

Память компьютерных систем
В современных КС используются следующие разновидности памяти.
Оперативная память
Разделяемая память
Чередуемая память
Оперативная память
Характеристики оперативной памяти и особенности ее устройства являются важнейшим фактором, от которого зависит быстродействие компьютера. Ведь даже при наличии быстрого процессора скорость выборки данных из памяти может оказаться невысокой, и именно эта невысокая скорость работы с оперативной памятью будет определять быстродействие компьютера.
Время
цикла работы с памятью
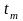 обычно
заметно больше, чем время цикла
центрального процессора
обычно
заметно больше, чем время цикла
центрального процессора
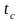 .
.
Если процессор
инициализирует обращение к памяти, она
будет занята в течение времени
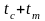 и в
течение этого промежутка времени ни
одно другое устройство, в том числе и
сам процессор, не смогут работать с
оперативной памятью.
и в
течение этого промежутка времени ни
одно другое устройство, в том числе и
сам процессор, не смогут работать с
оперативной памятью.
Таким образом, возникает проблема доступа к памяти.
Эта проблема решается специальной организацией оперативной памяти. Принята следующая классификация параллельных компьютеров по архитектуре подсистем оперативной памяти:
- системы с разделяемой памятью, у которых есть одна большая виртуальная память, и все процессоры имеют одинаковый доступ к данным и командам, хранящимся в этой памяти;
- системы с распределенной памятью, у которых каждый процессор имеет свою локальную оперативную память, и к этой памяти у других процессоров нет доступа.
Различие между разделяемой и распределенной памятью заключается в способе интерпретации адреса. Это различие можно пояснить на следующем примере. Пусть один из процессоров выполняет команду load r1, i (загрузить в регистр r1 данные из ячейки памяти i).
Если команда выполняется на компьютере с разделяемой памятью, номер ячейки i имеет одинаковый смысл для всех процессоров, т. е. i является глобальным адресом.
В системе с распределенной памятью ячейка i разная для различных процессоров и в регистры r1 по этой команде будут загружены разные значения.
Разделяемая память
Простейший способ создать многопроцессорный вычислительный комплекс с разделяемой памятью - взять несколько процессоров, соединить их общей шиной между собой и с оперативной памятью. Это - простой, но не самый лучший способ, поскольку, если один процессор принимает команду или передает данные, все остальные процессоры вынуждены переходить в режим ожидания.
Это приводит к тому, что, начиная с некоторого числа процессоров, быстродействие такой системы перестает увеличиваться при добавлении нового процессора.
В многопроцессорных вычислительных системах возникает проблема кэш-когерентности. Она заключается в том, что если двум или более процессорам понадобилось значение одной и той же переменной, оно будет храниться в виде нескольких копий в кэш-памяти всех процессоров. Один из процессоров может изменить это значение в результате выполнения своей команды и оно будет передано в оперативную память компьютера. Но в кэш-памяти остальных процессоров все еще хранится старое значение. Следовательно, необходимо обеспечить своевременное обновление данных в кэш-памяти всех процессоров компьютера.
Проблема кэш-когерентности может решаться программным путем - на уровне транслятора и операционной системы. Транслятор, например, может определять моменты безопасной синхронизации кэш-памяти при выполнении программы.
Другой подход основан на аппаратном решении проблемы кэш-когерентности. В этом случае применяются специальные протоколы, кэш-память используется более эффективно, все происходит "прозрачно" для программиста.
Протоколы каталогов реализуют сбор и учет информации о копиях данных в кэш-памяти. Эта информация хранится в специальной области оперативной памяти - каталоге.
Запросы проверяются с помощью каталога, затем выполняются необходимые пересылки данных. Использование данного подхода эффективно в больших системах со сложными схемами коммуникации.
Протоколы слежения распределяют "ответственность" за когерентность кэшей между контроллерами кэш-памяти. Контроллер определяет изменение содержания кэш-памяти и передает информацию об этом другим модулям кэш-памяти. Очевидно, в этом случае возрастает объем передаваемых данных. В некоторых системах используется адаптивная смесь обоих подходов.
Имеются различные реализации разделяемой памяти. Это, например, разделяемая память с дискретными модулями памяти.
Физическая память состоит из нескольких модулей, хотя виртуальное адресное пространство остается общим. Вместо общей шины в этом случае используется коммутатор, направляющий запросы от процессора к памяти. Такой коммутатор может одновременно обрабатывать несколько запросов к памяти, поэтому, если все процессоры обращаются к разным модулям памяти, быстродействие возрастает.
Чередуемая память
Чередуемая память разделяется на банки памяти. Принято соглашение о том, что ячейка памяти с номером i находится в банке памяти с номером i mod n, где n - количество банков памяти, a mod - операция вычисления остатка от деления. Таким образом, если имеется 8 банков памяти, то первому банку памяти будут принадлежать ячейки памяти с номерами 0, 8, 16, ..., второму - 1, 9, 17, ... и т. д. Запросы к различным банкам памяти могут обрабатываться одновременно. При достаточном количестве банков памяти скорость обмена данными между памятью и процессором может быть близка к идеальному значению - одно машинное слово за один такт работы процессора.
Ячейки памяти могут быть перенумерованы и непрерывным образом, т. е., скажем, в первом банке находятся ячейки с номерами от 0 до 255, во втором от 256 до 511 и т. д.
В векторных компьютерах обычно используется первый способ адресации, а в многопроцессорных комплексах с разделяемой памятью - второй.
Сети межсоединений в параллельных КС и их характеристики
Мультикомпьютеры связываются через сети межсоединений. Интересно отметить, что мультикомпьютеры и мультипроцессоры очень сходны в этом отношении, поскольку мультипроцессоры часто содержат несколько модулей памяти, которые также должны быть связаны друг с другом и с процессорами. Следовательно, многое из того, о чем мы будем говорить в этом разделе, применимо к обоим типам систем.
Основная причина сходства коммуникационных связей в мультипроцессоре и мультикомпьютере заключается в том, что в обоих случаях применяется передача сообщений. Даже в однопроцессорной машине, когда процессору нужно считать или записать слово, он устанавливает определенные линии на шине и ждет ответа.
Это действие представляет собой то же самое, что и передача сообщений: инициатор посылает запрос и ждет ответа.
В больших мультипроцессорах взаимодействие между процессорами и удаленной памятью почти всегда состоит в том, что процессор посылает в память сообщение, так называемый пакет, который запрашивает определенные данные, а память посылает процессору ответный пакет.
Сети межсоединений могут состоять максимум из пяти компонентов:
1. Центральные процессоры.
2. Модули памяти.
3. Интерфейсы.
4. Каналы связи.
5. Коммутаторы.
Процессоры и модули памяти мы уже рассматривали больше не будем к этому возвращаться.
Интерфейсы — это устройства, которые вводят и выводят сообщения из центральных процессоров и модулей памяти. Во многих разработках интерфейс представляет собой микросхему или плату, к которой подсоединяется локальная шина каждого процессора и которая может передавать сигналы процессору и локальной памяти (если таковая есть).
Часто внутри интерфейса содержится программируемый процессор со своим собственным ПЗУ, которое принадлежит только этому процессору. Обычно интерфейс способен считывать и записывать информацию в различные модули памяти, что позволяет ему перемещать блоки данных.
Каналы связи — это каналы, по которым перемещаются биты. Каналы могут быть электрическими или оптико-волоконными, последовательными (шириной 1 бит) или параллельными (шириной более 1 бита). Каждый канал связи характеризуется максимальной пропускной способностью (это максимальное число битов, которое он способен передавать в секунду). Каналы могут быть симплексными (передавать биты только в одном направлении), полудуплексными (передавать информацию в обоих направлениях, но не одновременно) и дуплексными (передавать биты в обоих направлениях одновременно).
Коммутаторы — это устройства с несколькими входными и несколькими выходными может быть с односторонним и двусторонним движением, она характеризуется определенной «скоростью передачи данных» (имеется в виду ограничение скорости движения) и имеет определенную ширину (число рядов). Перекрестки похожи на порты. Когда на входной порт приходит пакет, некоторые биты в этом пакете используются для выбора выходного порта, в который посылается пакет.
Размер пакета может составлять 2 или 4 байта, но может быть и значительно больше (например, 8 Кбайт).
Еще одно важное свойство сети межсоединений — это ее пропускная способность, то есть количество данных, которое она способна передавать в секунду.
Очень важная характеристика — бисекционная пропускная способность. Чтобы вычислить это число, нужно мысленно разделить сеть межсоединений на две равные (с точки зрения числа узлов) несвязанные части путем удаления ряда дуг из графа. Затем нужно вычислить общую пропускную способность дуг, которые мы удалили.
Существует множество способов разделения сети межсоединений на две равные части. Бисекционная пропускная способность — минимальная из всех возможных. Предположим, что бисекционная пропускная способность составляет 800 бит/с. Тогда если между двумя частями много взаимодействий, то общую пропускную способность в худшем случае можно сократить до 800 бит/с.
По мнению многих разработчиков, бисекционная пропускная способность — это самая важная характеристика сети межсоединений. Часто основная цель при разработке сета межсоединений — сделать бисекционную пропускную способность максимальной
Сети межсоединений можно характеризовать по их размерности.
Размерность определяется по числу возможных вариантов перехода из исходного пункта в пункт назначения.
Если выбора нет (то есть существует только один путь из каждого исходного пункта в каждый конечный пункт), то сеть нульмерная.
Если есть два возможных варианта (например, если можно пойти либо направо, либо налево),то сеть одномерна. Если есть две оси и пакет может направиться направо или налево либо вверх или вниз, то такая сеть двумерна и т. д.
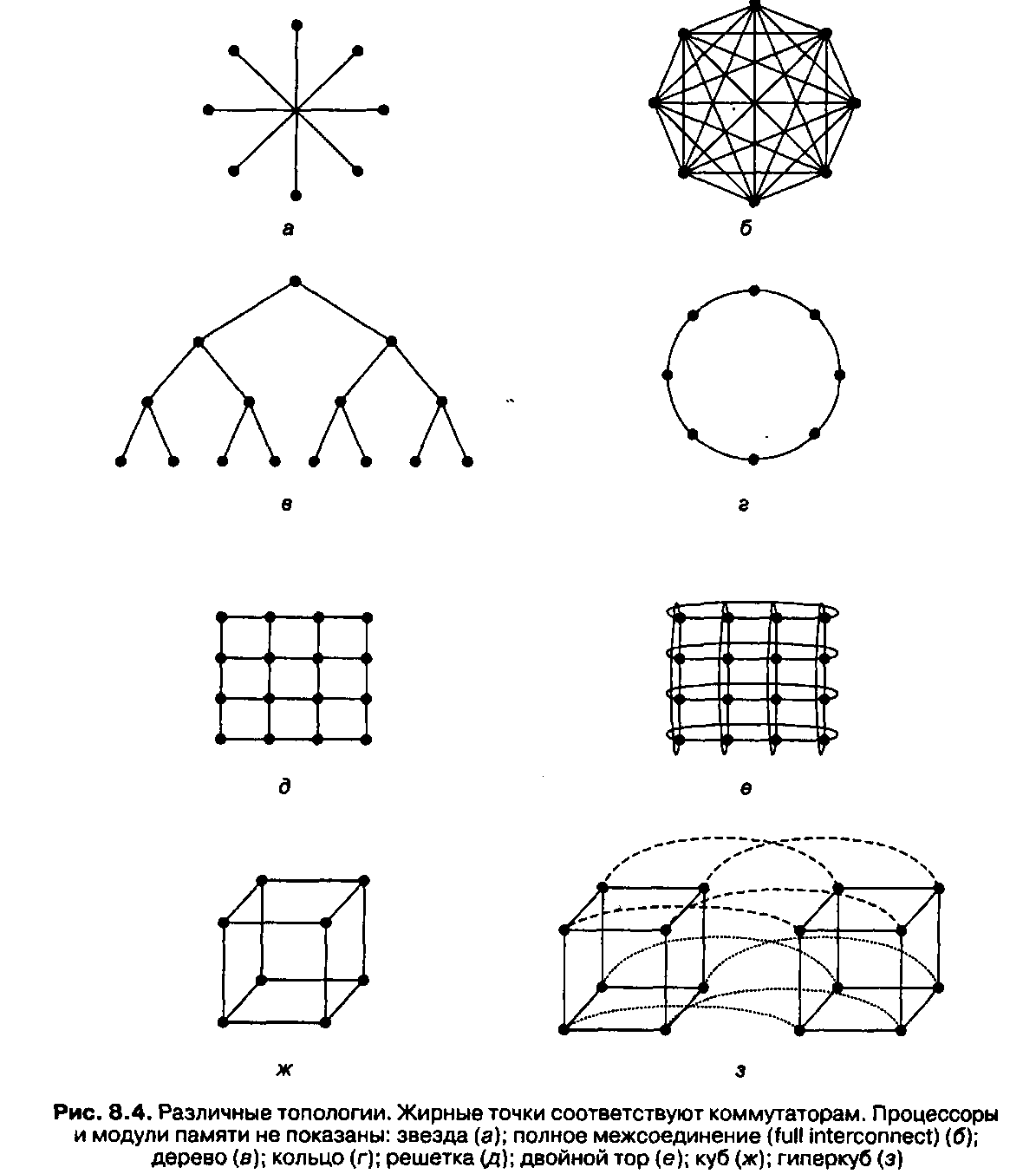
На рис. 8.4 показано несколько топологий. Здесь изображены только каналы связи (это линии) и коммутаторы (это точки). Модули памяти и процессоры (они на рисунке не показаны) подсоединяются к коммутаторам через интерфейсы.
На рис. 8.4, а изображена нульмерная конфигурация звезда, где процессоры и модули памяти прикрепляются к внешним узлам, а переключение совершает центральный узел. Такая схема очень проста, но в большой системе центральный коммутатор будет главным критическим параметром, который ограничивает производительность системы. И с точки зрения отказоустойчивости это очень неудачная разработка, поскольку одна ошибка в центральном коммутаторе может разрушить всю систему.
На рис. 8.4, б изображена другая нульмерная топология — полное межсоединение (full interconnect). Здесь каждый узел непосредственно связан с каждым имеющимся узлом. В такой разработке пропускная способность между двумя секциями максимальна, диаметр минимален, а отказоустойчивость очень высока (даже при утрате шести каналов связи система все равно будет полностью взаимосвязана). Однако для k узлов требуется k(k-1 )/2 каналов, а это совершенно неприемлемо для больших значений k.
На рис. 8.4, в изображена третья нульмерная топология — дерево. Здеь оновная проблема состоит в том, что пропускная способность между секциями равна пропускной способности каналов. Обычно у верхушки дерева наблюдается очень большой поток обмена информации, поэтому верхние узлы становятся препятствием для повышения производительности. Можно разрешить эту проблему, увеличив пропускную способность верхних каналов. Например, самые нижние каналы будут иметь пропускную способность Ь, следующий уровень — пропускную способность 2Ь, а каждый канал верхнего уровня — пропускную способность 4Ь.
Такая схема называется толстым деревом (fat tree). Она применялась в коммерческих мультикомпьютерах Thinking Machines' CM-5.
Кольцо (рис. 8.4, г) — это одномерная топология, поскольку каждый отправленный пакет может пойти направо или налево.
Решетка или сетка (рис. 8.4, д) — это двумерная топология, которая применяется во многих коммерческих системах. Она отличается регулярностью и применима к системам большого размера, а диаметр составляет квадратный корень от числа узлов (то есть при расширении системы диаметр увеличивается незначительно).
Двойной тор (рис. 8.4, е) является разновидностью решетки. Это решетка, у которой соединены края. Она характеризуется большей отказоустойчивостью и меньшим диаметром, чем обычная решетка, поскольку теперь между двумя противоположными узлами всего два транзитных участка.
Куб (рис. 8.4, ж) — это правильная трехмерная топология. На рисунке изображен куб 2х2х2, но в общем случае он может быть kxkxk.
На рис. 8.4, з показан четырехмерный куб, полученный из двух трехмерных кубов, которые связаны между собой. Можно сделать пятимерный куб, соединив вместе 4 четырехмерных куба. Чтобы получить 6 измерений, нужно продублировать блок из 4 кубов и соединить соответствующие узлы и т. д.; п-мерный куб называется гиперкубом. Эта топология используется во многих компьютерах параллельного действия, поскольку ее диаметр находится в линейной зависимости от размерности.
Другими словами, диаметр — это логарифм по основанию 2 от числа узлов, поэтому 10-мерный гиперкуб имеет 1024 узла, но диаметр равен всего 10, что дает очень незначительные задержки при передаче данных. Отметим, что решетка 32х32, которая также содержит 1024 узла, имеет диаметр 62, что более чем в шесть раз превышает диаметр гиперкуба. Однако чем меньше диаметр гиперкуба, тем больше разветвление и число каналов (и следовательно, тем выше стоимость). Тем не менее в системах с высокой производительностью чаще всего используется именно гиперкуб.
Характеристики графов межсоединений.
Коммутаторы для многопроцессорных вычислительных систем
Коммуникационные среды вычислительных систем (ВС) состоят из адаптеров вычислительных модулей (ВМ) и коммутаторов, обеспечивающих соединения между ними.
Используются как простые коммутаторы, так и составные, компонуемые из набора простых.
Простые коммутаторы могут соединять лишь малое число ВМ в силу физических ограничений, однако обеспечивают при этом минимальную задержку при установлении соединения.
Составные коммутаторы, обычно строящиеся из простых в виде многокаскадных схем с помощью линий «точка-точка», преодолевают ограничение на малое количество соединений, однако увеличивают и задержки.