-регистры для скаляров
- V-регистры для векторов
- Регистр длины вектора
- Регистр маски вектора
- Функциональные устройства
- Адресные
- Скалярные
- Векторные
- Для работы с плавающей точкой
- Параллельное выполнение программ
- Конвейеризация выполнения команд
- Независимость функциональных устройств
- Векторная обработка
- Зацепление функциональных устройств
- Многопроцессорная обработка
Пиковая производительность CRAY C90 (16 процессоров X2оп/такт (зацепление умножения и сложения) Х 2 рез./такт (сдвоенные конвейеры))/4 *10-9 оп/с (время такта)=16 Гфлопс
CRAY Y-MP C90
CRAY Y-MP - это векторно-конвейерный компьютер, объединяющий в максимальной конфигурации 16 процессоров, работающих над общей памятью. Время такта компьютера CRAY Y-MP C90 равно 4.1 нс, что соответствует тактовой частоте почти 250MHz.
Разделяемые ресурсы процессора
Оперативная память этого компьютера разделяется всеми процессорами и секцией ввода/вывода. Каждое слово состоит из 80-ти разрядов: 64 для хранения данных и 16 для коррекции ошибок. Для увеличения скорости выборки данных память разделена на множество банков, которые могут работать одновременно.
Каждый процессор имеет доступ к ОП через четыре порта с пропускной способностью два слова за один такт каждый, причем один из портов всегда связан с секций ввода/вывода и по крайней мере один из портов всегда выделен под операцию записи.
В максимальной конфигурации вся память разделена на 8 секций, каждая секция на 8 подсекций, каждая подсекция на 16 банков.
Секция ввода/вывода
Компьютер поддерживает три типа каналов, которые различаются скоростью передачи:
- Low-speed (LOSP) channels - 6 Mbytes/s
- High-speed (HISP) channels - 200 Mbytes/s
- Very high-speed (VHISP) channels - 1800 Mbytes/s
Секция межпроцессорного взаимодействия
Секция межпроцессорного взаимодействия содержит разделяемые регистры и семафоры, предназначенные для передачи данных и управляющей информации между процессорами. Регистры и семафоры разделены на одинаковые группы (кластеры), каждый кластер содержит 8 (32-разрядных) разделяемых адресных (SB) регистра, 8 (64-разрядных) разделяемых скалярных (ST) регистра и 32 однобитовых семафора.
Вычислительная секция процессора
Все процессоры имеют одинаковую вычислительную секцию, состоящую из регистров, функциональных устройств (ФУ) и сети коммуникаций. Регистры и ФУ могут хранить и обрабатывать три типа данных: адреса (A-регистры, B-регистры), скаляры (S-регистры, T-регистры) и вектора (V-регистры).
Регистры
Каждый процессор имеет три набора основных регистров (A, S, V), которые имеют связь как с памятью, так и с ФУ. Для регистров A и S существуют промежуточные наборы регистров B и T, играющие роль буферов для основных регистров.
Адресные регистры: A-регистры, 8 штук по 32 разряда, для хранения и вычисления адресов, индексации, указания величины сдвигов, числа итераций циклов и т.д. B-регистры, 64 штуки по 32 разряда.
Скалярные регистры: S-регистры, 8 штук по 64 разряда, для хранения аргументов и результатов скалярной арифметики, иногда содержат операнд для векторных команд. T-регистры, 64 штуки по 64 разряда. Скалярные регистры используются для выполнения как скалярных, так и векторных команд.
Векторные регистры: V-регистры, 8 штук на 128 64-разрядных слова каждый. Векторные регистры используются только для выполнения векторных команд.
Регистр длины вектора: 8 разрядов.
Регистр маски вектора: 128 разрядов.
Функциональные устройства
ФУ исполняют свой набор команд и могут работать одновременно друг с другом. Все ФУ конвейерные и делятся на четыре группы: адресные, скалярные, векторные и для работы с плавающей точкой.
Адресные ФУ (2): целочисленное сложение/вычитание, целочисленное умножение.
Скалярные ФУ (4): целочисленное сложение/вычитание, логические поразрядные операции, сдвиг, число единиц/число нулей до первой единицы.
Векторные ФУ (5-7): целочисленное сложение/вычитание, сдвиг, логические поразрядные операции (1-2), число единиц/число нулей до первой единицы (1-2), умножение битовых матриц (0-1). Предназначены для выполнения только векторных команд.
ФУ с плавающей точкой (3): сложение/вычитание, умножение, нахождение обратной величины. Предназначены для выполнения как векторных, так и скалярных команд.
Векторные ФУ и ФУ с плавающей точкой продублированы: векторные команды разбивают 128 элементов векторных регистров на четные и нечетные, обрабатываемые одновременно двумя конвейерами (pipe 0, pipe 1).
Когда завершается выполнение очередной пары операций результаты записываются на соответствующие четные и нечетные позиции выходного регистра. В полностью скалярных операциях, использующих ФУ с плавающей точкой, работает только один конвейер.
ФУ имеют различное число ступеней конвейера, но каждая ступень срабатывает за один такт, поэтому при полной загрузке все ФУ могут выдавать результат каждый такт.
Секция управления процессора
Команды выбираются из ОП блоками и заносятся в буфера команд, откуда они затем выбираются для исполнения. Если необходимой для исполнения команды нет в буферах команд, то происходит выборка очередного блока.
Команды имеют различный формат и могут занимать 1 пакет (16 разрядов), 2 пакета или 3 пакета (в одном слове 64 разряда, следовательно, в слове содержится 4 пакета). Максимальная длина программы на CRAY C90 равна 1 Гигаслову.
Параллельное выполнение программ
Конвейеризация выполнения команд
Все основные операции, выполняемые процессором: обращения в память, обработка команд и выполнение инструкций являются конвейерными.
Независимость функциональных устройств
Большинство ФУ в CRAY C90 являются независимыми, поэтому несколько операций могут выполняться одновременно. Для операции A=(B+C)*D*E порядок выполнения может быть следующим (все аргументы загружены в S регистры). Генерируются три инструкции: умножение D и E, сложение B и C и умножение результатов двух предыдущих операций. Первые две операции выполняются одновременно, затем третья.
Векторная обработка
Векторная обработка увеличивает скорость и эффективность обработки за счет того, что обработка целого набора (вектора) данных выполняется одной командой. Скорость выполнения операций в векторном режиме приблизительно в 10 раз выше скорости скалярной обработки. Для фрагмента типа
Do i = 1, n A(i) = B(i)+C(i) End Do
в скалярном режиме потребуется сгенерировать целую последовательность команд: прочитать элемент B(I), прочитать элемент C(I), выполнить сложение, записать результат в A(I), увеличить параметр цикла, проверить условие цикла. В векторном режиме этот фрагмент преобразуется в: загрузить порцию массива B, загрузить порцию массива C (эти две операции будут выполняться со сдвигом в один такт, т.е. практически одновременно), векторное сложение, запись порции массива в память, если размер массивов больше длины векторных регистров, то повторить эту последовательность некоторое число раз.
Перед тем, как векторная операция начнет выдавать результаты, проходит некоторое время (startup), связанное с заполнением конвейера и подкачкой аргументов. Чем больше длина векторов, тем менее заметным оказывается влияние данного начального промежутка времени на все время выполнения программы.
Векторные операции, использующие различные ФУ и регистры, могут выполняться параллельно.
Зацепление функциональных устройств
Архитектура CRAY C90 позволяет использовать регистр результатов векторной операции в качестве входного регистра для последующей векторной операции, т.е. выход сразу подается на вход. Это называется зацеплением векторных операций. Вообще говоря, глубина зацепления может быть любой, например, чтение векторов, выполнение операции сложения, выполнение операции умножения, запись векторов.
Многопроцессорная обработка: multiprogramming, multitasking
Пиковая производительность CRAY Y-MP C90
Пиковая производительность компьютера CRAY Y-MP C90 вычисляется так: функциональные устройства выдают два результата каждый такт (сдвоенные конвейеры), зацепление сложения и умножения дает четыре операции за такт, что составляет почти 1 Гфлопс (109опер/с). Если работают все 16 процессоров, то 16 Гфлопс.