

Мультикомпьютеры с передачей сообщений
Как видно из схемы на рис. 8.12, существует два типа параллельных процессоров MIMD: мультипроцессоры и мультикомпыотеры. В предыдущем разделе мы рассматривали мультипроцессоры. Мы увидели, что мультипроцессоры могут иметь разделенную память, доступ к которой можно получить с помощью обычных команд LOAD и STORE. Такая память реализуется разными способами, включая отслеживающие шины, многоступенчатые сети, а также различные схемы на основе каталога. Программы, написанные для мультипроцессора, могут получать доступ к любому месту в памяти, не имея никакой информации о внутренней топологии или схеме реализации. Именно благодаря такой иллюзии мультипроцессоры весьма популярны.
Однако мультипроцессоры имеют и некоторые недостатки, поэтому мультикомпыотеры тоже очень важны.
Во-первых, мультипроцессоры нельзя расширить до больших размеров. Чтобы расширить машину Interprise 10000 до 64 процессоров, пришлось добавить огромное количество аппаратного обеспечения.
В Sequent NUMA-Q, дошли до 256 процессоров, но ценой неодинакового времени доступа к памяти. Ниже мы рассмотрим два мультикомпьютера, которые содержат 2048 и 9152 процессора соответственно. Через много лет кто-нибудь сконструирует мультипроцессор, содержащий 9000 узлов, но к тому времени мультикомпыотеры будут содержать уже 100 000 узлов.
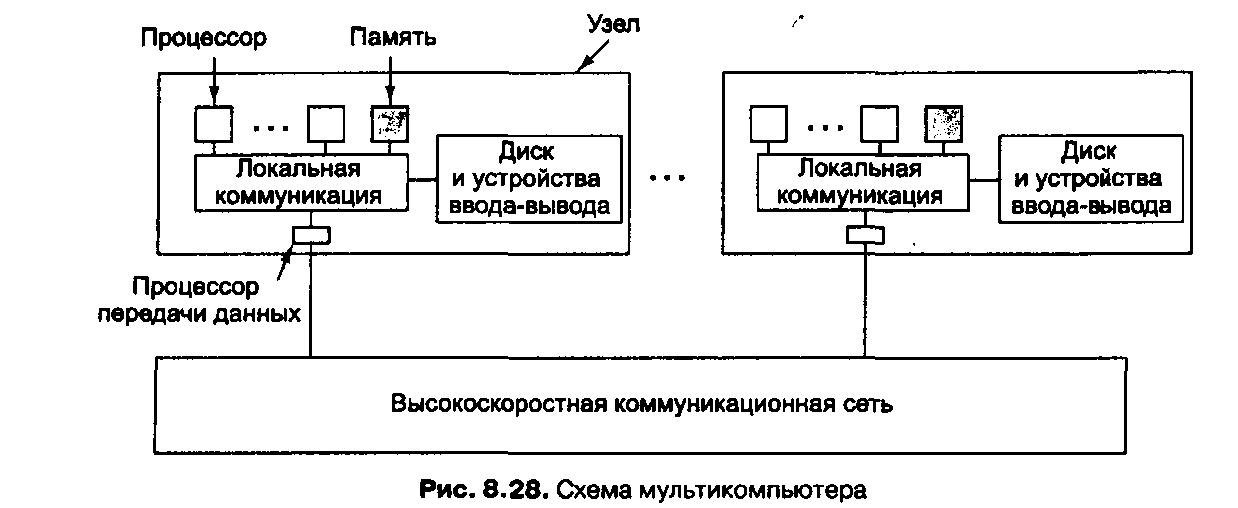
Мультикомпыотеры бывают разных типов и размеров, поэтому очень трудно привести хорошую классификацию. Тем не менее можно назвать два общих типа:
МРР и COW. Ниже мы рассмотрим каждый из этих типов.
СгауТЗЕ
В семейство T3E (последователя T3D) входят самые последние суперкомпьютеры, восходящие к компьютеру 6600. Различные модели — T3E, ТЗЕ-900 и T3E-1200 — идентичны с точки зрения архитектуры и различаются только ценой и производительностью (например, 600,900 или 1200 мегафлопов на процессор). Мегафлоп — это 1 млн операций с плавающей точкой/с. (FLOP — FLoating-point Operations — операции с плавающей точкой). В отличие от 6600 и Сгау-1, в которых очень мало параллелизма, эти машины могут содержать до 2048 процессоров. Мы используем термин T3E для обозначения всего семейства, но величины производительности будут приведены для машины T3E-1200. Эти машины продает компания Cray Research, филиал Silicon Graphics. Они применяются для разработки лекарственных препаратов, поиска нефти и многих других задач.
В системе T3E используются процессоры DEC Alpha 21164. Это суперскалярный процессор RISC, способный выдавать 4 команды за цикл. Он работает с частотой 300, 450 и 600 МГц в зависимости от модели. Тактовая частота — основное различие между разными моделями T3E. Alpha — это 64-битная машина с 64-битными регистрами. Размер виртуальных адресов ограничен до 43 битов, а физических — до 40 битов. Таким образом, возможен доступ к 1 Тбайт физической памяти.
Узлы также связаны одним или несколькими GigaRings — подсистемами ввода-вывода с коммутацией пакетов, обладающими высокой пропускной способностью. Узлы используют эту подсистему для взаимодействия друг с другом, а также с сетями, дисками и другими периферическими устройствами. Они по ней посылают пакеты размером до 256 байтов. Каждый GigaRing состоит из пары колец шириной в 32 бита, которые соединяют узлы процессоров со специальными узлами ввода-вывода.
Узлы ввода-вывода содержат гнезда для сетевых карт (например, HIPPI, Ethernet, ATM, FDDI), дисков и других устройств.
Выводы
Все процессы, работающие вместе на мультипроцессоре, могут разделять одно виртуальное адресное пространство, отображенное в общую память. Любой процесс может считывать слово из памяти или записывать слово в память с помощью команд LOAD и STORE
Ключевое отличие мультикомпьютера от мультипроцессора состоит в том, что каждый процессор в мультикомпьютере имеет свою собственную локальную память, к которой этот процессор может обращаться, выполняя команды LOAD и STORE, но никакой другой процессор не может получить доступ к этой памяти с помощью тех же команд LOAD и STORE.
В мультикомпьютере для взаимодействия между процессорами часто используются примитивы send и receive. Поэтому программное обеспечение мультикомпьютера имеет более сложную структуру, чем программное обеспечение мультипроцессора.
Практически все исследования в области архитектур с параллельной обработкой направлены на создание гибридных форм, которые сочетают в себе преимущества обеих архитектур.
Невозможно построить компьютер с одним процессором и временем цикла в 0,001 нc, но зато можно построить компьютер с 1000 процессорами, время цикла каждого из которых составляет 1 нc.
Когда мы сталкиваемся с новой компьютерной системой параллельного действия, возникает три вопроса:
1. Каков тип, размер и количество процессорных элементов?
2. Каков тип, размер и количество модулей памяти?
3. Как взаимодействуют элементы памяти и процессорные элементы?
Хотя существуют самые разнообразные процессоры и системы памяти, системы параллельного действия различаются в основном тем, как соединены разные части. Схемы взаимодействия можно разделить на две категории: статические и динамические.
1. В статических схемах компоненты просто связываются друг с другом определенным образом. В качестве примеров статических схем можно привести звезду, кольцо и решетку.
В динамических схемах все компоненты подсоединены к переключательной схеме, которая может трассировать сообщения между компонентами.
Начальный период разработки параллельных КС характеризуется построением уникальных в схемотехническом и конструктивном отношении суперкомпьютеров, который оказался тупиковым. Последующий этап основан на использовании серийно выпускаемых процессоров и памяти.
Современные параллельные архитектуры имеют следующие разновидности:
Мультипроцессоры UMA (SMP) с координатными коммутаторами.
Мультипроцессоры UMA с много- ступенчатыми сетями.
Мультипроцессоры NUMA.
Мультипроцессоры CC-NUMA.
Мультипроцессоры CC-NUMA.
Параллельные векторные системы (PVP)
Кластерные архитектуры.
МРР — процессоры с массовым параллелизмом
МРР (Massively Parallel Processors — процессоры с массовым параллелизмом) —это огромные суперкомпьютеры стоимостью несколько миллионов долларов. Они используются в различных науках и промышленности для выполнения сложных вычислений, для обработки большого числа транзакций в секунду или для хранения больших баз данных и управления ими.
В большинстве таких машин используются стандартные процессоры. Это могут быть процессоры Intel Pentium, Sun UltraSPARC, IBM RS/6000 и DEC Alpha. Отличает мультикомпьютеры то, что в них используется сеть, по которой можно передавать сообщения, с низким временем ожидания и высокой пропускной способностью. Обе характеристики очень важны, поскольку большинство сообщений малы по размеру (менее 256 байтов), но при этом суммарная нагрузка в большей степени зависит от длинных сообщений (более 8 Кбайт).
Еще одна характеристика МРР — огромная производительность процесса ввода-вывода. Часто приходится обрабатывать огромные массивы данных, иногда терабайты. Эти данные должны быть распределены по дискам, и их нужно перемещать в машине с большой скоростью.
Следующая специфическая черта МРР — отказоустойчивость. При наличии не одной тысячи процессоров несколько неисправностей в неделю неизбежны. Прекращать работу системы из-за неполадок в одном из процессоров было бы неприемлемо, особенно если такая неисправность ожидается каждую неделю. Поэтому большие МРР всегда содержат специальное аппаратное и программное обеспечение для контроля системы, обнаружения неполадок и их исправления.
МРР представляет собой набор более или менее стандартных узлов, которые связаны друг с другом высокоскоростной сетью. Рассмотрим несколько конкретных примеров систем МРР: Cray T3E и Intel/Sandia Option Red.
СгауТЗЕ
В семейство ТЗЕ (последователя T3D) входят самые последние суперкомпьютеры, восходящие к компьютеру 6600. Различные модели — ТЗЕ, ТЗЕ-900 и ТЗЕ-1200 — идентичны с точки зрения архитектуры и различаются только ценой и производительностью (например, 600,900 или 1200 мегафлопов на процессор). Мегафлоп — это 1 млн операций с плавающей точкой/с. (FLOP — FLoating-point Operations — операции с плавающей точкой).
В отличие от 6600 и Сгау-1, в которых очень мало параллелизма, эти машины могут содержать до 2048 процессоров. Мы используем термин ТЗЕ для обозначения всего семейства, но величины производительности будут приведены для машины ТЗЕ-1200. Эти машины продает компания Cray Research, филиал Silicon Graphics. Они применяются для разработки лекарственных препаратов, поиска нефти и многих других задач.
В системе ТЗЕ используются процессоры DEC Alpha 21164. Это суперскалярный процессор RISC, способный выдавать 4 команды за цикл. Он работает с частотой 300,450 и 600 МГц в зависимости от модели. Тактовая частота — основное различие между разными моделями ТЗЕ. Alpha — это 64-битная машина с 64-битными регистрами. Размер виртуальных адресов ограничен до 43 битов, а физических — до 40 битов. Таким образом, возможен доступ к 1 Тбайт физической памяти.
Каждый процессор Alpha имеет двухуровневую кэш-память, встроенную в микросхему процессора. Кэш-память первого уровня содержит 8 Кбайт для команд и 8 Кбайт для данных.
Кэш-память второго уровня — это смежная трехвходовая ассоциативная кэш-память на 96 Кбайт, содержащая и команды и данные вместе. Кэш-память обоих уровней содержит команды и данные только из локального ОЗУ, а это может быть до 2 Гбайт на процессор. Поскольку максимальное число процессоров равно 2048, общий объем памяти может составлять 4 Тбайт.
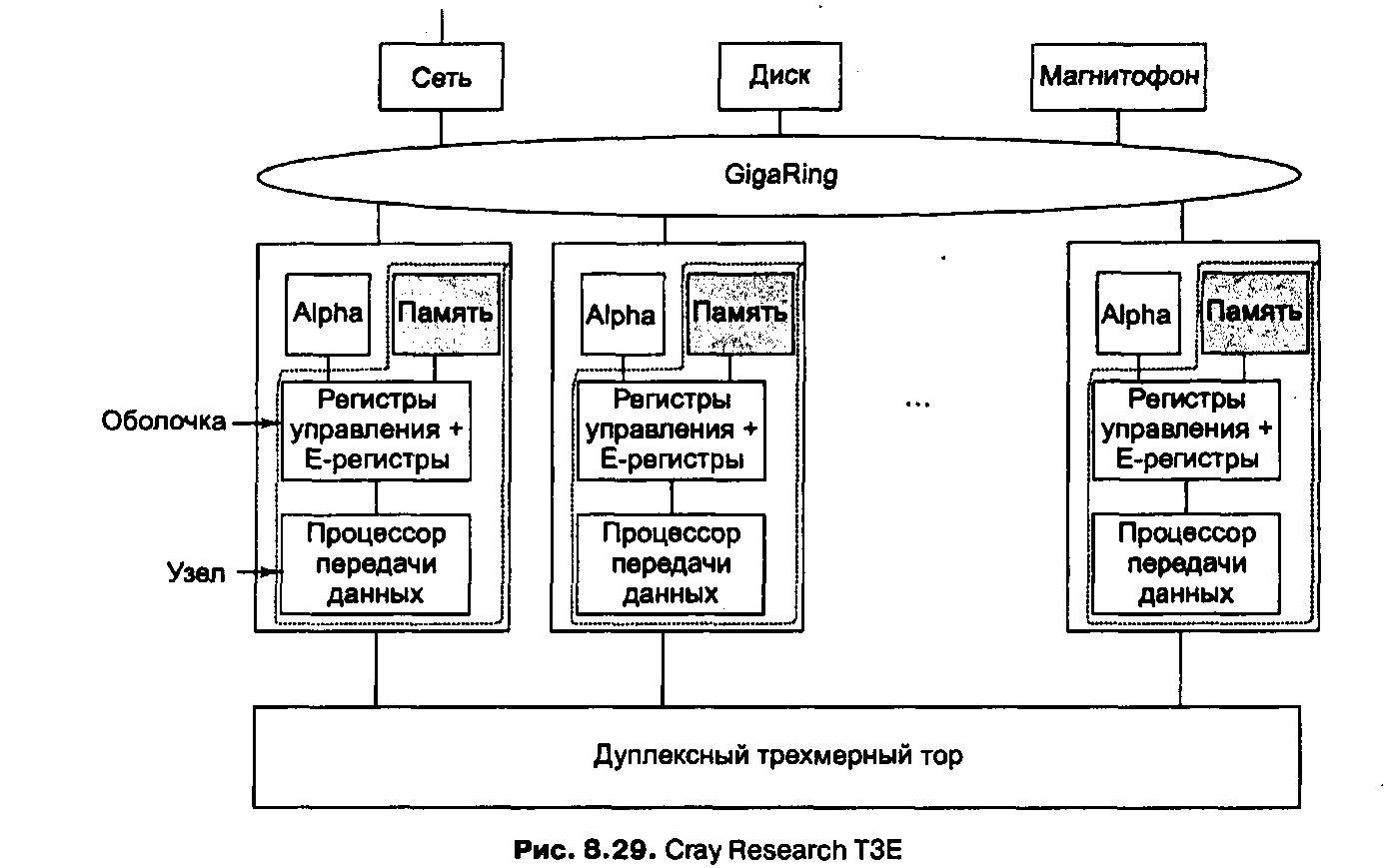
Каждый процессор Alpha заключен в особую схему, которая называется оболочкой (shell) (рис. 1). Оболочка содержит память, процессор передачи данных и 512 специальных регистров (так называемых Е-регистров).
Эти регистры могут загружаться адресами удаленной памяти с целью чтения или записи слов из удаленной памяти (или блоков из 8 слов). Это значит, что в машине ТЗЕ есть доступ к удаленной памяти, но осуществляется он не с помощью обычных команд LOAD и STORE.
Эта машина представляет собой гибрид между NC-NUMA и МРР, но все-таки больше похожа на МРР. Непротиворечивость памяти гарантируется, поскольку слова, считываемые из удаленной памяти, не попадают в кэш-память.
Узлы в машине ТЗЕ связаны двумя разными способами (см. рис. 1). Основная топология — дуплексный 3-мерный тор. Например, система, содержащая 512 узлов, может быть реализована в виде куба 8x8x8. Каждый узел в 3-мерном торе имеет 6 каналов связи с соседними узлами (по направлению вперед, назад, вправо, влево, вверх и вниз). Скорость передачи данных в этих каналах связи равна 480 Мбайт/с в любом направлении.
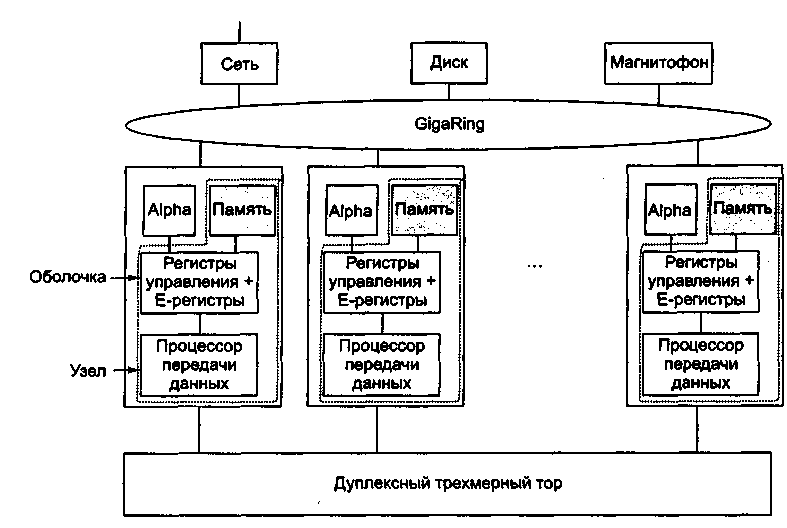
Рис. 1. Cray Research T3E
Узлы также связаны одним или несколькими GigaRings — подсистемами ввода-вывода с коммутацией пакетов, обладающими высокой пропускной способностью. Узлы используют эту подсистему для взаимодействия друг с другом, а также с сетями, дисками и другими периферическими устройствами. Они по ней посылают пакеты размером до 256 байтов. Каждый GigaRing состоит из пары колец шириной в 32 бита, которые соединяют узлы процессоров со специальными узлами ввода-вывода. Узлы ввода-вывода содержат гнезда для сетевых карт (например, HIPPI, Ethernet, ATM, FDDI), дисков и других устройств.
В системе ТЗЕ может быть до 2048 узлов, поэтому неисправности будут происходить регулярно. По этой причине в системе на каждые 128 пользовательских узлов содержится один запасной узел. Испорченные узлы могут быть замещены запасными во время работы системы без перезагрузки. Кроме пользовательских и запасных узлов есть узлы, которые предназначены для запуска серверов операционной системы, поскольку пользовательские узлы запускают не всю систему, а только ядро. В данном случае используется операционная система UNIX.
Intel/Sandia Option Red
В середине 90-х годов департаменты обороны и энергетики приступили к выполнению программы разработки 5 систем МРР, которые будут работать со скоростью 1, 3, 10, 30 и 100 терафлопов/с соответственно.
Для сравнения: 100 терафлопов (1014 операций с плавающей точкой в секунду) — это в 500000 раз больше, чем мощность процессора Pentium Pro, работающего с частотой 200 МГц.
В отличие от машины ТЗЕ, которую можно купить в магазине (правда, за большие деньги), машины, работающие со скоростью 1014 операций с плавающей точкой, — это уникальные системы, распределяемые в конкурентных торгах Департаментом энергетики, который руководит национальными лабораториями. Компания Intel выиграла первый контракт; IBM выиграла следующие два. Эти машины предназначены для военных целей. Какой-то сообразительный работник Пентагона придумал патриотические названия для первых трех машин: red, white и blue (красный, белый и синий — цвета флага США). Первая машина, выполнявшая 1014 операций с плавающей точкой, называлась Option Red (Sandia National Laborotary, декабрь 1996), вторая — Option Blue (1999), а третья — Option White (2000). Ниже мы будем рассматривать первую из этих машин, Option Red.
Машина Option Red состоит из 4608 узлов, которые организованы в трехмерную сетку. Процессоры запакованы на платах двух разных типов.
Платы kestrel используются в качестве вычислительных узлов, а платы eagle используются для сервисных, дисковых, сетевых узлов и узлов загрузки. Машина содержит 4536 вычислительных узлов, 32 сервисных узла, 32 дисковых узла, 6 сетевых узлов и 2 узла загрузки.
Плата kestrel (рис. 2, а) содержит 2 логических узла, каждый из которых включает 2 процессора Pentium Pro на 200 МГц и разделенное ОЗУ на 64 Мбайт. Каждый узел kestrel содержит собственную 64-битную локальную шину и собственную микросхему NIC (Network Interface Chip — сетевой адаптер). Две микросхемы NIC связаны вместе, поэтому только одна из них подсоединена к сети, что делает систему более компактной. Платы eagle также содержат процессоры Pentium Pro, но всего два на каждую плату. Кроме того, они отличаются высокой производительностью процесса ввода-вывода.
Платы связаны в виде решетки 32x38x2 в виде двух взаимосвязанных плоскостей 32x38 (размер решетки продиктован целями компоновки, поэтому не во всех узлах решетки находятся платы).
В каждом узле находится маршрутизатор с шестью каналами связи: вперед, назад, вправо, влево, с другой плоскостью и с платой kerstel или eagle. Каждый канал связи может передавать информацию одновременно в обоих направлениях со скоростью 400 Мбайт/с. Применяется маршрутизация «червоточина», чтобы сократить время ожидания.
Применяется
пространственная
маршрутизация,
когда пакеты сначала потенциально
перемещаются в другую плоскость, затем
вправо-влево, затем вперед-назад и,
наконец,
в нужную плоскость, если они еще не
оказались в нужной плоскости.
Два перемещения
между плоскостями нужны для повышения
отказоустойчивости. Предположим,
что пакет нужно переместить в соседний
узел, находящийся впереди исходного,
но канал связи между ними поврежден.
Тогда сообщение можно отправить
в другую плоскость, затем на один узел
вперед, а затем обратно в первую плоскость,
минуя таким образом поврежденный канал
связи.
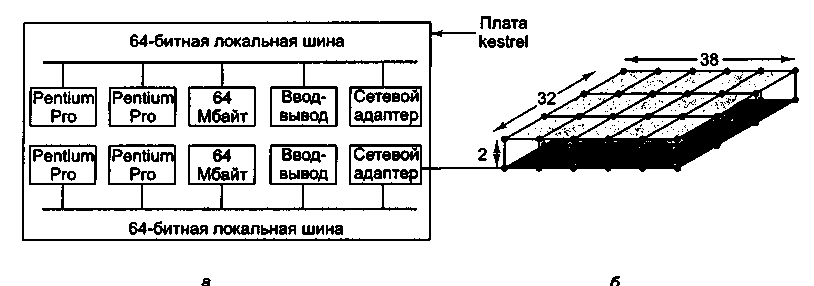
Рис. 2. Система Intel/Sandia Option Red: плата kestrel (а); сеть (б)
Систему можно логически разделить на 4 части: сервис, вычисление, ввод-вывод и система. Сервисные узлы — это машины UNIX общего назначения с разделением времени, которые позволяют программистам писать и отлаживать свои программы. Вычислительные узлы запускают большие приложения. Они запускают не всю систему UNIX, а только микроядро, которое называется кугуаром (coguar)1.
Узлы ввода-вывода управляют 640 дисками, содержащими более 1 Тбайт данных.
Есть два независимых набора узлов ввода-вывода. Узлы первого типа предназначены для секретной военной работы, а узлы второго типа — для несекретной работы.
Эти два набора вводятся и удаляются из системы вручную, поэтому в каждый момент времени подсоединен только один набор узлов, чтобы предотвратить утечку информации с секретных дисков на несекретные диски. Наконец, системные узлы используются для загрузки системы.
COW — Clusters of Workstations (кластеры рабочих станций)