

1 . Основные характеристики
1.2. Происхождение
Масштабируемый когерентный интерфейс (Scalable Coherent Interface) принят как стандарт ANSI/IEEE Std 1596—1992 [4]. Этот стандарт базируется на опыте разработчиков Fastbus (ANSI/IEEE 960—1989, IEC 935), Futurebus (IEEE P896.x). Его развивают Apple, Dolphin Interconnect Solutions, VITESSE, SGI/CRAY, HP, SUN, IBM, CERN и ряд других организаций.
В дальнейшем для обозначения этого стандарта будем использовать общепринятое сокращение SCI по первым буквам английского названия. Микросхемы, реализующие этот стандарт и называемые в дальнейшем узлами, выпускаются серийно несколькими фирмами [9—II].
1.3. Механизм когерентности
SCI предусматривает реализацию когерентности посредством стандартно организованной кэш-памяти, размещаемой в узле SCI.
Эта кэш-память располагается в интерфейсе между ВМ и узлом и вписывается в механизм реализации когерентности ВМ следующим образом. Если в предыдущих уровнях иерархии памяти ВМ обнаруживается отсутствие необходимых данных, то производится поиск этих данных в кэш-памяти узла.
При нахождении данных, если они состоятельны, их копия перемещается внутрь иерархии памяти ВМ. При нахождении данных в модифицируемом состоянии ожидается конец модификации, и затем копия данных помещается внутрь иерархии памяти ВМ.
При отсутствии данных вырабатывается сигнал промаха, который активизирует адаптер интерфейса на действия по доставке данных из удаленных блоков памяти.
Таким образом, SCI предлагает добавлять еще один уровень иерархии памяти в ВМ, а также стандартный протокол управления когерентностью кэш-памятей узлов.
Реализация узлов на основе SCI может не использовать кэш-памяти и протоколов когерентности, т. е. реализовать не все возможности SCI.
В этом случае эти узлы могут применяться для построения коммуникационной среды со стандартными заголовком, способом адресации и протоколом передачи пакетов
1. 4. Предназначение
Стандарт SCI обеспечивает построение легкой в реализации, масштабируемой, эффективной в стоимостном аспекте коммуникационной среды для объединения процессоров и памятей, либо создания распределенной сети рабочих станций, либо для организации ввода/вывода суперЭВМ, высокопроизводительных серверов и рабочих станций на базе современных микропроцессоров.
Стандарт предусматривает создание пропускной способности не менее 1 Гбайта/с для сосредоточенных систем и не менее 1 Гбита/с для распределенных систем типа сети рабочих станций.
1. 5. Структура коммуникационных сред на базе sci
Каждый узел имеет входной и выходной каналы. Узлы связаны однонаправленными каналами “точка-точка” либо с соседним узлом, либо подключены к коммутатору.
При объединении узлов должна обязательно формироваться циклическая магистраль (кольцо) из узлов, соединенных каналами “точка-точка”, между входным и выходным каналами каждого узла.
Один узел в кольце, называемый scrubber, выполняет функции: инициализации узлов кольца с установлением адресов, управления таймерами, уничтожения пакетов, не нашедших адресата. Этот узел помечает проходящие через него пакеты и уничтожает уже помеченные пакеты. В кольце может быть только один scrubber.
Возможные структуры систем с использованием SCI показаны на рис. 2.1 .
При реализации интерфейса на задней панели возможны соединения в последовательное кольцо или кольцо с чередованием, как показано на рис. 2.1. Для обхода пустых разъемов предполагается использовать либо платы-проходники, либо пары переходных плат.
Возможно построение многокольцевых систем, связанных через агентов. Агент-коммутатор или агент-мост обеспечивают соединение между разными кольцами или между кольцом и коммутационной средой с другим протоколом, например, шинами PCI, S-bus. Посредством SCI могут быть реализованы различные структуры межсоединений, показанные на рис. 2.1.3-2.1.5.
Возможности, функционально эквивалентные тем, что предоставляются при взаимодействии устройств на шине, реализуются путем образования однонаправленной магистрали между узлами, состоящей из цепочки соединений "точка-точка" между узлами и коммутаторами межузловых соединений. Однонаправленность передач в SCI имеет принципиальный характер, так как исключает переключение выходных ножек микросхем с передачи на прием и обратно. Такое переключение создает большие электрические помехи. Таким образом, вместо физической шины используется множество парных соединений, обеспечивающих двунаправленую передачу.
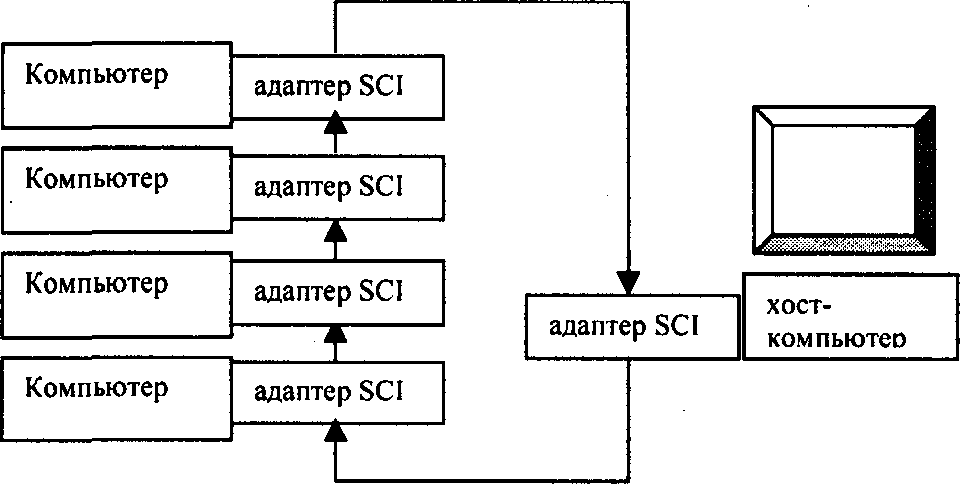
Мультипроцессорный (МР) сервер, компонуемый пользователем из рабочих станций или персональных компьютеров (материнских плат)
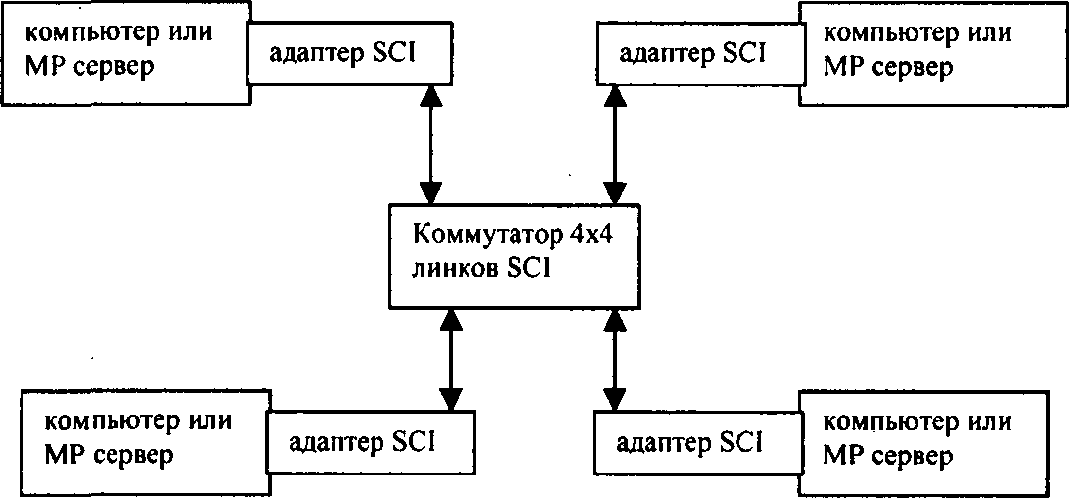
МР сервер повышенной отказоустойчивости с малой задержкой установления соединений
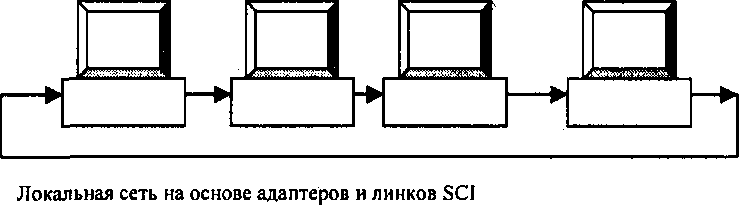
Рис. 2.1.1. Структуры систем с использованием SCI
щих высокую скорость передачи. Преодолеваются фундаментальное ограничение шин — одна передача в каждый промежуток времени предоставления шины передающему устройству, а также ограничения, связанные со скоростью распространения сигналов по проводникам. В случае асинхронных шин ограничение обусловлено временем передачи сигналов "запрос-подтверждение", в случае синхронных шин — разницей времени распространения тактового сигнала от его генератора и времени распространения данных, производимых в передающем устройстве.
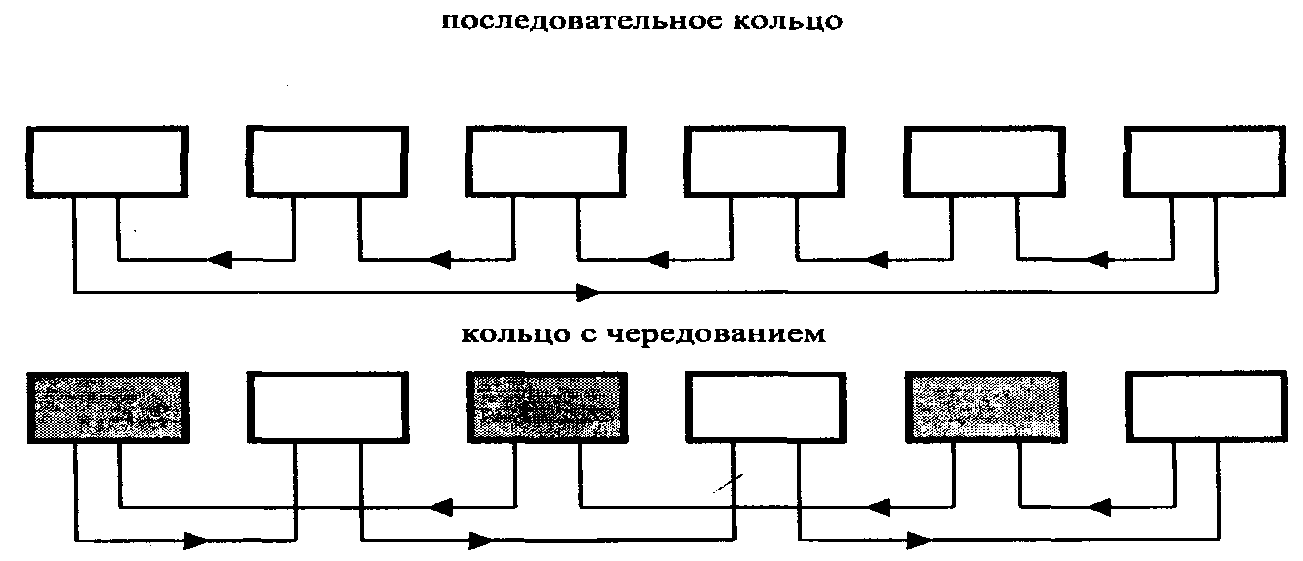
Рис. 2.1.2. Одномерный тор (кольцо)
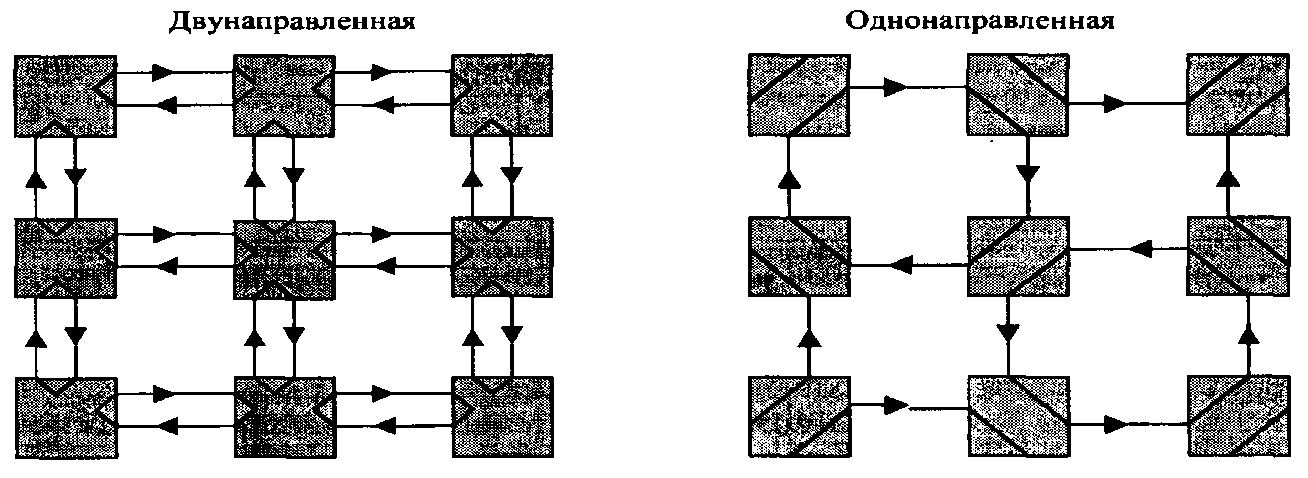
Рис. 2.1.3. Двумерная решетка