

7.Средства распараллеливания
Существует несколько разных подходов к программированию параллельных вычислительных систем:
на стандартных широко распространенных языках программирования с использованием коммуникационных библиотек и интерфейсов для организации межпроцессорного взаимодействия (PVM, MPI, HPVM, MPL, OpenMP, ShMem)
использование специализированных языков параллельного программирования и параллельных расширений (параллельные реализации Fortran и C/C++, ADA, Modula-3)
использование средств автоматического и полуавтоматического распараллеливания последовательных программ (BERT 77, FORGE, KAP, PIPS, VAST)
программирование на стандартных языках с использованием параллельных процедур из специализированных библиотек, которые ориентированы на решение задач в конкретных областях, например: линейной алгебры, методов Монте-Карло, генетических алгоритмов, обработки изображений, молекулярной химии, и т.п. (ATLAS, DOUG, GALOPPS, NAMD, ScaLAPACK).
Существует также немало инструментальных средств, которые упрощают проектирование параллельных программ. Например:
CODE - Графическая система для создания параллельных программ. Параллельная программа изображается в виде графа, вершины которого есть последовательные части программы. Для передачи сообщений используются PVM и MPI библиотеки.
TRAPPER - Коммерческий продукт немецкой компании Genias. Графическая среда программирования, которая содержит компоненты построения параллельного программного обеспечения.
По опыту пользователей высокоскоростных кластерных систем, наиболее эффективно работают программы, специально написанные с учетом необходимости межпроцессорного взаимодействия. И даже несмотря на то, что программировать на пакетах, которые используют shared memory interface или средства автоматического распараллеливания, значительно удобней, больше всего распространены сегодня библиотеки MPI и PVM.
Учитывая массовою популярность MPI (The Message Passing Interface), хочется немного о нём рассказать.
"Интерфейс передачи сообщений" – это стандарт, который используется для построения параллельных программ и использует модель обмена сообщениями. Существуют реализации MPI для языка C/C++ и Fortran как в бесплатных, так и коммерческих вариантах для большинства распространенных суперкомпьютерных платформ, в том числе High Performance кластерных систем, построенных на узлах с ОС Unix, Linux и Windows. За стандартизацию MPI отвечает MPI Forum (http://www.mpi-forum.org/). В новой версии стандарта 2.0 описано большое число новых интересных механизмов и процедур для организации функционирования параллельных программ: динамическое управление процессами, односторонние коммуникации (Put/Get), параллельные I/O
Для оценки функциональности MPI рассмотрим график зависимости времени вычисления задачи решения систем линейных уравнений в зависимости от количества задействованных процессоров в кластере. Кластер построен на процессорах Intel и системе межузловых соединений SCI (Scalable Coherent Interface). Естественно, задача частная, и не надо понимать полученные результаты как общую модель прогнозирования быстродействия желаемой системы.
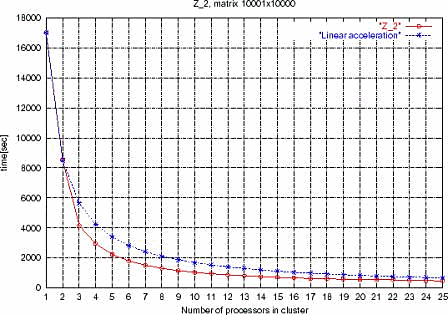 Рисунок
11. Зависимость времени вычисления задачи
решения систем линейных уравнений в
зависимости от количества задействованных
процессоров в кластере
Рисунок
11. Зависимость времени вычисления задачи
решения систем линейных уравнений в
зависимости от количества задействованных
процессоров в кластере
На графике отображены две кривые, синяя – линейное ускорение и красная – полученное в результате эксперимента. То есть, в результате использования каждой новой ноды мы получаем ускорение выше, чем линейное. Автор эксперимента утверждает, что такие результаты получаются из-за более эффективного использования кэш памяти, что вполне логично и объяснимо