

1) С неограниченным временем пребывания заявок;
2) С относительными ограничениями на время пребывания заявок;
3) С абсолютными ограничениями на время пребывания заявок;
В качестве критерия эффективности системы выбирается коэффициент потери качества функционирования из-за задержек обслуживания заявок, который характеризуется функцией штрафа.
Для системы с неограниченным временем пребывания заявок функция штрафа имеет вид :
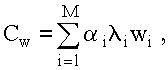 (3.1)
(3.1)
где i — штраф за задержку одной заявки типа i на единицу времени; i — интенсивность потока заявок типа i; wi - среднее время ожидания заявок типа i.
Для системы с относительными ограничениями на время пребывания заявок налагаются ограничения на средние времена пребывания (ожидания) заявок всех типов и задаются в виде неравенства:
![]()
где wi* - предельное ограничение на время ожидания заявки типа i,
i = 1,...M.
Для системы с абсолютными ограничениями на время пребывания заявок накладываются более жесткие требования. Показателем качества функционирования таких систем при одномерном потоке заявок может служить вероятность превышения допустимого времени ожидания Pr(W>w*). Чем меньше эта вероятность, тем выше качество функционирования ВС.
В случае М потоков заявок потеря качества функционирования характеризуется функцией штрафа:
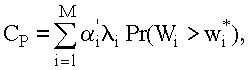
где i' - штраф за превышение одной заявкой типа i допустимого ограничения.
Произведение i' iPr(Wi > wi*) определяет штраф за превышение допустимого ограничения на время ожидания заявок типа i, поступающих в систему за единицу времени. Использование указанного критерия вызывает трудности, связанные с необходимостью нахождения вероятностей Pr(Wi > wi*). Они определяются, если известны законы распределения времени ожидания для различных типов заявок. Аналитический вид законов распределения может быть получен лишь для простейших дисциплин обслуживания, а в случае более сложных дисциплин обслуживания ориентируются на использование только двух первых моментов распределения. Это обстоятельство ограничивает возможность применения указанного критерия.
В процессе исследования на статистических моделях установлено, что для широкого класса дисциплин обслуживания распределение времени ожидания можно аппроксимировать выражением вида:
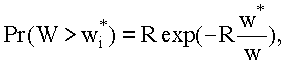
где w - среднее время ожидания заявок в очереди; w*- предельно допустимое время ожидания; R - суммарная загрузка процессора.
Задача синтеза СРВ может быть разбита на 3 этапа.
На первом этапе синтеза определяется нижняя оценка быстродействия процессора, обеспечивающая как минимум существование стационарного режима, а при наличии ограничений на время ожидания заявок - существование некоторой дисциплины обслуживания, удовлетворяющей этим ограничениям. В стационарном режиме, когда времена ожидания и пребывания заявок в системе имеют конечные значения, суммарная загрузка системы от всех входящих потоков должна быть меньше единицы,
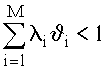 ,
(3.2)
,
(3.2)
Среднее время обслуживания заявки i определяется значением :
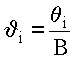 ,
(3.3)
,
(3.3)
где i - трудоемкость обслуживания заявок (программ); B - среднее быстродействие процессора.
С учетом (3.2) и (3.3) для систем с неограниченным временем пребывания минимально необходимое быстродействие процессора, при котором существует стационарный режим работы системы, определяется из условия :
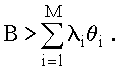 (3.4)
(3.4)
При наличии относительных ограничений на время пребывания заявок минимально необходимое быстродействие определяется из условия:
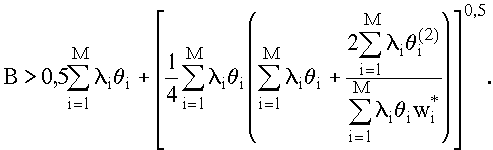 (3.5)
(3.5)
При wi* выражение (3.5) совпадает с выражением (3.4).
На втором этапе выбирается дисциплина обслуживания заявок, обеспечивающая минимум значения критерия эффективности:
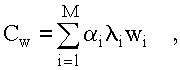
где произведение i iwi определяет штраф за задержку обслуживания заявок i - го типа, поступающих в систему за единицу времени; Cw - штраф за задержку в обслуживании всех заявок.
Если штрафы для всех заявок одинаковы, то
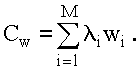
Задержки, т.е. времена ожидания w1, w2, …, wM зависят от двух факторов: быстродействия процессора В и дисциплины обслуживания заявок. Увеличение быстродействия приводит к уменьшению всех значений, w1, w2, …, wM а следовательно, к уменьшению величины Cw. Максимальная эффективность системы достигается при бесконечном быстродействии процессора, что свидетельствует о некорректности использования критерия 3.1 для выбора быстродействия процессора.
Этот критерий может быть использован в задаче выбора дисциплины обслуживания. Дисциплина обслуживания считается оптимальной для определенной системы, если ей соответствует минимальное значение Cw по сравнению с другими дисциплинами обслуживания.
Задача оптимального назначения приоритетов сводится к расположению приоритетов в порядке убывания величины
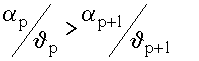
![]() .
(3.6)
.
(3.6)
Выражение (3.6) - условие выигрыша от введения относительных или абсолютных приоритетов в сравнении с бесприоритетными дисциплинами обслуживания.
В случае равных коэффициентов p в выражении (3.6) получим условие p < p+1 выигрыша при использовании дисциплин обслуживания с относительными приоритетами: заявкам с меньшей длительностью обслуживания должны присваиваться более высокие относительные приоритеты. Для дисциплин обслуживания с абсолютными приоритетами приоритеты должны назначаться в порядке, обратном номерам потоков заявок.
На третьем этапе определяется оптимальное быстродействие процессора. Для выбранной оптимальной дисциплины обслуживания необходимо уточнить быстродействие процессора, обеспечивающее заданное качество обслуживания заявок при минимально возможном простое процессора.
В качестве критерия эффективности при таком подходе может быть использован функционал вида
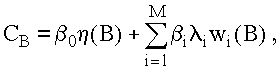 (3.7)
(3.7)
где - коэффициент простоя; i - некоторые весовые коэффициенты, задаваемые при проектировании системы. Задание весовых коэффициентов должно осуществляться исходя из назначения системы и требований, предъявляемых к ней.
В системах с жесткими требованиями ко времени реакции должны присваиваться более высокие значения коэффициентов i, а системы, основное требование к которым - минимум материальных затрат, должны иметь наибольшее значение 0.
Функция CB имеет минимум, которому соответствует оптимальное значение быстродействия процессора Bopt. Для системы с неограниченным временем пребывания заявок оно равно
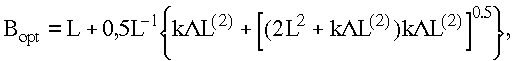 (3.8)
(3.8)
где k - некоторый коэффициент пропорциональности, равный
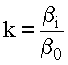 ;
;
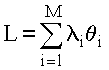 ;
;
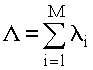 ;
;

Для системы, к которой не предъявляются никакие требования на время пребывания заявок, кроме требований, чтобы все заявки были обслужены за конечное время и для которых k=0, оптимальное значение Bopt совпадает с нижней оценкой быстродействия процессора. Это означает, что быстродействие процессора для таких систем должно выбираться только из условия максимальной загрузки системы. Но чем выше требования, предъявляемые к качеству обслуживания заявок, т.е. чем больше k, тем более высокое быстродействие процессора должно быть выбрано по сравнению с нижней оценкой.
Для систем с относительными ограничениями на время пребывания заявок, кроме ограничений на время ожидания заявок, задается ограничение на коэффициент простоя процессора * и задача определения оптимального быстродействия формулируется следующим образом: найти такое значение быстродействия B, которое обеспечивает минимум критерия эффективности CB (3.7) при ограничениях:
![]()
При использовании системы с бесприоритетной дисциплиной обслуживания и относительными ограничениями на время пребывания заявок оптимальное быстродействие процессора определяется на основе решения неравенства:
Оптимальное значение быстродействия процессора получают при условии:
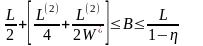 ,
(6)
,
(6)
Где:
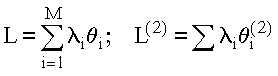 ;
;
w* - среднее предельно допустимое время ожидания заявок;
* - ограничение на коэффициент простоя процессора.
Решением этой системы неравенств является область S допустимых значений быстродействия процессора B (рисунок 3.1). Верхней границе B соответствует зависимость B = B( *)
нижней - зависимость B = B(w*)
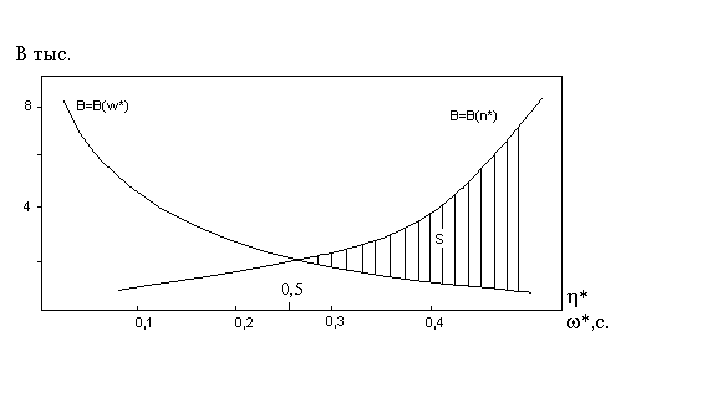
Рисунок 3.1 - Область допустимых значений быстродействия процессора
В случае абсолютных ограничений на время пребывания заявок к настоящему времени аналитических зависимостей определения оптимального быстродействия не получено, поскольку задача сводится к решению трансцендентных уравнений.
Особенности КС АСУ ТП
К компьютерным системам реального времени АСУ ТП предъявляются повышенные требования по надежности и производительности. Так, время наработки на отказ в таких системах должно быть не менее сотен тысяч часов, а производительность должна быть достаточной для управления сложными динамическими процессами с числом контуров управления несколько десятков и даже сотен.
Интерфейсы таких систем должны обеспечивать подключение большого числа датчиков и управляющих устройств дискретного и аналогового типа, причем эти устройства могут быть территориально удалены от центра контроля и управления на расстояния от нескольких сотен метров до десятков километров.
Важную роль в системах для АСУ ТП играет подсистема связи оператора-технолога с контролируемым объектом. При ее построении используются средства отображения информации в виде традиционных мнемосхем, а также используются графические средства компьютера для построения на экране монитора структуры контролируемого объекта и его параметров.
Используются для этой цели специализированные графические пакеты, позволяющие наряду с функциями контроля подавать управляющие воздействия на объект контроля.
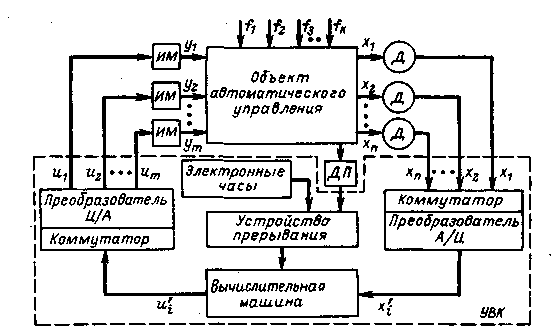
Рис. 1. Упрощенная структурная схема АСУ ТП с управляющим вычислительным комплексом
Этапы развития КС АСУ ТП
На первом этапе развития АСУ ТП основными средствами автоматизации нефтегазовой отрасли стран СНГ были пневмоавтоматика и громоздкие телемеханические системы, а централизованные автоматизированные системы управления технологическими процессами (АСУТП) строились на базе специализированных управляющих вычислительных комплексов (УВК) типа
М-6000, СМ-2,СМ-4.
С середины 80-х годов в системах управления все чаше стали использоваться персональные компьютеры. Сначала они играли роль инженерных станций для конфигурирования DCS (Distributed Control System) и технической диагностики. С появлением персональных компьютеров в промышленном нсполненни и развитием программного обеспечения их все чаще стали использовать в качестве операторских станций в системах мониторинга и диспетчерского управления.
С середины 90-х годов в системах управления постепенно стала проявляться тенденция сосредоточения функций управления на т.н. промышленных компьютерах. Это было связано с резким падением цен на компьютеры и комплектующие изделия, платы ввода/вывода и средства коммуникации, а также с появлением универсального прикладного программного обеспечения типа SCADA и средств программирования контроллеров на базе IBM PC.
Использование IBM PC-платформы в контроллерах за рубежом называется "softlogic" (софтлоджик), а сами PC-совместимые контроллеры - "soft РLС"(софтПЛК).
Появление микропроцессоров положило начало эры программируемых логических контроллеров - ПЛК (Programmable Logic Controller,- PLC). Первые PLC пришли на замену дискретным системам управления на базе электромеханических реле.
В соответствии с требованиями задач, для решения которых они предназначались, для PLC было характерно преобладание дискретных входных и выходных сигналов (поэтому контроллеры и назвали логическими), высокое быстродействие, слаборазвитое программное обеспечение, не способное выполнять операции с плавающей запятой и функции ПИД-регулирования.
Одна из сфер применения PLC - системы телемеханики. PLC в этих системах играют роль контролируемых пунктов (КП) и называются RTU (Remote Terminal Unit - удаленное терминальное устройство). Для дистанционной передачи данных PLC (RTU) снабжаются дополнительными коммуникационными модулями и программным обеспечением, реализующим какой-либо протокол передачи данных по проводным или радиоканалам. В нефтегазовой отрасли они нашли широкое применение при автоматизации процессов добычи и транспорта нефти и газа.
Несколько позже на замену аналоговым приборам (регуляторам) пришли DCS-системы (Distributed Control System) - распределенные системы управления), адаптированные для управления непрерывными технологическими процессами. Это уже не просто контроллер, а целый комплекс технических и программных средств:
набор процессоров с четко распределенными функциями (например, управляющий, интерфейсный, прикладной);
рабочие станции (станции оператора);
каналы связи;
ПО для конфигурирования (программирования) контроллеров и для создания человеко-машинного интерфейса.
В 80-е годы оба рассмотренных выше класса микропроцессорных систем (на базе PLC и DCS) имели свои сферы применения и своих производителей.
В силу своей дороговизны DCS применялись, как правило, в крупных системах управления. В некоторых случаях в крупных системах PLC использовались как подсистема для решения задач противоаварийной зашиты и блокировок.
Затем PLC стали приобретать некоторые свойства, которые позволили им успешно внедриться в сферу небольших систем управления непрерывными процессами.
К этим свойствам можно отнести достаточно развитый ввод/вывод аналоговых сигналов и возможности ПИД-регулирования. Такие контроллеры получили название SLC (Single Loop Controller), так как они позволяли реализовать 1-2 контура регулирования. Подобные контроллеры были в номенклатуре многих производителей DCS и некоторых фирм- производителей PLC.
Современные многоуровневые системы АСУ ТП.
Большое число современных систем контроля и управления имеет распределенный характер и имеет иерархическую структуру, приведенную на рис.1
Как правило, это двух- или трехуровневые системы, и именно на этих уровнях реализуется непосредственное управление технологическими процессами. Специфика каждой конкретной системы управления определяется используемой на каждом уровне программно - аппаратной платформой.
- Нижний уровень - уровень объекта (контроллерный) - включает различные датчики (измерительные преобразователи) для сбора информации о ходе технологического процесса, электроприводы и исполнительные устройства для реализации регулирующих и управляющих воздействий. Датчики поставляют информацию локальным контроллерам (PLC), которые могут обеспечить реализацию следующих функций:
сбор, первичная обработка и хранение информации о состоянии оборудования и параметрах технологического процесса;
автоматическое логическое управление и регулирова-ние; исполнение команд с пункта управления
Для рассредоточенных объектов, таких, как нефтяные и газовые промыслы, а также для объектов транспорта нефти и газа применяют SCADA-системы.
Задачей таких систем является обеспечение автоматического дистанционного наблюдения и дискретного управления функциями большого количества распределенных устройств (часто находящихся на большом расстоянии друг от друга и от диспетчерского пункта).
Количество возможных устройств, работающих под управлением систем диспетчерского контроля и управления, велико и может достигать нескольких сотен.
Для этих систем наиболее характерной задачей является сбор и передача данных, которая реализуется дистанционно расположенными терминальными устройствами (RTU).
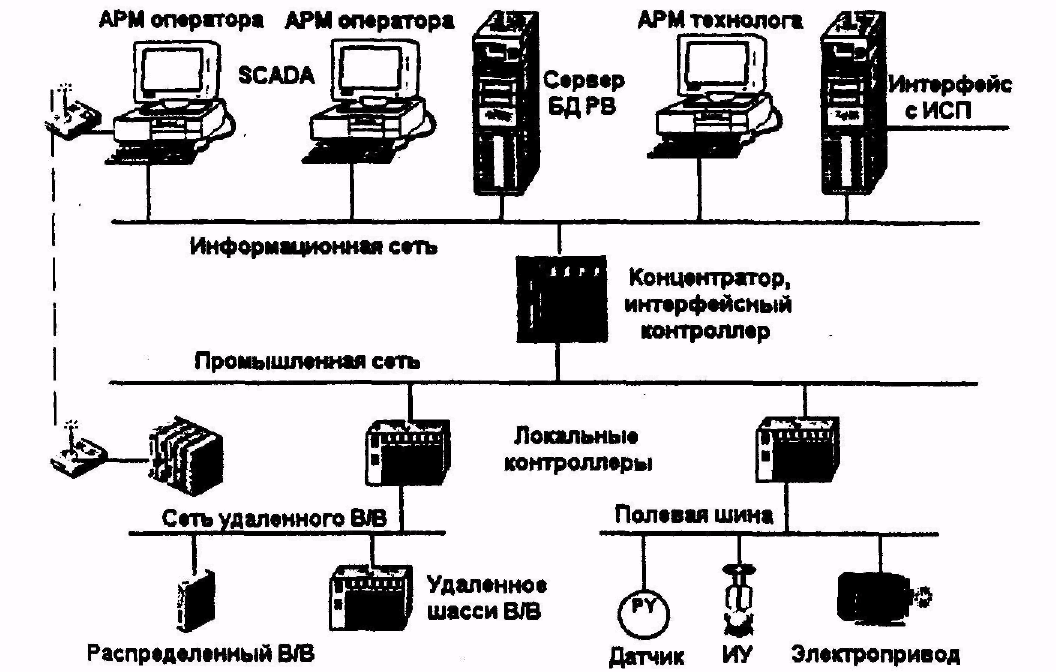
Рис. 2.1 Обобщенная архитектура системы КС АСУ ТП
самодиагностика работы программного обеспечения и состояния
самого контроллера;
- обмен информацией с пунктами управления.
Так как информация в контроллерах предварительно обрабатывается и частично используется на месте, существенно снижаются требования к пропускной способности каналов связи.
В качестве локальных PLC в системах контроля и управления различными технологическими процессами в настоящее время применяются контроллеры как отечественных, так и зарубежных производителей. На рынке представлены многие десятки и даже сотни типов контроллеров, способных обрабатывать от нескольких десятков до нескольких тысяч и даже десятков тысяч переменных.
Разработка, отладка и исполнение программ контроллерами осуществляется с помощью специализированного программного обеспечения . Это, прежде всего, многочисленные пакеты программ для программирования контроллеров, предлагаемые производителями аппаратных средств. К этому же классу инструментального ПО относятся и пакеты ISaGRAF (CJ International France), InConrol (Wonderware, USA), Paradym 31 (Intellution, USA), имеющие открытую архитектуру.
Среди наиболее популярных производителей аппаратных и программных средств для АСУ ТП можно назвать фирмы ABB, Advantech, Allen-Bradley, Bristol Babcock, Control Microsystems, Fisher-Rosemount, Foxboro, GE Fanuc, Hewlett Packard, Hitachi, Honeywell, Koyo, Mitsubishi, Motorola, Omron, PEP Modular Computer, Samsung, Schneider Electric, Siemens, Toshiba, Yokogawa и другие.
Ознакомимся боле детально с аппаратно-программными средствами GE Fanuc.
Информация с локальных контроллеров может направляться в сеть диспетчерского пункта непосредственно, а также через контроллеры верхнего уровня (см. рис.2-1). В зависимости от поставленной задачи контроллеры верхнего уровня (концентраторы, коммуникационные контроллеры) реализуют различные функции. Некоторые из них перечислены ниже:
сбор данных с локальных контроллеров;
обработка данных, включая масштабирование;
поддержание единого времени в системе;
синхронизация работы подсистем;
организация архивов по выбранным параметрам;
обмен информацией между локальными контроллерами и верхним уровнем;
работа в автономном режиме при нарушениях связи с верхним уровнем;
резервирование каналов передачи данных и др.
Верхний уровень - диспетчерский пункт (ДП) - включает одну или несколько станций управления, представляющих собой автоматизированное рабочее место (АРМ) диспетчера/оператора. Здесь же может быть установлен сервер базы данных.
На верхнем уровне могут быть организованы рабочие места (компьютеры) для специалистов, в том числе и для инженера по авто матизации (инжиниринговые станции). Часто в качестве рабочих станций используются ПЭВМ типа IBM PC различных конфигураций.
Станции управления предназначены для отображения хода технологического процесса и оперативного управления. Эти задачи и призвано решать прикладное программное обеспечение SCADА, ориентированное на разработку и поддержание интерфейса между диспетчером/оператором и системой управления, а также на обеспечение взаимодействия с внешним миром.
- Все аппаратные средства системы управления объединены между собой каналами связи. На нижнем уровне контроллеры взаимодействуют с датчиками и исполнительными устройствами, а также с блоками удаленного распределенного ввода/вывода с помощью специализированных сетей удаленного ввода/вывода и полевых шин.
Связующим звеном между локальными контроллерами и контроллерами верхнего уровня, а часто и пультами оператора являются управляющие сети.
Связь различных АРМ оперативного персонала между собой, с контроллерами верхнего уровня, а также с вышестоящим уровнем осуществляется посредством информационных сетей
Основные технические характеристики контроллеров и программно-технических комплексов.
Современный рынок контроллеров и программно-технических комплексов весьма разнообразен. Выбор наиболее приемлемого варианта автоматизации представляет собой многокритериальную задачу, решением которой является компромисс между стоимостью, техническим уровнем, надежностью, комфортностью, затратами на сервисное обслуживание, полнотой программного обеспечения и многим другим. Одной из популярных систем контроля и управления технологическими процессами является комплекс GE Fanuk.