

1. Структура узла
Узлы SCI должны отсылать сформированные в них пакеты, возможно с одновременным приемом других пакетов, адресованных узлу, и пропуском через узел транзитных пакетов. Структура узла показана на рис.1. Для транзитных пакетов, прибывающих во время передачи узлом собственного пакета, предусмотрена проходная FIFO очередь.
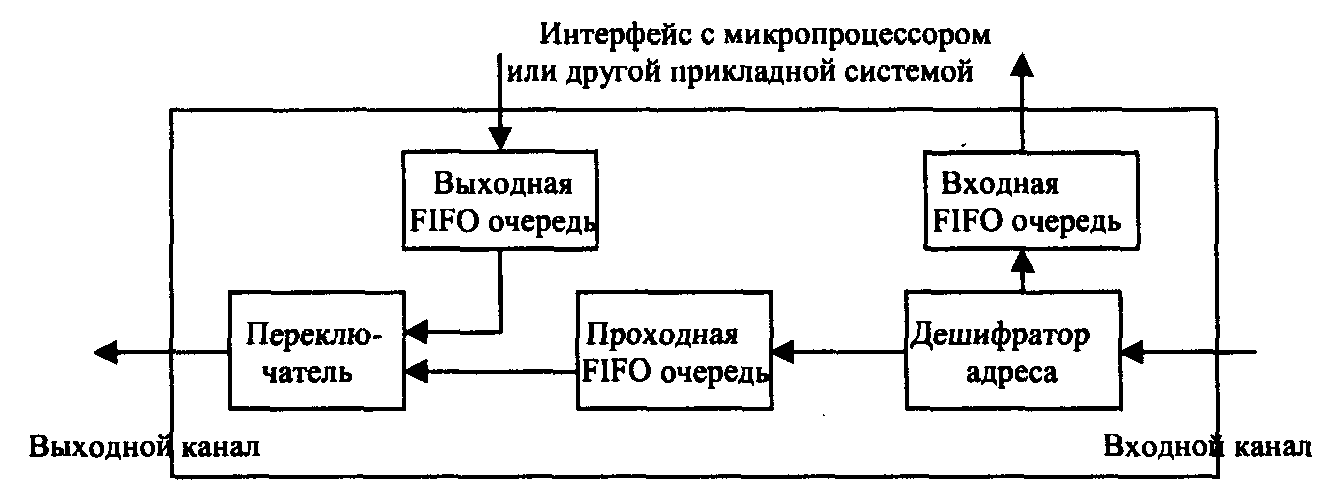
Рис 1. Структура узла SCI
При дисциплине, когда собственный пакет не передается до тех пор, пока есть транзитные, необходимая длина проходной очереди определяется длиной передаваемых узлами пакетов. Размер проходной очереди должен быть достаточен для приема пакетов без переполнения.
В узле вводятся также входная и выходная FIFO очереди для пакетов, принимаемых и передаваемых узлом соответственно.
2. Пакеты и свободные символы
Узел SCI принимает поток данных и передает другой поток данных. Эти потоки состоят из SCI пакетов и свободных (пустых — idle) символов.
Через каналы непрерывно передаются либо символы пакетов, либо свободные символы, которые заполняют интервалы между пакетами.
В случае, если нечего передавать и проходная очередь узла пуста, он передает на выход свободный символ.
3. Прием пакетов
Появление сигнала "1" на магистрали отмечает начало пакета. Если адрес получателя в пакете совпадает с адресом узла, пакет извлекается в узел.
Информация из заголовка пакета используется для формирования эхо-пакета, который заносится в проходную FIFO очередь для отправки от получателя к отправителю. Эхо-пакеты являются частью механизма арбитража, приоритетности и продвижения пакетов.
Если входная FIFO очередь узла полна, пакет выбрасывается, и в управляющем поле эхо-пакета устанавливается бит занятости, что извещает отправителя о необходимости повторно передать пакет.
Когда узел принимает предназначенный ему пакет и он в состоянии принять этот пакет, пакет направляется во входную FIFO очередь.
Далее вычисляется ЦИК (циклический избыточный код) и сравнивается со значением ЦИК пакета. При совпадении — прием пакета окончен.
Если получен пакет с неправильным ЦИК, то этот пакет выбрасывается, а ЦИК эхо-пакета изменяется так, чтобы эхо-пакет был выброшен (это позднее должно вызвать его повторную передачу).
Если на вход прибывает пакет, не предназначенный узлу, то прибывающий пакет поступает в проходную FIFO очередь.
Пересылаемый пакет накапливает информацию для управления передачей пакетов. Управляющая информация помещается в заголовок пакета и как минимум в один свободный символ, отделяющий данный пакет от последующего пакета. На основе этого механизма выполняются все функции управления потоком пакетов: арбитраж, приоритетность, продвижение пакетов.
4. Передача пакетов
Узел может передавать пакет, если его проходная FIFO очередь пуста. Передача пакета инициируется его перемещением в выходную FIFO очередь.
Когда пакет передается, для него вычисляется циклический избыточный код (ЦИК), который приформировывается в конце пакета. ЦИК — последовательно-параллельная версия 16-битного CCITT-CRC.
Передача начинается помещением слова на выход и установкой высокого значения выходного флага. Значение выходного флага остается высоким все время передачи пакета. ЦИК добавляется к концу пакета, когда значение выходного флага становится низким.
Узел, отправляя пакет, помечает его номером, который возвращается ему при приеме эхо-пакета от узла-адресата. Если в течение тайм-аута не поступает ответный пакет, то выполняется повтор передачи пакета.
После выдачи пакета его копия сохраняется в выходной очереди до получения эхо-пакета. Узел-получатель, принимая пакет, создает эхо-пакет, направляемый отправителю. При возможности сохранить пакет в узле возвращается эхо-пакет “выполнено”, иначе возвращается эхо-пакет — “повтор”.
Когда возвращается эхо-пакет “выполнено”, соответствующий пакет посылки ликвидируется. Когда возвращается эхо-пакет “повтор”, то исходный пакет высылается снова.
Узел может послать много пакетов (вплоть до 64) прежде, чем будет получен ответный эхо-пакет. Эхо-пакеты могут приходить не в том порядке, в котором были посланы инициировавшие их пакеты, поэтому необходимы номера пакетов для установления соответствия между пакетами и эхо-пакетами.