

4.6.3. Класифікація в гіс при використанні карт
При нанесенні на карту кількісних показників з метою виявлення закономірностей розподілу об’єктів, явищ, завжди існує проблема вибору між представленням точних значень даних або узагальнення зазначених значень по площі. Зазвичай, зазначене число, кількість і відношення групуються в класи, тому що кожний об’єкт, як правило, має різні значення. Це особливо важливо враховувати, якщо діапазон значень великий. Якщо кожне значення представлено на карті унікальним символом, і обране відображення точних значень об’єктів на карті, то оцінити ситуацію можна лише при невеликій кількості значень.
Класи дозволяють об’єднати об’єкти з подібними значеннями, приписуючи їм однаковий символ. Це дозволяє побачити розподіл об’єктів з подібними значеннями. Призначення діапазону класу, вкаже які об’єкти до якого класу будуть віднесені, що в свою чергу, буде визначати обличчя карти. Змінюючи класи, при однакових вихідних даних, можна створювати самі різноманітні карти. Відмінність значень між об’єктами різних класів, як правило, виконується максимальним, щоб забезпечити достатній контраст відображення і попадання об’єктів з подібними значеннями в один клас.
Створювати класи можна вручну або використовувати стандартну схему класифікації.
Призначення класів вручну. Як у векторних, так і в растрових системах, технологія класифікації об'єктів передбачає перекодування атрибутів в атрибутивних таблицях для створення нових покриттів. У цьому простому процесі класифікація спрямована на перейменування об'єктів на основі значень атрибутів, не змінюючи їх розташування.
Необхідність ручної класифікації виникає тоді, коли необхідно згрупувати об'єкти, що відповідають специфічним критеріям або порівняти значення їх атрибутів з конкретною характерною величиною. Визначається верхня й нижня межа інтервалу для кожного класу, і приписується власний символ.
Верхня чи нижня межа інтервалу класу може визначати деяке явище. Наприклад, у разі необхідності позначення міської зони бідності, потрібно відобразити райони, у яких не менш 35 % населення живе нижче рівня бідності. У цьому випадку один клас визначив би на карті 35-відсоткову зону. Було б логічно призначити наступний інтервал для 50 %, показавши, :у яких районах не менше половини населення живе за межею рівня бідності.
Класи можуть також ґрунтуватися на прийнятих стандартах або результатах досліджень у будь-якій галузі господарства чи промисловості. Наприклад, біологи, створюючи заповідник, виключили б території річкових басейнів, покритих лісом менше ніж на 50 %, але виділили б ті, лісове покриття яких перевищує 85 %. У цьому випадку класи визначилися б як: „менше 50%”, „51 - 85 %”, і „більше 85 %”.
Можна також створювати класи, використовуючи узагальнюючі характеристики об'єктів. Припустимо, необхідно нанести на карту області середню для кожного району кількість людей, зайнятих у сільському господарстві. Можна було б підібрати класи так, щоб один з них був обмежений середнім значенням даного параметра по всій країні. У цьому випадку, карта б добре відображала відхилення локального показника від середнього по країні.
Треба відзначити, що зміна кодів атрибутів у ході ручної класифікації, - процес досить прямолінійний, він може створювати деякі проблеми, головним чином внаслідок порядку, у якому змінюються числа. Особливо актуально це для растрових відображень безперервних явищ, коли кожному пікселю може відповідати тільки одне значення, або в простих векторних системах, котрі допускають класифікацію вже існуючого поля класів в атрибутивній таблиці.
Припустимо, наприклад, що об'єкти покриття з кодами атрибутів від 1 до 5 відповідають типам рослинності. Нехай класи 1,3 і 5 – лісові різновиди, а 2 і 4 - лугові. Потрібно створити карту тільки з двома категоріями: ліс (код 1) і луг (код 2).
У варіанті 1 (табл. 6.1) спочатку замінюємо класи 1, 3 і 5 на 1 (крок 1), а потім 2 і 4 - на 2 (крок 2). Змінивши легенду, отримуємо карту з лісами (1) і лугами (2).
Таблиця 6.1.
Вихідні |
Варіант 1 |
Варіант 2 |
||
Крок 1 |
Крок 2 |
Крок 1 |
Крок 2 |
|
4 |
4 |
2 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
5 |
1 |
1 |
5 |
2 |
1 |
1 |
1 |
1 |
1 |
2 |
2 |
2 |
1 |
1 |
5 |
1 |
1 |
5 |
2 |
4 |
4 |
2 |
1 |
І |
1 |
і |
1 |
1 |
1 |
Тепер подивимося, що відбудеться, якщо новий клас „1” призначимо спочатку луговим елементам (варіант 2). У цьому випадку на першому кроці класи 2 і 4 одержать значення „1”, і об'єкти знову утвореного класу „1” зіллються з об'єктами, що мали клас „1” раніше. Таким чином, подальша класифікація стає помилковою. Щоб уникнути подібних ситуацій, треба знати декілька корисних правил.
По-перше, нові коди атрибутів не повинні зберігатися в одному покритті з вихідними. У крайньому випадку винесіть результати класифікації в окремий стовпчик атрибутивної таблиці.
По-друге, завжди стежте, яким чином перенумерація впливає на результат. Якщо виникають сумніви щодо порядку перенумерації, спробуйте виконати процес у зворотному порядку.
У ГІС з розвиненим аналітичним апаратом (ArcInfo, ArcView, System-9) функція класифікації зазвичай побудована таким чином, що нові класи призначаються обов'язково в новому полі атрибутивної таблиці, а при роботі з растровими даними класифікація призводить до створення нового покриття. Ці заходи виключають вплив порядку призначення класів на результат.
Використання стандартних схем класифікації. Зазвичай, коли метою класифікації даних є виявлення закономірностей просторового розподілу, використовуються стандартні схеми розбивки даних на інтервали. Стандартні схеми угруповань даних у класи, враховують характер розподілу вашої вибірки. Необхідно визначити схему класифікації й кількість класів, а верхню й нижню межу для кожного класу обчислить ГІС. Оптимальний вибір інтервалу розбивки, а також вірне визначення кількості класів допомагає зробити об'єктивний аналіз розподілу даних.
Найбільш використовуваними в ГІС стандартними схемами класифікації є:
[ природна розбивка;
[ квантіль;
[ рівні інтервали;
[ стандартне (середньоквадратичне) відхилення.
Розглянемо кожний з них докладніше, використовуючи для ілюстрацій зіставлення гістограм розподілу з результуючою картою. У даних прикладах, гістограми і карти використовують одні й ті самі дані. Гістограма - зручний і популярний інструмент оцінки характеру розподілу, часто використовуваний у статистичних методах аналізу. Зазвичай, на горизонтальну вісь гістограми виносяться значення, а на вертикальну - частота їхньої появи в межах даної вибірки. Тонові області, що відповідають відтінкам класів на карті, показують діапазон для кожної схеми розбивки; значення інтервалів класу позначені на горизонтальній осі. Ширина кожної області показує, скільки районів належать до кожного класу. Зверніть увагу, як змінюється вигляд карти й закономірності розподілу одних і тих самих даних залежно від застосовуваної методики класифікації.
Природна розбивка. Природна розбивка утворює угруповання таким чином, що в середину класу потрапляють близькі між собою значення, а між класами існує істотна різниця. Межі класів визначаються там, де є різкий перепад між групами значень.
У цьому випадку, ГІС автоматично визначає максимальне й мінімальні значення для кожного класу; використовуючи математичну процедуру, котра аналізує різкі зміни в даних. Ця процедура вибирає інтервали, котрі найкраще групують близькі значення, і максимізує відмінності між класами.
Переваги методу. Даний підхід є найбільш ефективним при картуванні даних, які мають нерівномірний розподіл, тому що природна розбивка поміщає розкидані по карті близькі значення в один клас.
Недоліки методу. Труднощі зіставлення класів на різних картах, оскільки інтервали розбивки характерні тільки для даної вибірки. Однак дану проблему можна розв'язати шляхом використання для різних карт єдиної легенди, складеної методом природної розбивки на найбільш характерній вибірці.
Крім того, використання даного методу не рекомендується у випадку рівномірного розподілу даних, коли різкі зміни в значеннях погано розпізнаються.
На рисунку 6.3 проілюстровано дію методу природної розбивки при аналізі кількості населення та їх доходів по кварталам міста.
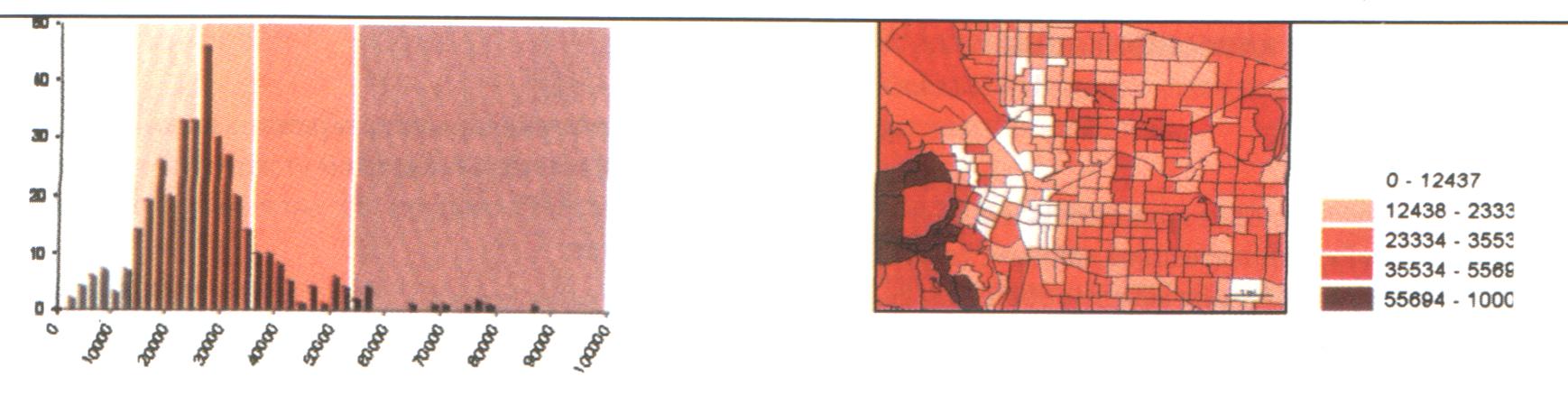
Рис. 6.3. Гістограма розподілу і результуюча карта після виконаний природної розбивки
Класи основані на природному угрупованні значень даних. На гістограмі розбивку класу зроблено відповідно до різких стрибків у значеннях, позначених великим розривом між стовпцями, так що райони, які мають близькі значення, містяться в одному класі. Результуюча карта підкреслює розбіжності між районами з різною кількістю населення.
Квантіль. Квантілі мають рівну кількість об'єктів у кожному класі. ГІС впорядковує об'єкти за принципом зміни їхнього атрибута в інтервалі від максимального до мінімального значення й підсумовує їхню кількість. Потім ділить загальну кількість об'єктів на задане число класів, щоб отримати кількість об'єктів у кожному класі. Після цього присвоює першим по порядку об'єктам значення найнижчого класу, поки цей клас не буде заповнений, потім переміщається до наступного класу, заповнює його тощо.
До переваг методу можна віднести:
P наочне зіставлення областей, розміри яких приблизно рівні;
P можливість ефективного відображення на карті об'єктів, значення яких розподілені рівномірно;
P можливість оцінити відносне положення об'єкта серед об'єктів оточення, наприклад, можна показати, які області в державі мають найбільший прибуток (входять до складу 20-відсоткової групи з найвищим значенням середнього прибутку).
Необхідно пам’ятати, що при розбивці на квантілі, об’єкти з близькими значеннями можуть потрапити у різні класи, особливо, якщо значення розташовані щільно. Це може призвести до необґрунтованого їх розподілу, і навпаки - декілька далеко рознесених суміжних значень, можуть виявитися в одному класі, приховуючи відмінності між об’єктами.
Класифікація за допомогою квантілів може також змінювати реальні закономірності розподілу, якщо області мають істотну різницю в розмірах. Оскільки, як зазначалося, кожен клас містить рівну кількість об'єктів, на гістограмі заштриховано площі, що утворюють один клас і зазначено інтервали класу, де вони перетинають горизонтальну вісь. На карті (рис. 6.4) райони з подібними значеннями поміщено в суміжні класи, а райони з високими значеннями з’єднано в один клас.

Рис. 6.4. Гістограма розподілу об'єктів і результуюча карта після розбивки на квантілі
Рівні інтервали. У даному випадку, кожен клас має рівний діапазон значень, тому різниця між максимальним і мінімальним значенням однакова для кожного класу. ГІС віднімає мінімальне значення в наборі даних від максимального. Отримане значення ділиться на задану кількість класів. Граничне значення для першого класу отримується шляхом додавання результату ділення до найменшого значення вибірки. У такий спосіб встановлюються інтервали для іншої частини класів.
Метод дуже зручний для представлення інформації нетехнічній аудиторії. Рівні інтервали більш прості для розуміння, тому що діапазон для кожного класу однаковий. Ще краще, якщо одиниці виміру подам даних відомі глядачам (наприклад, відсотки).
Ефективність методу істотно знижується при оцінці нерівномірних розподілів, коли припускається можливість скупчення великої кількості об’єктів в одному чи двох класах при повній їхній відсутності в інших. На рис. 6.5 показано, як змінюється картина розподілу при рівномірній розбивці.
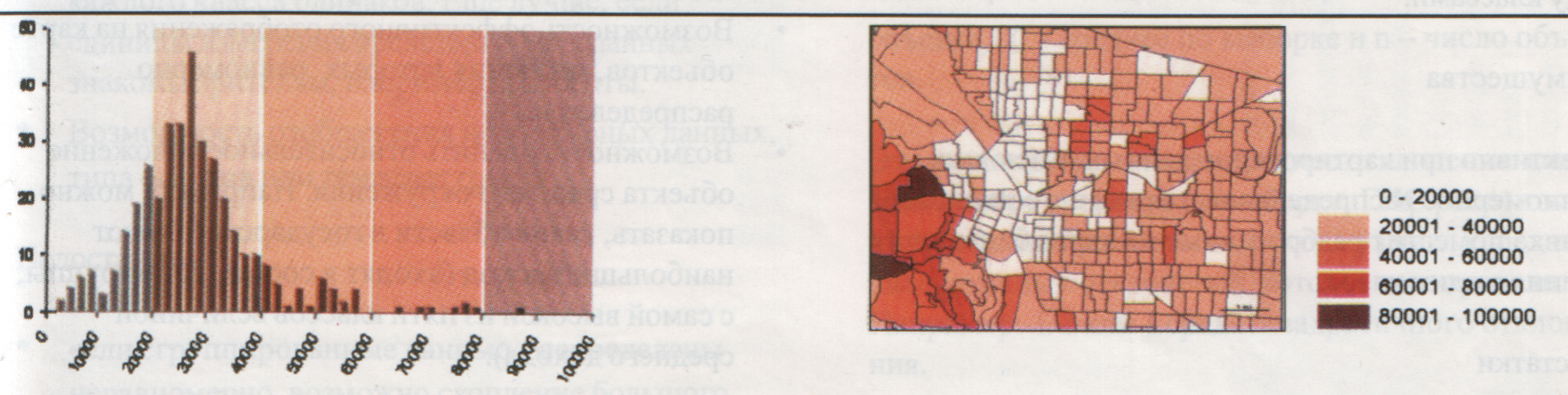
Рис. 6.5. Гістограма розподілу об'єктів і результуюча карта після розбивки на рівні інтервали
Різниця між максимальними й мінімальними значеннями у цьому випадку, однакова для кожного класу, тому на карті, наведеній нижче, майже всі райони містяться у трьох найнижчих класах. Таким чином, дана карта підкреслює наявність невеликої кількості районів з найбільшою кількістю населення.
Стандартне відхилення. У даному випадку, кожен клас визначається величиною відхилення від середнього у вибірці. ГІС спочатку знаходить середнє значення у вибірці, поділивши суму всіх значень на загальну кількість об'єктів. Після цього обчислюється середньоквадратичне відхилення, шляхом віднімання середнього значення від кожного значення й піднесення отриманої різниці в квадрат (щоб забезпечити позитивне значення). Отримані значення підсумовуються й діляться на кількість об'єктів. По закінченні з отриманого результату розраховується корінь. Формула виглядає таким чином:
![]()
де s - середньоквадратичне
відхилення, х - значення об'єкта,
![]() середнє за вибіркою, п - кількість
об'єктів.
середнє за вибіркою, п - кількість
об'єктів.
Такий підхід дає можливість уявити напрямок відхилення параметра об'єкта від середнього значення у більший чи менший бік, а також звернути увагу на дані, що мають у загальній масі невелике відхилення від середнього (логарифмічно нормальний чи нормальний розподіл). При цьому потрібно пам’ятати, що карта, отримана в результаті класифікації за середньоквадратичним відхиленням, ніколи не виявить реальні характеристики об'єкти. Її призначення - виявити тільки відхилення від середнього.
Подивимося на ілюстрацію (рис. 6.6).
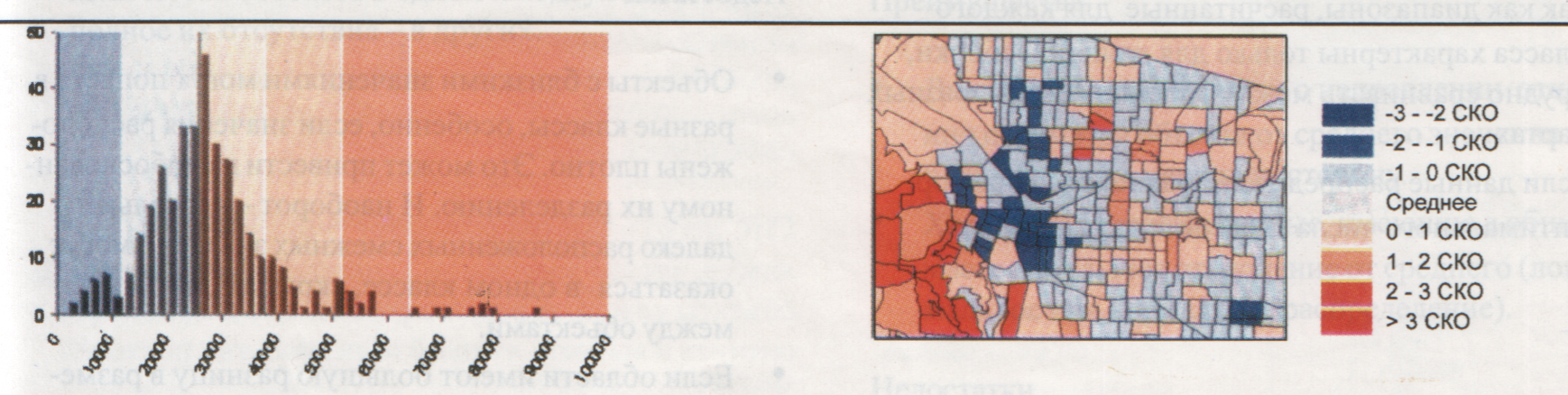
Рис. 6.6. Гістограма розподілу об'єктів і результуюча карта після розбивки за середньоквадратичним відхиленням
Об'єкти розбито на класи за значенням відхилення від середнього. ГІС обчислює середнє і стандартне відхилення. Потім послідовно додає середньоквадратичне відхилення до середнього чи віднімає його від середнього, щоб визначити інтервали класу. Карта показує, наскільки відрізняються значення об'єктів від середнього.
4.6.4. Практичне застосування принципів класифікації
Вибір схеми. Перш ніж вибирати схему класифікації, необхідно з'ясувати характер розподілу даних. Треба побудувати гістограму й відрегулювати шкалу її горизонтальної осі так, щоб уникнути порожніх інтервалів. Вертикальна вісь має показувати кількість об'єктів, що потрапляють у межі кожного інтервалу.
Більшість електронних таблиць створюють гістограми аналогічно програмам статистичної обробки аналітичних ГІС типу ArcInfo або Arc View.
З’ясувавши характер розподілу, можна використовувати наступні принципи для вибору методу класифікації:
1. Якщо дані розподілені нерівномірно (багато об'єктів мають однакові чи близькі значення й помітні перепади між значеннями груп), то доцільно використовувати природну розбивку.
2. Якщо дані розподілені рівномірно й необхідно підкреслити різницю між об'єктами, то доцільно використовувати рівні інтервали чи середньоквадратичне відхилення.
3. Якщо дані розподілені рівномірно, а показати необхідно відносні розбіжності між об'єктами, то доцільно використовувати квантілі.
ГІС легко і швидко дозволяє змінювати діапазони класу, кількість класів і вигляд символів, що відображають об’єкти класу. Це дає можливість візуально оцінити й вибрати кращий з декількох підходів, що надзвичайно зручно, коли оцінюється нова вибірка чи окреслюються можливі закономірності розподілу.
Визначення кількості класів. Якщо визначено схему класифікації, то необхідно виявити кількість створюваних класів. Ґрунтуючись на цій кількості і схемі класифікації, ГІС обчислює діапазони класів. Якщо вибрано оптимальну схему класифікації, то поява додаткової інформації не змінить кількість класів, а лише зробить закономірності більш помітними.
Проте потрібно пам'ятати, що більшість користувачів може розрізняти на карті до семи кольорів, тому використання більше семи класів робить важким пошук об'єктів із близькими значеннями. Зазвичай, чотирьох чи п'яти класів цілком достатньо, щоб відобразити основні закономірності розподілу даних. Використання кількості класів менше трьох-чотирьох, може призвести до втрати багатьох взаємозв'язків між об'єктами, а отже і ряду закономірностей. Однак, якщо вивчаються нові дані з метою визначення типу угруповання чи об'єктів, виявлення закономірності їхнього розподілу, то кількість класів можна збільшити. Тоді діапазон кожного класу буде вужчий, а значення об'єктів, що потрапили в нього, ближчими до своєї реальної величини.
Оптимізація розбивки. Щоб спростити і прискорити процес сприйняття карти, необхідно коректувати діапазони розбивки в сторону спрощення класів.
Якщо не ставити за мету нанесення на карту точних значень даних, то за допомогою округлення мінімальних і максимальних значень можна отримати більш легку для зчитування легенду без втрати помітних на карті закономірностей.
Деякі ГІС при розбивці класів автоматично створюють безперервні діапазони, у яких максимальне значення кожного класу є мінімальним для наступного більш високого класу. В дійсності, найнижча фактична величина даних для більш високого класу може бути значно вище мінімального значення класу, показаного в легенді. Тому, використовуючи можливості ГІС, необхідно визначити класи, а потім, змінити найменше значення для кожного класу, відповідно до найменшого значення об'єктів. При незмінності закономірності на карті, легенда краще відобразить діапазони реальних значень. Це особливо ефективно, якщо використовується класифікація за допомогою природної розбивки. Однак, не варто цього робити, якщо застосовується метод рівних інтервалів, тому що отримувані з його допомогою діапазони безперервні за визначенням.
Можна перейменовувати класи в легенді подібно до упорядкованих величин типу „дуже високо”, „високо”, „середнє”, „низько” чи „немає даних”. Це може зробити карту більш легкою для сприйняття і доцільно у тих випадках, коли відносні величини більш важливі, ніж реальні значення. Особливо цей прийом допомагає при роботі з великою кількістю даних. Наприклад, при визначенні кількості аптек на 1000 осіб для кожного досліджуваного району можна отримати числа з дробовою частиною, що в даному випадку безглуздо, оскільки важливо тільки зіставити райони між собою. Щоб зробити карту більш зрозумілою і наочною, можна змінити отримані числові значення на визначення типу „високий”, „середній” і „низький”.
Чимало неприємностей може завдати і проблема аномальних значень. Занадто високі або занадто низькі значення, можуть настільки змінити значення середнього, що більшість об'єктів виявиться в одному класі. Змінюючи діапазони класів, аномальні значення можуть змінити і досліджувані закономірності. Це особливо помітно при використанні схеми розбивки на рівні інтервали або по середньоквадратичному відхиленню, коли всі значення, за винятком аномального, можуть потрапити в один клас. Використання природної розбивки може ізолювати аномальні значення в найвищому або найнижчому класі, але це все таки відіб'ється на інших класах.
Потрібно розглянути аномальні значення уважніше. Вони можуть бути результатом помилки в базі даних або випадковою для даної вибірки величиною, проте можуть виявитись і цілком об'єктивною інформацією. Багато що залежить і від постановки завдання. Наприклад, як враховувати при аналізі аномалії свинцю, причиною якої є звалище старих акумуляторів? Геолог, що досліджує природний геохімічний фон, неодмінно виключить ці дані з вибірки, оскільки вони заважають виявленню природних закономірностей. А от дослідник, що веде аналіз екологічного ризику для населення, швидше за все залишить їх як один з найважливіших факторів, що впливає на здоров'я людей.
Отже, якщо аномалії - це не помилки у базі даних, які можна виправити, то потрібно вибрати один із варіантів обробки такого роду значень залежно від того, як вони впливають на інші дані й на закономірності просторових розподілів на карті. Відомо декілька традиційних методів боротьби з небажаним впливом аномалій на результат класифікації. Наведемо деякі з них:
¡ якщо аномальні значення істотно розкидані, можна розмістити кожне з них у власному класі;
¡ якщо група аномальних значень локалізована в одному місці, можна згрупувати їх разом в один клас;
¡ можна також згрупувати їх з сусіднім верхнім чи нижнім класом, якщо вони розташовані також недалеко від інших значень у цьому класі;
¡ якщо відомо, що аномальні значення безпідставні, то їх можна замаскувати сірим кольором або замаркувати поле як „Недостатньо даних” у легенді.
Аномальні значення можуть виникати і в результаті обчислення відносних значень. Незважаючи на те, що вихідні значення були нормальними, результат їх ділення може уводити в оману. Це може спричинюватися невірним засобом збереження об'єктів у базі даних чи організацією взаємозв'язків між значеннями на карті. Припустимо, на карту наноситься кількість продуктових магазинів у кожному районі на 1000 осіб. Якщо ці торгові точки розташовані в районі, де живе небагато людей (промисловий район), то розрахунок кількості продуктових магазинів на 1000 осіб у цьому випадку призведе до сильно завищеного значення, спотворюючи класи й затінюючи справжні закономірності у розподілі даних.
Розчинення меж (Перекласифікація, Рекласифікіція). У векторних моделях, процес класифікації вимагає зміни не тільки атрибутів, але й графіки. Після проведення класифікації необхідно видалити всі лінії, що розділяють у новому покритті об'єкти одного класу. Потім атрибути цих полігонів передаються у нове покриття як єдиний новий атрибут для обох класів. Така операція в ГІС називається розчиненням меж. Принцип її дії добре видно на простому прикладі: є два полігони, на одному з яких росте пшениця, на іншому - кукурудза (рис. 6.7).
Класифікація через об'єднання категорій: об'єднання класів „кукурудза” і „пшениця” у більш великий клас „зернові”