

Заключение
Технология SAN продолжает развиваться с нарастающей скоростью. Сегодня все большее число систем хранения данных строится на основе SAN. Однако при создании SAN, как и при создании «обычной» локальной сети, необходимо проводить проектирование, задаваясь вопросом: стоит ли при модернизации или создании новой системы хранения данных вкладывать средства в устаревшие технологии или уже сегодня начать внедрять SAN?
Принципы построения кластерных архитектур.
Практика создания высокопроизводительных кластерных систем подошла к определенному (и очень важному) этапу, который требует переосмысления достигнутых результатов и выбора стратегического пути дальнейшего развития. В настоящее время не составляет особой проблемы выбор компонент и конфигурация специализированной кластерной системы, состоящей из 32-128 вычислительных узлов и обладающей реальной производитель-ностью до 60 Гфлоп. Возможность дальнейшего увеличения производительности таких систем упирается в две фундаментальные проблемы.
Возможность масштабирования кластера ограничена значением отношения скорости процессора к скорости связи, которое не должно быть слишком большим (реально это отношение для больших систем не может быть более 3-4, в противном случае не удается даже реализовать режим единого образа операционной системы). С другой стороны, последние 10 лет истории развития процессоров и коммуникаторов показывают, что разрыв по скорости между ними все увеличивается.
Для конфигурации более чем 128-и процессорных систем приходится использовать несколько коммуникаторов и при распараллеливании задачи возникает очень серьезная проблема балансировки процессоров более чем через один рутер. Стандартные статические средства балансировки по ряду причин не могут справиться с этой задачей, а разработанные динамические пакеты эффективны лишь в пределах одного рутера.
Частичное решение этой задачи возможно на базе суперскалярных процессоров нового поколения, имеющих относительно низкую тактовую частоту, и поэтому очень эффективно масштабируемых при использовании современных коммуникаторов.
С другой стороны, из-за наличия большого числа конвейеров ввода/вывода и нескольких вычислительных конвейеров они выполняют несколько операций за такт и могут обеспечить очень существенное увеличение производительности даже при конфигурации кластера с одним коммуникатором.
Поскольку производительность суперскалярных процессоров уже сейчас достигает 4-6 Гфлоп, а современные коммуникаторы позволяют объединять до 128-и процессоров в компактную конфигурацию, открывается замечательная возможность производить балансировку стандартных программ под фиксированные конфигурации с двумя и четырьмя рутерами, достигая пиковой производительности в 1 Тфлоп без революционного изменения сервисного математического обеспечения на кластере.
Таким образом, оптимальное решение для создания высокопроизводительной системы терафлопного уровня должно быть реализовано в два этапа:
На первом этапе создается конфигурация с одним коммуникатором до 64 процессоров, имеющая пиковую производительность от 256 Гфлоп.
После отработки системы динамической балансировки эта система расширяется до 128-и процессоров, возможно с модернизацией процессоров, и пиковой производительностью до 0,6-0,8 Тфлоп.
Обзор рынка процессоров показывает, что в настоящее время единственные процессоры с требуемыми качествами в более или менее доступном ценовом диапазоне это — Itanium 2. Ориентация на этот процессор может оказаться весьма эффективной через несколько месяцев, когда появление на рынках новых процессоров Оптерон и Мадисон, существенно снизит на него цену.
При выборе собственно кластерной конфигурации можно опираться на имеющийся значительный опыт у основных производителей. Ниже приводится обзор кластерных решений ведущих фирм. Обзор составлен на основе мониторинга Веб-сайтов известных компьютерных компаний IBM, HP и SGI, опыта создания вычислительных кластеров разных архитектур и результатов тестирования сотрудниками Института высокопроизводительных вычислений и информационных систем (ИВВИС, Петербург) высокопроизводительных кластеров фирм IBM и SGI.
Выбор числа узлов кластера.
При выборе собственно кластерной конфигурации можно опираться на имеющийся значительный опыт у основных производителей.
Вычислительная производительность кластера грубо оценивается, как сумма вычислительной производительности его узлов. Количество узлов при этом определяется классом решаемых задач, в качестве приближенных расчетов можно использовать степенные и логарифмические оценки.
Эффективность мультипроцессорных и многомашинных систем .
Эффективность многопроцессорной обработки оценивают коэффициентом ускорения Rn/R1, определяемым отношением производительности (Rn) n-процессорной системы к производительности (R1) однопроцессорной системы при обработке одного и того же потока задач. В идеальном случае при полном распараллеливании решаемых задач Rn/R1 = n.
На практике, однако, всегда имеются потери времени на выполнение различного рода обменных операций между процессорами, в результате чего при реализации высо-кораспараллеливаемых задач более точной оценкой этого коэффициента является Rn/R1 = kn, где к близко к единице и вместе с тем меньше ее.
График этой зависимости представлен на рис. 1. (кривая 1).
![]()
При решении широкого круга распараллеливаемых задач для оценки коэффициента Rn/R1 можно выбрать зависимость, носящую логарифмический характер (рис. 1., кривая 2):
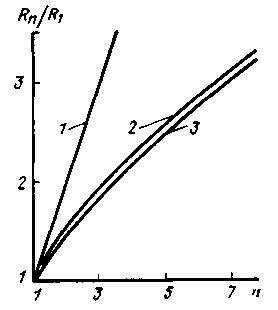
Рис. 1. Графики ускорения вычислений при многопроцессорной обработке
Эта зависимость достаточно хорошо соответствует экспериментальным результатам, которые свидетельствуют, что добавление второго процессора увиличивает производительность в 1,6 ... 1,8 раза, третьего - в 1,8 ... 2,3 раза и т.д.
Отклонение этой зависимости от линейной при увеличении числа процессоров объясняется возрастающими потерями времени на разрешение конфликтных ситуаций при обращении нескольких процессоров к одному и тому же модулю оперативной памяти, увеличением доли операций обмена между процессорами и другими потерями, обуславливаемыми в целом слабым распараллеливанием вычислений.
Ускорение вычислений при многопроцессорной обработке оценивается выражением:
![]()
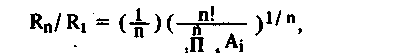
где Аi— доля работ, выполняемых i-м процессором ( Aj = 1).
По данным [52] расхождение приведенной оценки с экспериментальными результатами, полученными при выполнении 200 программ, составляет около 8%. На рис. 2.1 (кривая 3) представлена эта зависимость для случая равной загрузки процессоров, т.е. для А= 1/ n. При этом -
Rn/Ri = пп!
Ускорение вычислений зависит так же от соотношения последовательных и параллельных частей программы, опреде-
ляемых законом Амдала.