

Коммутация
Сеть межсоединений состоит из коммутаторов и проводов, соединяющих их. На рисунке 8.5 изображена небольшая сеть межсоединений с четырьмя коммутаторами. В данном случае каждый коммутатор имеет 4 входных порта и 4 выходных порта. Кроме того, каждый коммутатор содержит несколько центральных процессоров и схемы соединения (на рисунке они показано не полностью). Задача коммутатора — принимать пакеты, которые приходят на любой входной порт, и отправлять пакеты из соответствующих выходных портов.
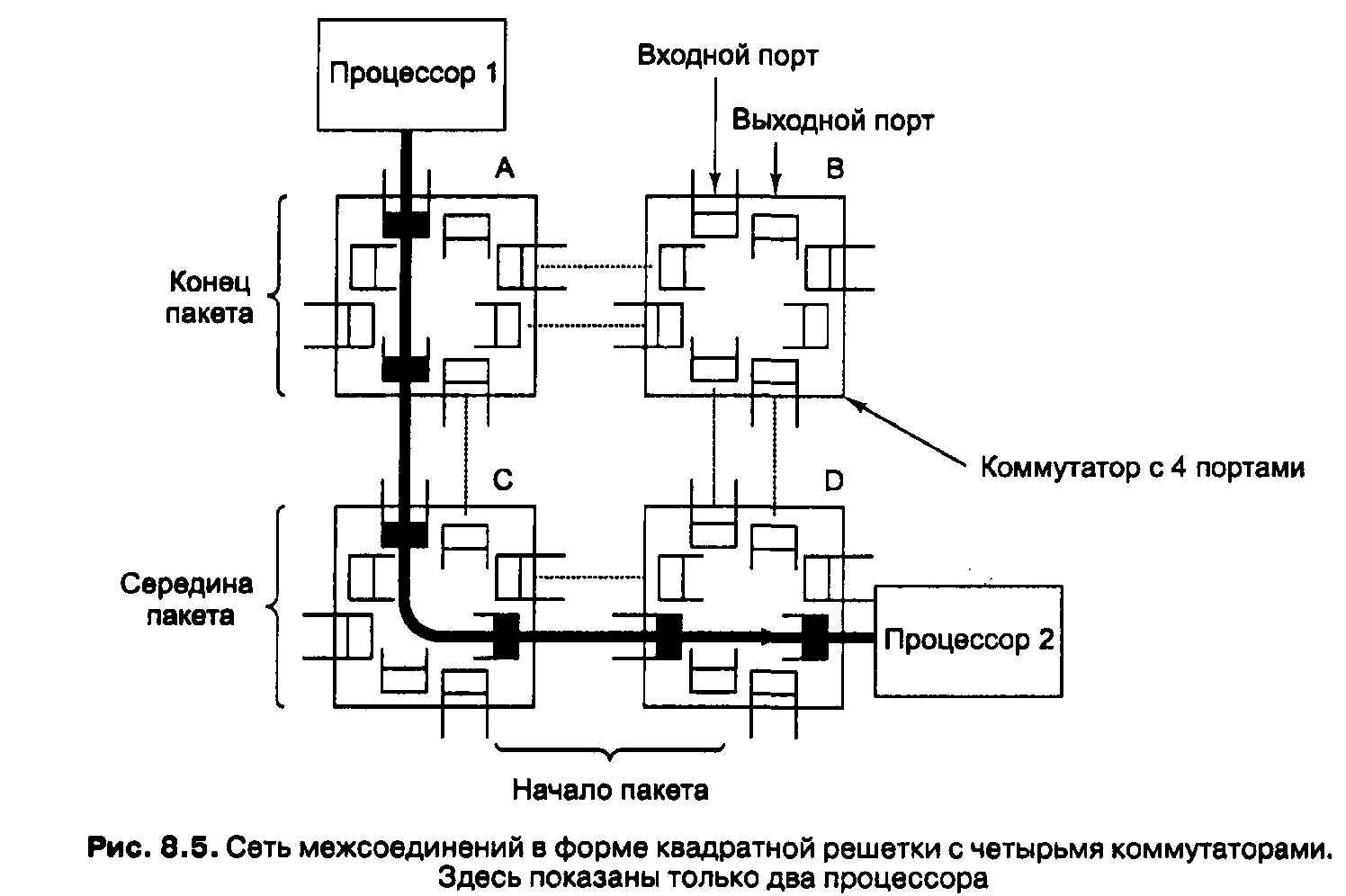
Каждый выходной порт связан с входным портом другого коммутатора через последовательный или параллельный канал (на рис. 8.5. это пунктирная линия). Последовательные каналы передают один бит единовременно. Параллельные каналы могут передавать несколько битов сразу. Существуют специальные сигналы для управления каналом. Параллельные каналы характеризуются более высокой производительностью, чем последовательные каналы с такой же тактовой часто-
той, но в них возникает проблема расфазировки данных (нужно быть уверенным, что все биты прибывают одновременно), и они стоят гораздо дороже.
Существует несколько стратегий переключения.
Первая из них — коммутация каналов. Перед тем как послать пакет, весь путь от начального до конечного пункта резервируется заранее. Все порты и буферы затребованы заранее, поэтому когда начинается процесс передачи, все необходимые ресурсы гарантированно доступны, и биты могут на полной скорости перемещаться от исходного пункта через все коммутаторы к пункту назначения. На рис. 8.5 показана коммутация каналов, где резервируются канал от процессора 1 к процессору 2 (черная жирная стрелка). Здесь резервируются три входных и три выходных порта.
Коммутацию каналов можно сравнить с перекрытием движения транспорта во время парада, когда блокируются все прилегающие улицы. При этом требуется предварительное планирование, но после блокирования прилегающих улиц парад может продвигаться на полной скорости, поскольку никакой транспорт препятствовать этому не будет. Недостаток такого метода состоит в том, что требуется предварительное планирование и любое движение транспорта запрещено, даже если парад (или пакеты) еще не приближается.
Вторая стратегия — коммутация с промежуточным хранением. Здесь не требуется предварительного резервирования. Из исходного пункта посылается целый пакет к первому коммутатору, где он хранится целиком. На рис. 8.6, а исходным пунктом является процессор 1, а весь пакет, который направляется в процессор 2, сначала сохраняется внутри коммутатора А. Затем этот пакет перемещается в коммутатор С, как показано на рис. 8.6, б. Затем весь пакет целиком перемещается в коммутатор D (рис. 8.6, в). Наконец, пакет доходит до пункта назначения — до процессора 2. Отметим, что никакого предварительного резервирования ресурсов не требуется.
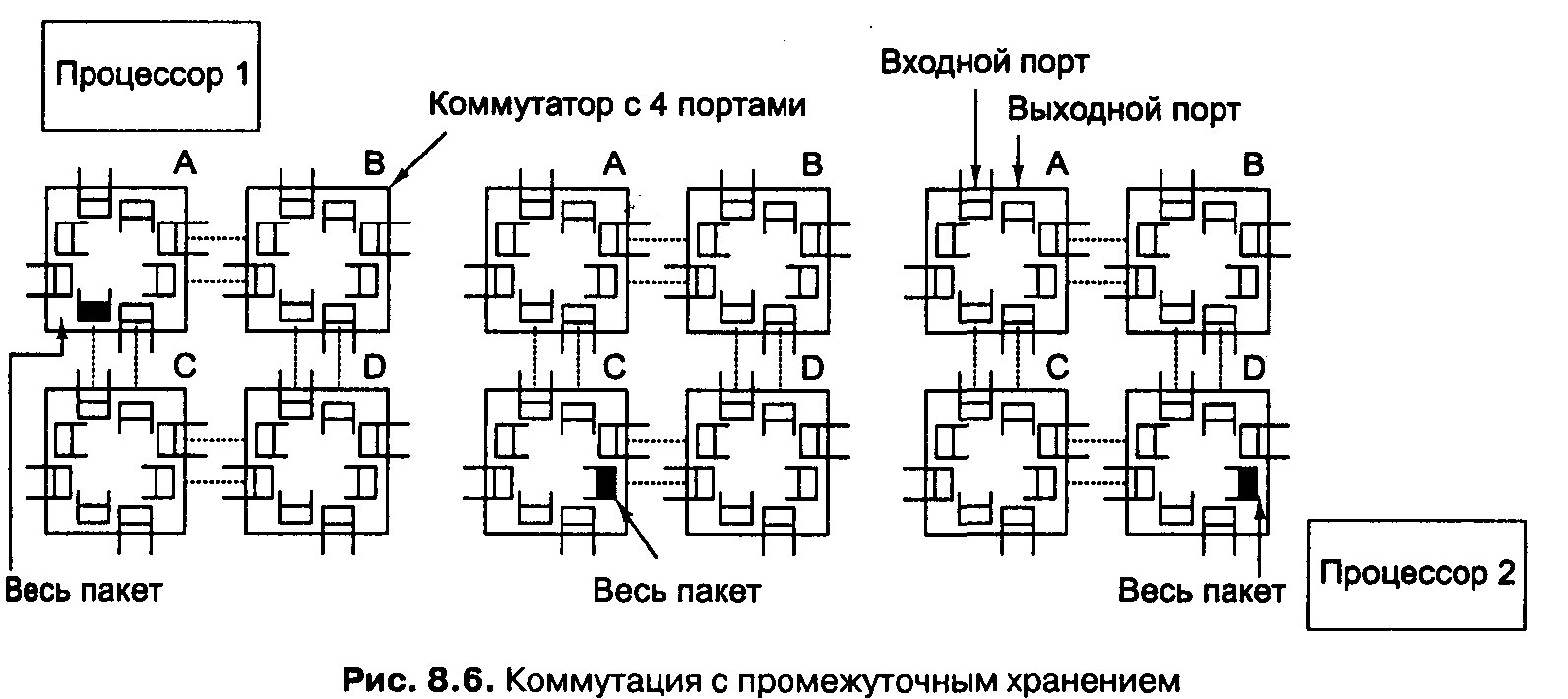
Коммутаторы с промежуточным хранением должны отправлять пакеты в буфер, поскольку когда исходный пункт (например, процессор, память или коммутатор) выдает пакет, требующийся выходной порт может быть в данный момент занят передачей другого пакета. Если бы не было буферизации, входящие пакеты, которым нужен занятый в данный момент выходной порт, пропадали бы. Применяется три метода буферизации. При буферизации на входе один или несколько буферов связываются с каждым входным портом в форме очереди типа FIFO («первым вошел, первым вышел»). Если пакет в начале очереди нельзя передать по причине занятости нужного выходного порта, этот пакет просто ждет своей очереди.
Однако если пакет ожидает, когда освободится выходной порт, то пакет, идущий за-ним, тоже не может передаваться, даже если нужный ему порт свободен. Ситуация называется блокировкой начала очереди. Проиллюстрируем ситуацию на примере. Представим дорогу из двух рядов. Вереница машин в одном из рядов не может двигаться дальше, поскольку первая машина в этом ряду хочет повернуть налево, но не может из-за движения машин другого ряда. Даже если второй и всем следующим за ней машинам нужно ехать прямо, первая машина в ряду препятствует их движению.
Проблему можно устранить с помощью буферизации на выходе.
В этой системе буферы связаны с выходными портами. Биты пакета по мере пребывания сохраняются в буфере, который связан с нужным выходным портом. Поэтому пакеты, направленные в порт т, не могут блокировать пакеты, направленные в порт п. И при буферизации на входе, и при буферизации на выходе с каждым портом связано определенное количество буферов. Если места недостаточно для хранения всех пакетов, то какие-то пакеты придется выбрасывать. Чтобы разрешить эту проблему, можно использовать общую буферизацию, при которой один буферный пул динамически распределяется по портам по мере необходимости. Однако такая схема требует более сложного управления, чтобы следить за буферами, и позволяет одному занятому соединению захватить все буферы, оставив другие соединения ни с чем. Кроме того, каждый коммутатор должен вмещать самый большой пакет и даже несколько пакетов максимального размера, а для этого потребуется ужесточить требования к памяти и снизить максимальный размер пакета.
Хотя метод коммутации с промежуточным хранением гибок и эффективен, здесь возникает проблема возрастающей задержки при передаче данных по сети межсоединений. Предположим, что время, необходимое для перемещения пакета по одному транзитному участку на рис. 8.6, занимает Т не. Чтобы переместить пакет из процессора 1 в процессор 2, нужно скопировать его 4 раза (в А, в С, в D и в процессор 2), и следующее копирование не может начаться, пока не закончится предыдущее, поэтому задержка по сети составляет 4Т. Чтобы выйти из этой ситуации, нужно разработать гибридную сеть межсоединений, объединяющую в себе коммутацию каналов и коммутацию пакетов. Например, каждый пакет можно разделить на части. Как только первая часть поступила в коммутатор, ее можно сразу направить в следующий коммутатор, даже если оставшиеся части пакета еще не прибыли в этот коммутатор.
Такой подход отличается от коммутации каналов тем, что ресурсы не резервируются заранее. Следовательно, возможна конфликтная ситуация в соревновании за право обладания ресурсами (портами и буферами). При коммутации без буферизации пакетов, если первый блок пакета не может двигаться дальше, оставшаяся часть пакета продолжает поступать в коммутатор. В худшем случае эта схема превратится в коммутацию с промежуточным хранением. При другом типе маршрутизации, так называемой «wonnhole routing» (червоточина), если первый блок не может двигаться дальше, в исходный пункт передается сигнал остановить передачу, и пакет может оборваться, будучи растянутым на два и более коммутаторов. Когда необходимые ресурсы становятся доступными, пакет может двигаться дальше.
Следует отметить, что оба подхода аналогичны конвейерному выполнению команд в центральном процессоре. В любой момент времени каждый коммутатор выполняет небольшую часть работы, и в результате получается более высокая производительность, чем если бы эту же работу выполнял один из коммутаторов.