

Сегодняшняя архитектура метакомпьютерной среды
Подводя итог рассмотрению проблем создания метакомпьютерного ПО, можно сделать вывод о реальной на сегодняшний день архитектуре (рис.8). Это два уровня, первый, локальный, включает:
— систему управления пакетной обработкой (LSF, LoadLeveler, Condor, DQS, PBS)[6,7]; — распределенную файловую систему (NFS, DFS, AFS) — систему эмуляции распределенной общей памяти.
На роль второго, глобального уровня претендует Globus, интегрирующий функции управления ресурсами, запуска заданий, глобальной файловой системы и безопасности. Однако, эта далеко не завершенная среда, практически все из перечисленных подсистем нуждаются в существенной доработке и, возможно, в новых подходах
Взаимосвязь метакомпьютинга с общими проблемами развития системного по
Общее соображение, обосновывающее общезначимость технологий, развиваемых в рамках метакомпьютерного направления, состоит в том, что современные ОС во все большей степени становятся завязаны на Сеть, ориентирусь на коллективные и мобильные формы работы пользователей с прямым доступом к общей информации и ПО. Это определяет общую направленность движения.
Во-вторых, на массовом рынке наметилась тенденция в сторону параллелизации и серийно выпускаемых архитектур (рядовыми стали многопроцессорные RISC-серверы и ПК с 4 — 8 процессорами Intel), и ОС, и работающих в них приложений. Все ведущие производители, выпуская свои ОС, делают одну версию для всего ряда машин — от рабочих станций до суперкомпьютеров, так что фактически даже на простейших однопроцессорных компьютерах есть как базовая, так и инструментальная поддержка параллельных вычислений.
Сетевые технологии коммерческих ОС — JAVA, удаленный вызов процедур RPC, объектные методы доступа CORBA, DCOM, система X Window, прикладные протоколы HTTP и FTP, модель клиент—сервер — сыграли колоссальную роль, показав возможности сетей и введя их в повседневную практику. Становится, однако, понятно, что они решают далеко не все проблемы, а часть средств оказалась чрезмерно ориентированной на конкретные приложения (к примеру протокол HTTP).
Метакомпьютерный подход, ставя проблему создания полной среды и инфраструктуры для сетевых вычислений, определяет один из возможных контекстов, в которым перечисленные методы могут занять свое место. Конкретно, интерес представляют работы по: глобальным файловым системам, системам сертификации и авторизации пользователей, оптимизации сетевой передачи данных, управлению ресурсами, планированию и диспетчеризации процессов.
Проекты метакомпьютинга
Распределенные вычисления в Интернет
Это подтверждается и тем, что хотя в проекте PACI в основном участвуют исследователи из академических учреждений, они работают в тесном сотрудничестве с промышленными разработчиками новой техники и ПО. Кроме того, ряд самых известных компаний (Sun, IBM и даже Microsoft) инвестируют в собственные проекты по очень похожим темам.
Операционные системы для распределенных вычислений
Исследователи изучают мир распределенных вычислений, в котором пользователи, находящиеся в различных офисах, могут работать с одним и тем же набором географически распределенных ресурсов. Такие исследования привели к появлению известных технологий: одноранговые (peer-to-peer, P2P), повсеместные (pervasive) и «кочующие» (nomadic) вычисления.
Проект Globe (Global Object Based Environment), выполняемый в университете Вридже (Голландия), посвящен разработке сети, использующей распределенные объекты. Основное значение таких проектов, как Globe, заключается в том, что они открывают путь к разработке действительно распределенных Internet-приложений.
Проект Opus американского университета Дюка стал продолжением проекта WebOS, выполнявшегося в Калифорнийском университете в Беркли. Opus призван предоставить основанный на идее перекрытия (overlay) набор утилит для управления наборами узлов в сетевой инфраструктуре, которая динамически резервирует ресурсы — вычислительные мощности, полосу пропускания, пространство жесткого диска — для узлов, пославших запросы в соответствии с разнообразными сетевыми характеристиками и требованиями приложений.
Массачусетский технологический институт выступает координатором проекта Project Oxygen, который был инициирован агентством DARPA, компаниями Delta Electronics, Hewlett-Packard, Nokia, NTT и Philips Electronics. Данный проект представляет собой попытку объединить беспроводные и иные технологии для создания распределенной сети, которая будет способна предоставить пользователям персональные вычислительные ресурсы, вне зависимости от того, где они находятся в настоящий момент.
Хотя все эти три проекта сами по себе не являются операционными системами, в них предпринята попытка построить единую прозрачную распределенную операционную среду, в которой все ресурсы могли бы функционировать как локальные.
GLOBE
Проект Globe (http://www.cs.vu.nl/~steen/globe) посвящен созданию крупных распределенных систем с помощью разделяемых объектов и связанных с ними методов. Разработчики могут генерировать приложения с использованием программного обеспечения промежуточного слоя, а не создавать сетевые программы непосредственно на базе транспортного уровня, как это происходит сейчас.
Активные копии объектов, которые взаимодействуют на одноранговой основе, будут доступны одновременно на всех машинах в распределенной системе, и все пользователи смогут вызывать методы объектов. Подход, основанный на концепции P2P, позволит системам работать без централизованного хранилища объектов, что дает возможность сократить сетевой трафик и избежать ошибок, связанных с недоступностью хранилища.
Globe расширяет функциональность распределенных систем и увеличивает скорость за счет выполнения таких операций, как возвращение информационного наполнения Web-страницы, получение сообщения электронной почты, предоставление доступа к файлу или поиск имени ресурсов в каталоге.
Объекты Globe состоят из пяти компонентов: подобъект управления, контролирующий клиентские запросы; подобъект связи, который поддерживает взаимодействие между объектами; подобъект тиражирования, управляющий связью тиражированных объектов; подобъект защиты, который контролирует права доступа и наличие объектов; подобъект семантики, реализующий действия объектов.
Разработчик будет создавать подобъект семантики. Другие подобъекты будут либо браться из библиотеки, либо генерироваться во время компиляции в соответствии с требованиями объекта.
«Самое главное отличие между объектами Globe и другими объектами состоит в том, что Globe предлагает поддержку объектов, которые физически распределены по разным машинам, — объяснил ван Стин. — Таким образом, состояние объекта может тиражироваться и распределяться между множеством серверов объектов».
В отличие от других типов распределенных объектов, каждый объект Globe управляет тем, как его состояние тиражируется, переносится и иным образом распространяется между машинами. Другими словами, объектам Globe не придется использовать для выполнения этих функций другое приложение или брокер объектных запросов. Таким образом, единая модель объектов Globe может предоставить универсальный метод для тиражирования, доставки информации и предоставления услуг, вне зависимости от базовой платформы.
Ван Стин считает, что поскольку, объекты Globe предоставляют распределенные службы, они могут заменить многочисленные современные подходы и стандарты для Web-служб на базе XML для предоставления служб по Internet.
OPUS
Opus (http://www.cs.duke.edu/~dkostic/publications/opus-poster-sosp.pdf) базируется на проекте WebOS, который был реализован в университете Беркли с целью предоставления распределенным приложениям служб операционной системы, в том числе механизмов обнаружения ресурсов и управления ими, удаленного выполнения процессов, аутентификации и защиты.
После завершения проекта в Беркли в 1998 году Ребекка Брейнард, Джефф Часе, Дежьян Костик, Адольфо Родригес и Амин Вахдат из университета Дюка использовали концепции WebOS для разработки Opus. В этом проекте также принимают участие Техасский университет в Остине и Вашингтонский университет.
Opus добавляет к оболочке WebOS механизм перекрытия (overlay), который позволяет приложениям прозрачным образом передавать базовой сети свои требования на ресурсы, а затем использовать предоставленные ресурсы.
Это крайне важно, поскольку на одной машине разработчики приложений могут для предоставления служб использовать возможности локальной операционной системы. Однако в распределенной системе, разработчики приложений должны сами создавать службы в соответствии с множеством стандартов и множеством серверов приложений, что требует больших усилий со стороны программиста и немалых системных ресурсов.
Opus решает эту проблему, предоставляя по Internet базовые службы операционных систем, необходимые для создания приложений, которые являются распределенными, доступными, масштабируемыми и динамически реконфигурируемыми.
Данная технология, таким образом, предлагает оболочку для предоставления одноранговых служб, при этом давая одноранговым приложениям на базе Internet большую часть функциональности, которую, как правило, можно обнаружить только в традиционных клиент-серверных приложениях.
Авторы Opus разрабатывают для этого универсальный подход, а не настраиваемое решение для реализации оверлея для конкретного приложения или сетевого ресурса. Подход проекта, основанный на идее перекрытия, предоставляет разработчикам общий интерфейс промежуточного программного обеспечения.
В Opus перекрытия служат в качестве абстракции API для доступа к сетевым ресурсам и их использования в соответствии с различными требованиями приложений и сетевыми характеристиками, такими как имеющаяся полоса пропускания. Opus предоставляет приложению доступ к сетевым ресурсам даже при изменении требований программы и сетевых условий, чего, как правило, не в состоянии предложить современные распределенные системы.
Opus позволит получить широкий доступ к системным ресурсам Internet. Как подчеркнул Амин Вахдат, производители могли бы использовать коммерческие варианты реализации этой технологии для предоставления пользователям вычислительных ресурсов как коммунальной услуги через Сеть.
|
Рис. 1. Архитектура Opus. Проект Opus, реализуемый в университете Дюка, добавляет к распределенным системам механизм оверлея, который позволяет приложениям прозрачным образом передавать базовой сети требования на ресурсы. Нижний уровень описывает базовые уровни ресурсов, имеющиеся в системе. Средний уровень определяет необходимые ресурсы и обеспечивает их предоставление. Уровень самоконтроля определяет, какие узлы должны быть зарезервированы приложению и поддерживает уровни производительности |
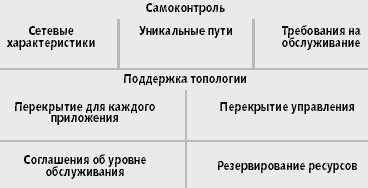
В архитектуре Opus (рис. 1) механизм overlay работает с имеющимися сетевыми ресурсами. Администратор сети определяет базовое резервирование ресурсов, которые система может использовать, при этом провайдер сетевых услуг обязуется обеспечить минимально доступные уровни обслуживания.
На уровне поддержки топологии перекрытия для каждого приложения указываются ресурсы, которые необходимы определенному типу приложений, в то же время управляющий механизм проверяет перекрывающие узлы и поддерживает параметры связи и производительности.
Наконец, уровень самоконтроля проверяет сетевые характеристики, оценивает пути доступа к ресурсам в поисках наиболее эффективного пути и определяет, какие перекрывающиеся узлы Opus (и соответствующая функциональность) должны быть зарезервированы для конкретного приложения.
PROJECT OXYGEN
Авторы Project Oxygen (http://oxygen.lcs.mit.edu/) разработали план создания подхода для реализации повсеместных распределенных вычислений, который позволяет предоставлять ресурсы пользователям там и тогда, когда те в них нуждаются, а не только, когда пользователи находятся возле своих компьютеров. Цель состоит в том, чтобы сделать вычисления функцией инфраструктуры, а не просто набора отдельных устройств.
Oxygen сейчас работает с инфраструктурой карманных устройств и рабочих станций, связанных с помощью локальных сетей в стандарте IEEE 802.11b и сетей Fast Ethernet.
Эта система использует Migrate, разработанную в Массачусетском технологическом институте архитектуру поддержки мобильных и использующих временные соединения сетевых приложений и позволяет унаследованным приложениям адаптироваться к мобильным средам. Пользователи могут переносить активное TCP-соединение между различными IP-адресами, посылая новые SYN-пакеты (которые устанавливают виртуальные соединения и синхронизируют номера последовательностей пакетов в начале TCP-соединения), если доступны возможности Migrate.
Программное обеспечение Oxygen — это, главным образом, результат академических проектов MIT. К примеру, разработчики используют IOA (input/output automation — «автоматизация ввода/вывода»), язык программирования и набор инструментальных средств, предназначенный для описания и создания надежных распределенных систем. IOA позволяет системным разработчикам описывать архитектуры на различных уровнях абстракции, от высокоуровневой спецификации общего поведения до низкоуровневых версий, которые легко преобразуются в программный код.
Разработчики проекта реализуют некоторый вариант технологии Oxygen в Intelligent Room, интерактивной среде со встроенными вычислениями, которая участвует в деятельности пользователей. Например, наборы микрофонов и камер позволяют Intelligent Room «прислушиваться» к пользователям, «наблюдать», что они делают, и прозрачным образом предоставлять информационные и коммуникационные ресурсы, которые им необходимы.
Интеллектуальные инструментальные средства эскизирования и проектирования дают пользователям возможность выражать свои идеи, а Intelligent Room их записывает. Другой инструментарий позволяет выполнять совместную работу. Программная инфраструктура на базе агентов автоматически выполняет множество задач, которые поддерживают работу инструментария.
В конечном итоге, ученые планируют создать множество использующих естественные языки визуальных интерфейсов для доступа к вычислительным и коммуникационным ресурсам.
Возможно, самым важным новым фактором при разработке операционной системы для распределенных вычислений является возникновение Web-служб, представленных платформой Microsoft .NET и рядом подходов на базе Java, таких как Open Net Environment (ONE) компании Sun Microsystems. Пока не существует единой инфраструктуры для Web-служб, эта технология уже пользуется большой популярностью на предприятии.
Web-службы предлагают набор нейтральных к платформе технологий, предназначенных для упрощения предоставления сетевых служб по intranet и Internet. По существу, Web-службы объединяют ПК, другие устройства, базы данных и сети в виртуальные вычислительные структуры, с которыми пользователи могут работать через браузеры. Очевидно, что эта концепция во многом затрагивает те же аспекты, что и, как предполагается, должны охватывать операционные системы для распределенных вычислений.
Ден Кузнецки, вице-президент компании IDC, отметил, что хотя проекты Globe, Opus и Project Oxygen весьма интересны, не стоит рассчитывать, что в ближайшем будущем они приведут к созданию коммерческих продуктов.
Стивен Воган-Николс (sjvn@vna1.com) — независимый журналист, специализирующийся на вопросах технологий.

Stiven J. Vaughan-Nichols. Developing the Distributed-Computing OS. IEEE Computer, September 2002. IEEE Computer Society, 2002, All rights reserved. Reprinted with permission.
Причины реализации проектов, посвященных распределенным ОС
Хотя все три основных проекта, посвященные созданию распределенных операционных систем (Globe университета Вридже, Opus университета Дюка и Project Oxygen Массачусетского технологического института), разрабатываются научными учреждениями, они решают задачи, определяемые требованиями коммерческого рынка. Эти требования могут становиться все более настойчивыми по мере роста популярности распределенных систем и по мере того, как компании будут все чаще использовать их для решения критически важных задач.
Все три проекта также ориентированы на унифицированный, универсальный, а не на внутренний подход к созданию операционных сред для распределенных вычислений. До недавнего времени многие организации разрабатывали свои собственные Web-технологии, касающиеся различных аспектов таких сред, к которым, в частности, относятся DCOM (модель распределенных объектных компонентов) корпорации Microsoft и протокол Internet inter-ORB, предложенный CORBA. Попытки стандартизовать этот процесс оборачивались политической борьбой.
Поход промежуточного программного обеспечения, реализуемый в Globe, позволяет создавать распределенную вычислительную инфраструктуру на базе Internet, которая опирается на универсальный формат объектов. Точно также проект Project Oxygen призван предоставить универсальную оболочку. Еще одна причина реализации этих трех проектов заключается в том, что необходимо создавать систему, в которой вычислительные ресурсы по всей сети предоставляются пользователям по требованию, в чем и состоит цель проекта Opus. Отрасль стремится к той же цели, но за счет внутренних решений.