

Методы исследования данных в Data Mining Метод деревьев решений
Стремительное развитие информационных технологий, в частности, прогресс в методах сбора, хранения и обработки данных позволил многим организациям собирать огромные массивы данных, которые необходимо анализировать. Объемы этих данных настолько велики, что возможностей экспертов уже не хватает, что породило спрос на методы автоматического исследования (анализа) данных, который с каждым годом постоянно увеличивается.
Деревья решений – один из таких методов автоматического анализа данных. Первые идеи создания деревьев решений восходят к работам Ховленда (Hoveland) и Ханта(Hunt) конца 50-х годов XX века. Однако, основополагающей работой, давшей импульс для развития этого направления, явилась книга Ханта (Hunt, E.B.), Мэрина (Marin J.) и Стоуна (Stone, P.J) "Experiments in Induction", увидевшая свет в 1966г.
Деревья решений – это способ представления правил в иерархической, последовательной структуре, где каждому объекту соответствует единственный узел, дающий решение.
Под правилом понимается логическая конструкция, представленная в виде "если ... то ...".
Искусственные нейронные сети
Искусственные нейронные сети (ИНС; artificial neural networks) представляют собой нелинейную систему, позволяющую классифицировать данные гораздо лучше, чем обычно используемые линейные методы. В приложении к медицинской диагностике ИНС дают возможность значительно повысить специфичность метода, не снижая его чувствительность
ИНС — это структура для обработки когнитивной информации, основанная на моделировании функций мозга. Основу каждой ИНС составляют относительно простые, в большинстве случаев однотипные элементы (ячейки), имитирующие работу нейронов мозга. Каждый нейрон характеризуется своим текущим состоянием по аналогии с нервными клетками головного мозга, которые могут быть возбуждены или заторможены. Искусственный нейрон обладает группой синапсов — однонаправленных входных связей, соединенных с выходами других нейронов, а также имеет аксон — выходную связь данного нейрона, с которой сигнал (возбуждения или торможения) поступает на синапсы следующих нейронов (рис. 1).
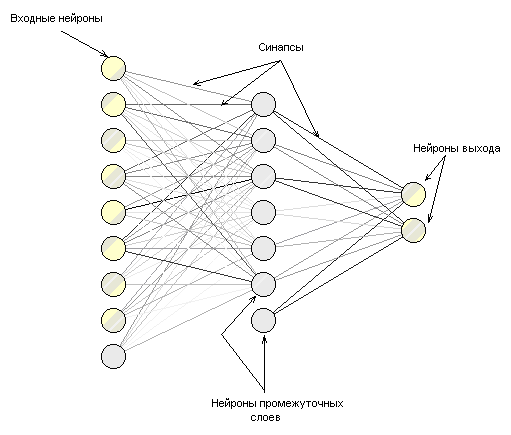
Рис. 1. Схематическое строение искусственной нейронной сети
Для ИНС характерен принцип параллельной обработки сигналов, что достигается путем объединения большого числа нейронов в так называемые слои и соединения нейронов различных слоев. В общем случае, чем сложнее ИНС, тем масштабнее задачи, подвластные ей. Прочность синаптических связей модифицируется в процессе извлечения знаний из обучающего набора данных (режим обучения), а затем используется при получении результата на новых данных (режим исполнения).
Метод опорных векторов (Support Vector Machine - svm)
Метод опорных векторов (Support Vector Machine - SVM) относится к группе граничных методов. Она определяет классы при помощи границ областей.
В основе метода лежит понятие плоскостей решений.
Решение задачи бинарной классификации при помощи метода опорных векторов заключается в поиске некоторой линейной функции, которая правильно разделяет набор данных на два класса. Рассмотрим задачу классификации, где число классов равно двум.
Задачу можно сформулировать как поиск функции f(x), принимающей значения меньше нуля для векторов одного класса и больше нуля - для векторов другого класса. В качестве исходных данных для решения поставленной задачи, т.е. поиска классифицирующей функции f(x), дан тренировочный набор векторов пространства, для которых известна их принадлежность к одному из классов. Семейство классифицирующих функций можно описать через функцию f(x). Гиперплоскость определена вектором а и значением b, т.е. f(x)=ax+b. Решение данной задачи проиллюстрировано на рис. 2.
В результате решения задачи, т.е. построения SVM-модели, найдена функция, принимающая значения меньше нуля для векторов одного класса и больше нуля - для векторов другого класса. Для каждого нового объекта отрицательное или положительное значение определяет принадлежность объекта к одному из классов.
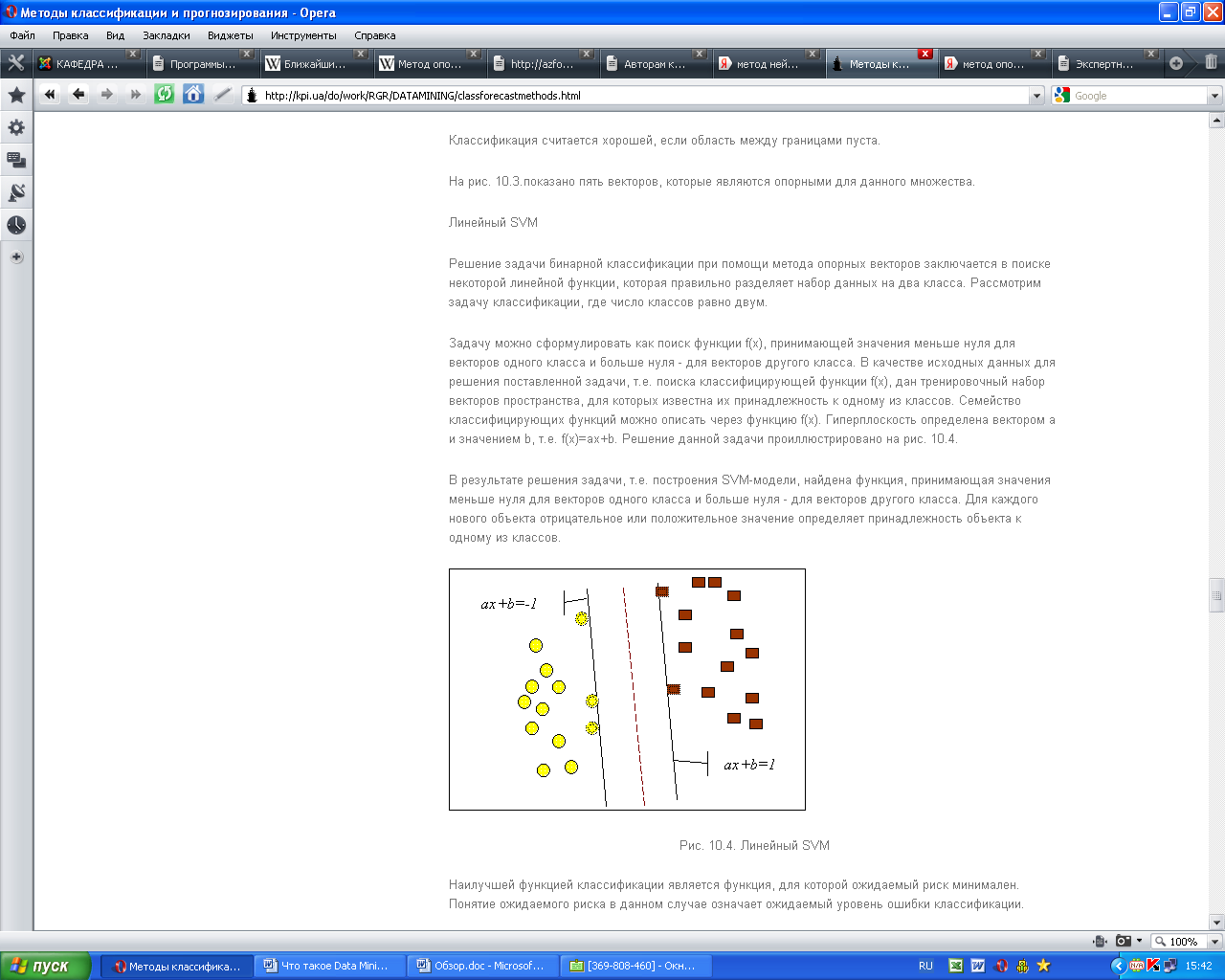
Рис. 2. Линейный SVM
Наилучшей функцией классификации является функция, для которой ожидаемый риск минимален. Понятие ожидаемого риска в данном случае означает ожидаемый уровень ошибки классификации.
Напрямую оценить ожидаемый уровень ошибки построенной модели невозможно, это можно сделать при помощи понятия эмпирического риска. Однако следует учитывать, что минимизация последнего не всегда приводит к минимизации ожидаемого риска. Это обстоятельство следует помнить при работе с относительно небольшими наборами тренировочных данных.
Эмпирический риск - уровень ошибки классификации на тренировочном наборе.
Таким образом, в результате решения задачи методом опорных векторов для линейно разделяемых данных мы получаем функцию классификации, которая минимизирует верхнюю оценку ожидаемого риска.
Одной из проблем, связанных с решением задач классификации рассматриваемым методом, является то обстоятельство, что не всегда можно легко найти линейную границу между двумя классами.
Метод опорных векторов позволяет:
получить функцию классификации с минимальной верхней оценкой ожидаемого риска (уровня ошибки классификации);
использовать линейный классификатор для работы с нелинейно разделяемыми данными, сочетая простоту с эффективностью.