

§ 3.9. Обслуживание заявок в групповом режиме
Если управляющая программа включается в работу каждый раз, когда закончено обслуживание очередной заявки, то говорят, что обслуживание выполняется в одиночном режиме. В этом режиме на обслуживание выбирается всегда только одна заявка; управляющая программа исполняется процессором многократно, что приводит к большим затратам процессорного времени на диспетчирование. Непроизводительные затраты процессорного времени можно уменьшить, если назначать на обслуживание сразу группу заявок, стоящих в очереди и имеющих максимальный в данной ситуации приоритет. Такой режим обслуживания заявок называется групповым.
Циклическое обслуживание. При групповом режиме может использоваться бесприоритетное обслуживание заявок, называемое циклическим. При циклическом обслуживании для заявок типа 1, ..., М выделяются очереди O1, ..., ОM (рис. 3.25). Сначала обслуживаются все заявки из очереди O1 затем из очереди O2 и т. д. После обслуживания очереди ОM процесс обслуживания вновь возвращается к заявкам из очереди О1. Такой порядок обслуживания характеризуется минимальными затратами на диспетчирование.

Рис. 3.25. Циклическое обслуживание заявок
Аналитическое исследование циклического обслуживания заявок в групповом режиме при произвольном количестве входных потоков весьма сложно и приводит к громоздким результатам. Однако при М=2 известны выражения для средних значений времени ожидания в очереди заявок каждого потока при условии, что время обслуживания заявок имеет произвольное распределение:

Анализируя выражения (3.20), можно сделать вывод, что выражения для времени ожидания симметричны относительно индексов входящих потоков. Среднее время ожидания в очереди любой заявки из суммарного потока одинаково и равно

где =1+2.
Дисциплина обслуживания с чередующимися приоритетами. При групповом обслуживании очередям заявок могут присваиваться относительные приоритеты. Тогда по окончании обслуживания всех заявок из очереди Oi управляющая программа последовательно проверяет состояние очередей O1, ..., ОM. Если первой непустой является очередь Оj, то система начинает обслуживать эту очередь, пока она не будет исчерпана. Дисциплина обслуживания в групповом режиме с относительными приоритетами заявок называется дисциплиной с чередующимися приоритетами.
Дисциплина обслуживания по расписанию. В цифровых управляющих системах (ЦУС) для групповой обработки заявок широко используется обслуживание по расписанию, которое организуется следующим образом. Расписание задается в виде (i1, i2, ..., iG), где ig(g=1, ..., G) — номер очереди, равный 1, ..., H, и G — длина цикла. Например, если число очередей H=4, то расписание может иметь следующий вид: (1, 2, 1, 3, 1, 2, 1, 4, 1, 2, 1, 3). Здесь длина цикла G=12. Расписание задает порядок обращения к очередям заявок. Так из приведенного расписания следует, что цикл обслуживания начинается с очереди 1, затем обслуживается очередь 2, затем вновь очередь 1 и т. д. Цикл заканчивается обслуживанием очереди 3, после чего ЦУС повторяет цикл обслуживания. За один цикл обслуживания производится шесть обращений к очереди 1, три обращения к очереди 2, два обращения к очереди 3 и одно — к очереди 4. Таким образом, очередь 1 обслуживается наиболее интенсивно и среднее время ожидания заявок типа 1 уменьшается по сравнению с заявками других типов.
Обслуживание по расписанию отличается гибкостью, позволяющей широко варьировать приоритетами заявок. Расписание строится следующим образом. Заявки, поступающие в систему, разделяются на классы. В один класс объединяются разнотипные заявки, для хранения которых выделяется одна очередь. За счет этого уменьшается количество очередей и сокращаются непроизводительные затраты времени на диспетчирование. Число очередей (классов) заявок ЗНМ, где М — число типов заявок, обслуживаемых системой. Число классов Н не может быть меньше трех, поскольку при Н=1 расписание вырождается в бесприоритетную дисциплину обслуживания, при Н=2 имеет место диспиплина циклического обслуживания.
Обозначим через gh — число обращений к h-и очереди в одном цикле. Тогда величину
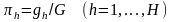
можно трактовать как вероятность обращения к h-й очереди. Очевидно, что
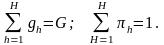
Определим понятие подцикла, которое в дальнейшем понадобится для построения расписания. Пусть h* — номер очереди, для которой число обращений в цикле максимально, т. е. gh*=max (g1, ...,gH). Подциклом называют обращения к очередям, заключенные между двумя последовательными обращениями к очереди h*, включая также одно обращение к этой очереди. Значение gh* определяет количество подциклов в расписании.
Например, для расписания
(1, 2, 1, 3, 1, 2, 1, 4, 1, 2, 1, 3, 1, 2, 1, 5, 1, 2, 1, 3, 1, 2, 1, 4, 1, 2, 1, 3, 1, 2) (3.21)
число обращений gh к очередям h=1, ..., 5 равно соответственно 15, 8, 4, 2, 1 и длина цикла G=g1+...+g5=30. В таком случае вероятности обращения к очередям 1=15/30; ...; 5=1/30. Отсюда следует, что h*=1 и количество подциклов для данного расписания будет 15.
Поскольку нумерация очередей производится таким образом, что g1>g2>...>gH;, то max (gl ..., gH)=g1 и, следовательно, h* = 1.
К расписанию предъявляют следующие требования: 1) в цикле два последовательных обращения к одной очереди не должны быть расположены рядом, так как в противном случае второе обращение всегда будет осуществляться к пустой очереди; 2) обращения к одной и той же очереди должны быть равномерно распределены по всему циклу, чтобы при каждом обращении к одной и той же очереди число заявок в ней было приблизительно постоянным.
Каноническое расписание. Каноническое расписание — расписание, для которого число обращений к очередям определяется следующим образом:
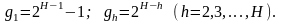 (3.22)
(3.22)
Тогда количество обращений к каждой последующей очереди в два раза меньше, чем к предыдущей, и к последней очереди с номером Н производится одно обращение за цикл. Длина цикла канонического расписания
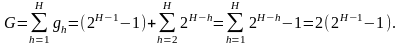
Для расписаний с параметрами (3.22) указанные требования всегда могут быть выполнены. Расписание (3.21) — пример канонического расписания.
Расписание целесообразно представлять в виде матрицы S=[sij]. Число строк в матрице равно количеству подциклов в расписании, а число столбцов — количеству классов заявок. Элементы матрицы 0 или 1. Если в подцикле i=l, ..., gh* должно производиться обращение к классу (очереди) h=1, ..., Н, то элемент sih=l, в противном случае элемент sih=0. Расписанию (3.21) соответствует следующая матрица:
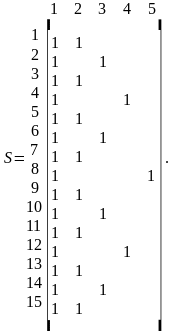
Здесь количество единиц в каждом столбце матрицы соответствует количеству обращений gh к классу заявок h за один цикл работы системы.
Получение точных аналитических зависимостей, связывающих время ожидания заявок с числом обращений, — сложная задача, которая не может быть решена классическими методами теории массового обслуживания. Однако, если и удалось бы получить точные аналитические зависимости, то по аналогии с циклическим обслуживанием вычисления по этим формулам были бы весьма громоздкими и трудоемкими и были бы' связаны с использованием ЭВМ. При этом практически полностью терялись бы основные преимущества аналитического исследования по сравнению со статистическим моделированием. Поэтому более целесообразно проводить исследование таких систем в два этапа. Первый этап связан с получением приближенных аналитических зависимостей, на основе которых могут быть оценены основные характеристики обслуживания и выбрано конкретное расписание. На втором этапе проводится исследование системы на статистической модели при различных предположениях о характере потоков и обслуживания заявок. В отношении времени ожидания можно предположить, что его значение для каждого класса заявок h будет обратно пропорционально вероятности обращения к очереди данного класса: h~1/h, т. е. с уменьшением вероятности h время ожидания заявок класса h увеличивается. Однако это совсем не означает, что заявки класса с меньшей вероятностью обращения всегда будут иметь большее время ожидания. Исследования показали, что время ожидания заявок различных классов в большей степени зависит от соотношений между параметрами потоков и механизма обслуживания разнотипных заявок, т. е. заявки, принадлежащие классу с большей вероятностью обращения, в некоторых случаях могут иметь среднее время ожидания, превышающее время ожидания заявок класса с меньшей вероятностью обращения.
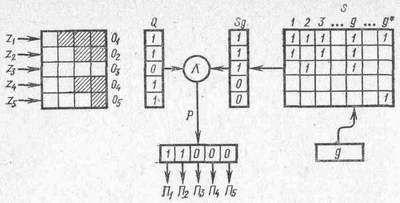
Рис. 3.26. Организация обслуживания заявок на основе расписания
Реализация обслуживания по расписанию. Обслуживание заявок на основе расписания организуется по схеме, показанной на рис. 3.26. Заявки z1, ..., z5, относящиеся к классам 1, ..., 5, ожидают обслуживания в очередях О1, ..., О5. С целью сокращения непроизводительных затрат на просмотр пустых очередей используется слово состояния очередей Q. Разряды ql, ..., q5 слова Q принимают значения qi=0, если очередь Oi пуста; qi=1, если очередь Oi не пуста. Расписание представляется булевой матрицей S. В данном случае строки матрицы соответствуют классам h=l,...,5 заявок, а столбцы — подциклам расписания. Подцикл, управляющий обслуживанием заявок, выделяется счетчиком g. В начальном состоянии g=l и затем значение g изменяется в циклическом порядке: g=l,2,..., g*, 1, 2, ..., g*, 1, 2, ... .
Управляющая программа функционирует следующим образом.
1. Из матрицы расписания S выбирается столбец Sg, выделяемый текущим значением счетчика g. Столбец Sg представляется двоичным словом.
2. Слова Q и Sg умножаются поразрядно. В результате формируется слово P=Q^Sg, разряды которого определяют не пустые очереди, обрабатываемые в подцикле g.
3. Управляющая программа последовательно просматривает разряды i=l, 2, ..., 5 слова Р. Если i-й разряд слова равен 1, то инициируется программа Пi, которая начинает обрабатывать все заявки из очереди Oi, после чего управление вновь передается управляющей программе и просматривается очередной разряд слова Р.
4. После просмотра всех разрядов слова Р значение счетчика циклически увеличивается на единицу и выполняется переход к пункту 1.
Управление по расписанию целесообразно применять в системах с большой интенсивностью потока заявок — порядка 1·102 с-1 и более — и широким диапазоном ограничений на времена ожидания заявок. В этом случае затраты процессорного времени на диспетчирование вполне измеримы и многочисленность вариантов распределения единиц в матрице расписания позволяет подобрать такое управление порядком обслуживания, при котором фактические времена ожидания хорошо приближаются к требуемым.