

2.5.2 Ідентифікація по зображенню кровоносних судин на зворотному боці долоні
Ще один варіант застосування кисті руки в якості ідентифікатора - це використання малюнка кровоносних судин на зворотному боці долоні. Такий візерунок унікальний, його можна зчитувати на відстані і складно відтворити штучно.
Ця новітня технологія розпізнавання лежить в основі багатьох пристроїв ідентифікації. Особливість приладів полягає в тому, що вони сканують не поверхню пальця, а склад внутрішніх органів людини (структуру мережі кровоносних судин руки) за допомогою спеціального інфрачервоного датчика. У цьому випадку деформація поверхні, сухість, вологість або забрудненість рук ніяк не впливають на результати розпізнавання. Після сканування система розпізнавання обробляє отримане зображення. Такі пристрої можуть працювати як самостійно, так і в мережі під управлінням сервера.
Крім розглянутих пристроїв, існують такі, які використовують для ідентифікації людини малюнок вен, розташованих на тильній стороні кисті руки, стиснутої в кулак. Спостереження малюнка вен здійснюється телевізійною камерою за інфрачервоного підсвічування, після чого обчислюється шаблон.
Розпізнавання за голосом
Ідентифікація людини за голосом – один із традиційних способів розпізнавання, застосовуваний повсюдно. Можна легко довідатися співрозмовника по телефону, не бачачи його. Також можна визначити психологічний стан по емоційному фарбуванню голосу. Тому що голосова ідентифікація безконтактна й не жадає від людини особливих зусиль, ведуться роботи зі створення голосових замків і систем обмеження доступу до інформації. Інтерес у цій області зв'язаний ще й із прогнозами повсюдного впровадження голосових інтерфейсів.
На сьогоднішній день існує два підходи до ідентифікації людини по голосі, побудовані на обліку структури мовного сигналу, рис 1.13.
Кожний сплеск голосового сигналу відповідає деякому фрагменту мови. Це може бути одна буква, сполучення букв (фонема) або коротке слово (те саме слово із трьох букв сюди не ставиться). Усього в російської мови є 42 фонеми, але підходять для ідентифікації людини не все. Частина фонем огласовані. Саме їм властивий індивідуальний характер. Це звуки "э", "об", "л", "а", "і" та інші. Інша частина фонем - шиплячі (шумоподібні). Це "ц", "ч", "ш", "щ" і т.д. Вони не є індивідуальними і їхнє використання при ідентифікації може привести до зниження якості розпізнавання. На малюнку вище синім цвітом відзначена огласована фонема, а червоним - шумоподібна.
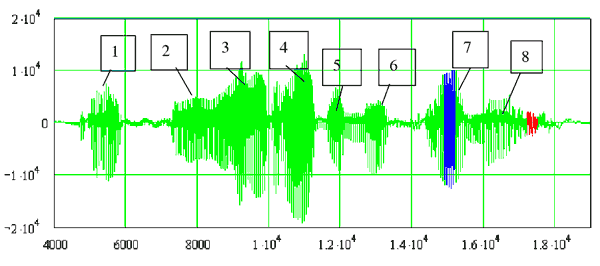
Рисунок 1.13 – Приклад голосової фрази й виділення з її 8 фрагментів
Огласовані фрагменти мови мають явно виражений періодичний характер, представлені на рис. 1.14. Період і характер коливань індивідуальні. Це добре видно на графіку:
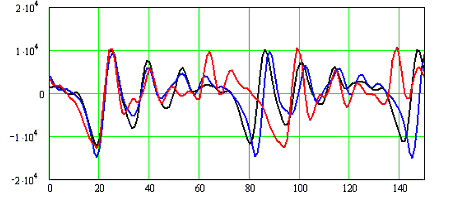
Рисунок 1.14 - Графік коливання фонем
Чорною й синьою лініями позначені коливання однієї фонеми для однієї людини. Червоний цвітом позначена фонема від іншої людини. Для однієї людини графіки дуже схожі. В іншої людини й період тону й форма внутрішніх коливань значно відрізняються.
Перший підхід. Індивідуальні розходження розподілу потужності сигналу по спектрі покладені в основу першої категорії систем біометричної ідентифікації по голосі. Вони будуються на базі гребінки вузькополосних фільтрів, що виділяють із голосу коливання різних частот. На підставі вихідних даних можна побудувати графік (амплітудно-частотну характеристику).Смуги пропущення фільтрів вибираються при проектуванні системи, але вони не повинні бути занадто вузькими, щоб не залежати від варіацій частотного спектра голосу. У той же час, вони не повинні бути й дуже широкими. Потрібно підбирати оптимальну ширину, достатню для впевненої ідентифікації. Звичайно використовують 16 фільтрів, які розширюються в міру росту значень виділюваних частот. Це пов'язане з нестабільністю високих частот по енергії (у порівнянні з низькими частотами). Системи спектрального аналізу голосу навчаються, запам'ятовуючи розподіл енергій із частотою порядку 35 мілісекунд. У підсумку виходить великий масив даних, що відповідає фразі. Дані знімаються із частотою 16кГц і в 16 розрядів (це пов'язане з особливостями фільтрів). Після чого вони пропускаються через фільтри. Підсумковий масив даних виходить дуже маленького розміру (потрібно записати тільки 16 координат вершин по одній осі). Для ідентифікації можна використовувати як статистичні методи, так і нейронну мережу, що не повинне впливати на результат розпізнавання.
Другий підхід – використання апарата лінійного пророкування. Огласовані коливання звуку імітують періодичними ударами по деякій коливальній ланці (дзвону). Період ударів повинен точно відповідати періоду основного тону голосу. Динамічні характеристики дзвона повинні мінятися, щоб одержати форму, близьку до голосової фрази. Зрозуміло, що як дзвін використовується цифровий коливальний фільтра, а не реальний аналог. Число коефіцієнтів фільтра коливається від 10 до 12 (а1,..., а12). Цього досить для якісного відтворення мови зі збереженням індивідуальних особливостей. Коефіцієнти лінійного провісника обчислюються на вибірці з 180-220 відліків ("ударів"). Обчислення параметрів провісника (цифрового фільтра) знаходять рішенням системи з 10...12 лінійних рівнянь. Для того, щоб понизити обчислювальне навантаження частоту дискретизації знижують до 8 кГц. При імітації огласованих звуків на вхід цифрового фільтра подають періодичну послідовність імпульсів, змодульовану по амплітуді. У такому випадку на виході фільтра з'являються періодичні перехідні процеси, що повторюють звук, який моделюється. При моделюванні шиплячих на вхід фільтра подають випадковий шум потрібної амплітуди. При навчанні системи, на її вхід подають кілька зразків голосу користувача. Вони перетворяться в послідовність імпульсів основного тону й відповідну послідовність коефіцієнтів лінійного провісника. Виходить масив даних, що описує індивідуальні особливості голосу людини для даної фрази. Цей масив з коефіцієнтів і є тим біометричним еталоном, що записується в базу даних.
Характеристика обох методів. Помилки першого роду (недопуск свого) складають 1-5% (хоча, залежно від реалізації програмного забезпечення, можуть доходити до 40% - перевірено досвідченим шляхом). Кількість помилок другого роду (пропуск чужого) залежить від того, чи знає зловмисник ключову фразу (до 1%, якщо голоси близькі) чи ні (0,00000001%). Голосовий захист просто пройти, якщо перехоплено або записана ключова фраза. Тому розроблювачі зараз намагаються створити систему, захищену від перехоплення. Зараз можна використовувати голосову идентифікацію разом з іншими видами захисту. Наприклад, по геометрії особи. Тоді можна відслідковувати рух губ і синхронізацію їх зі звуком. Або якось інакше.
Наведемо наступні переваги та недоліки цих систем:
Переваги:
Звичний для людини спосіб ідентифікації.
Низька вартість (найнижча серед всіх біометричних методів).
Безконтактність.
Недоліки:
Високий рівень помилок 1 і 2 роди.
Необхідність у спеціальному шумоізольованому приміщенні для проходження ідентифікації.
Можливість перехоплення фрази "магнітофоном".
Якість розпізнавання залежить від багатьох факторів (інтонація, швидкість проголошення, психологічний стан, хвороби горла).
Необхідність підбора спеціальних фраз