

5.3. Варианты архитектуры клиент-сервер
Разделение на три логических уровня, обсуждавшееся в предыдущем пункте, наводит на мысль о множестве вариантов физического распределения по отдельным компьютерам приложений в модели клиент-сервер. Простейшая организация предполагает наличие всего двух типов машин.
Клиентские машины, на которых имеются программы, реализующие только пользовательский интерфейс или его часть.
Серверы, реализующие все остальное, то есть уровни обработки и данных.
Проблема подобной организации состоит в том, что на самом деле система не является распределенной: все происходит на сервере, а клиент представляет собой не что иное, как простой терминал. Существует также множество других возможностей, наиболее употребительные из них мы сейчас рассмотрим.
Многозвенные архитектуры
Один из подходов к организации клиентов и серверов — это распределение программ, находящихся на уровне приложений, описанном в предыдущем пункте, по различным машинам, как показано на рис. 1.20 . В качестве первого шага мы рассмотрим разделение на два типа машин: на клиенты и на серверы, что приведет нас к физически двухзвенной архитектуре (physically two-tiered architecture).
Один из возможных вариантов организации — поместить на клиентскую сторону только терминальную часть пользовательского интерфейса, как показано на рис. 1.20, а, позволив приложению удаленно контролировать представление данных.
Альтернативой этому подходу будет передача клиенту всей работы с пользовательским интерфейсом (рис. 1.20, б). В обоих случаях мы отделяем от приложения графический внешний интерфейс, связанный с остальной частью приложения (находящейся на сервере) посредством специфичного для данного приложения протокола. В подобной модели внешний интерфейс делает только то, что необходимо для предоставления интерфейса приложения.
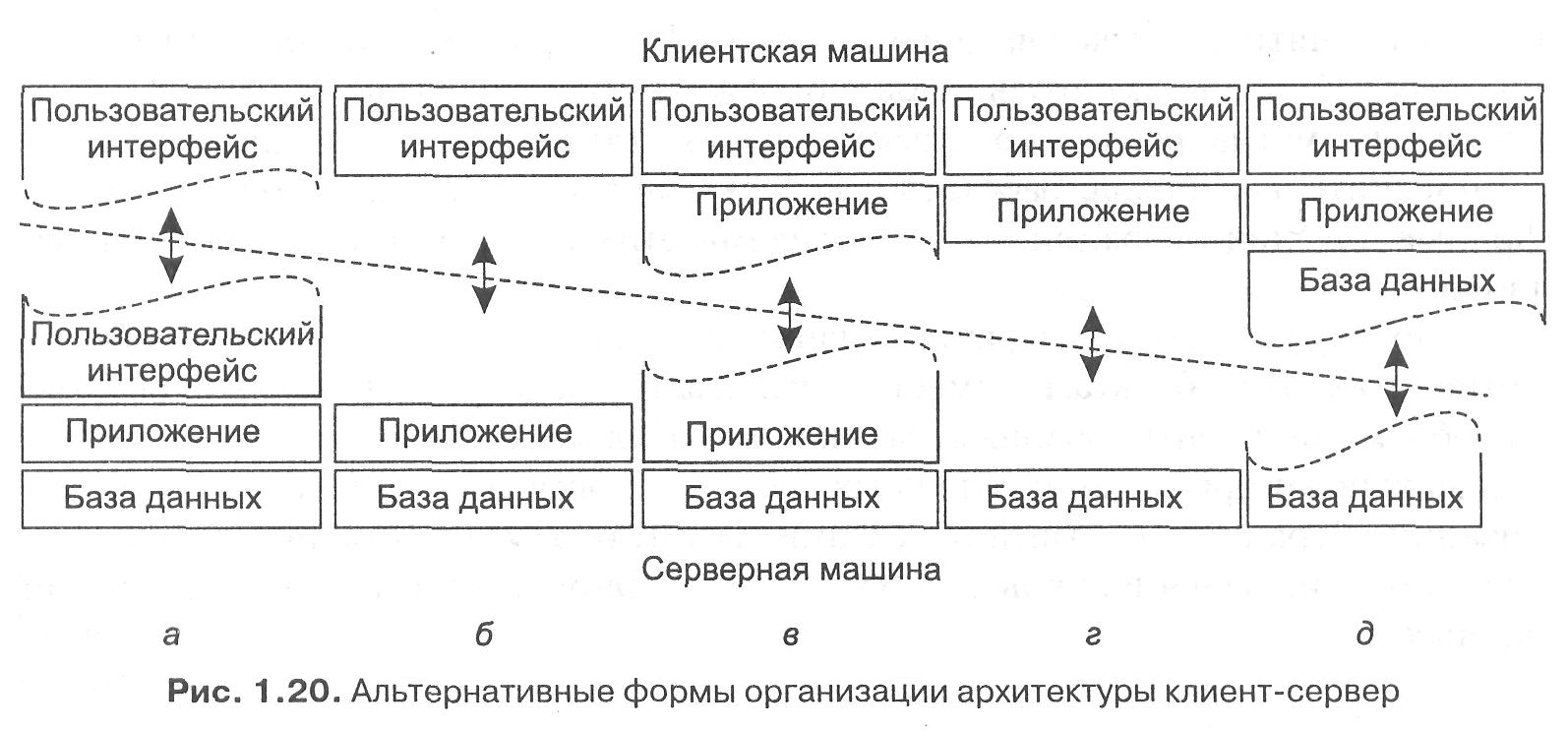
Продолжим линию наших рассуждений. Мы можем перенести во внешний интерфейс часть нашего приложения, как показано на рис. 1.20, в. Примером может быть вариант, когда приложение создает форму непосредственно перед ее заполнением. Внешний интерфейс затем проверяет правильность и полноту заполнения формы и при необходимости взаимодействует с пользователем. Другим примером организации системы по образцу, представленному на рис. 1.20, в, может служить текстовый процессор, в котором базовые функции редактирования осуществляются на стороне клиента с локально каптируемыми или находящимися в памяти данными, а специальная обработка, такая как проверка орфографии или грамматики, выполняется на стороне сервера.
Во многих системах клиент-сервер популярна организация, представленная на рис. 1.20, г и д. Эти типы организации применяются в том случае, когда клиентская машина — персональный компьютер или рабочая станция — соединена сетью с распределенной файловой системой или базой данных.
Большая часть приложения работает на клиентской машине, а все операции с файлами или базой данных передаются на сервер. Рисунок 1.20, д отражает ситуацию, когда часть данных содержится на локальном диске клиента. Так, например, при работе в Интернете клиент может постепенно создать на локальном диске огромный кэш наиболее часто посещаемых web-страниц.
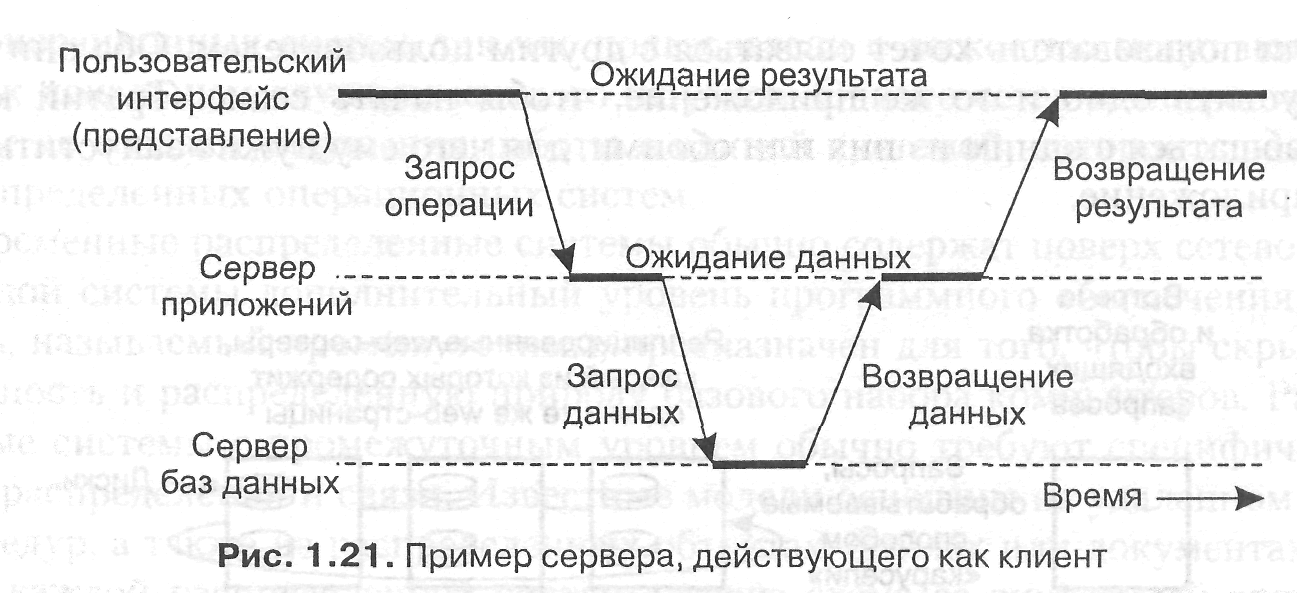
Рассматривая только клиенты и серверы, мы упускаем тот момент, что серверу иногда может понадобиться работать в качестве клиента. Такая ситуация, отраженная на рис. 1.21, приводит нас к физически трехзвенной архитектуре (physically three-tiered architecture).
В подобной архитектуре программы, составляющие часть уровня обработки, выносятся на отдельный сервер, но дополнительно могут частично находиться и на машинах клиентов и серверов. Типичный пример трехзвенной архитектуры — обработка транзакций. В этом случае отдельный процесс — монитор транзакций — координирует все транзакции, возможно, на нескольких серверах данных.
Современные варианты архитектуры
Многозвенные архитектуры клиент-сервер являются прямым продолжением разделения приложений на уровни пользовательского интерфейса, компонентов обработки и данных. Различные звенья взаимодействуют в соответствии с логической организацией приложения. Во множестве бизнес-приложений распределенная обработка эквивалентна организации многозвенной архитектуры приложений клиент-сервер. Мы будем называть такой тип распределения вертикальным распределением (vertical distribution). Характеристической особенностью вертикального распределения является то, что оно достигается размещением логически различных компонентов на разных машинах.
Это понятие связано с концепцией вертикального разбиения (vertical fragmentation), используемой в распределенных реляционных базах данных, где под этим термином понимается разбиение по столбцам таблиц для их хранения на различных машинах .
Однако вертикальное распределение — это лишь один из возможных способов организации приложений клиент-сервер, причем во многих случаях наименее интересный.
В современных архитектурах распределение на клиенты и серверы происходит способом, известным как горизонтальное распределение (horizontal distribution). При таком типе распределения клиент или сервер может содержать физически разделенные части логически однородного модуля, причем работа с каждой из частей может происходить независимо. Это делается для выравнивания загрузки.
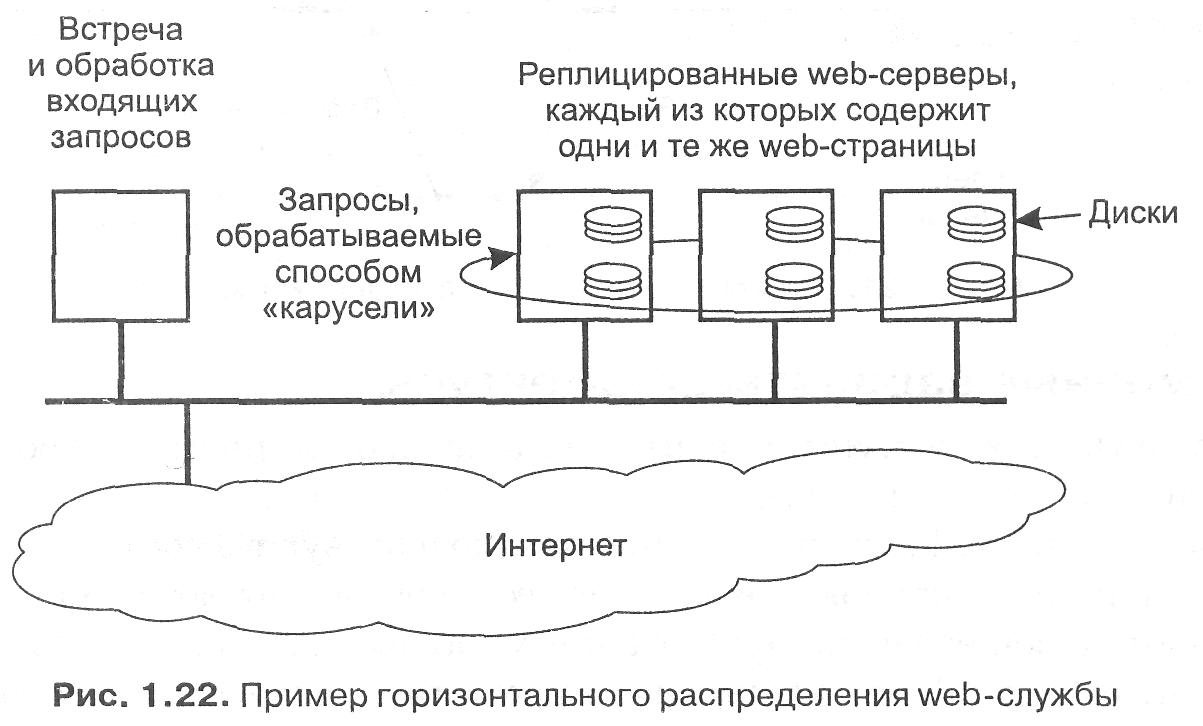
В качестве распространенного примера горизонтального распределения рассмотрим web-сервер, реплицированный на несколько машин локальной сети, как показано на рис. 1.22. На каждом из серверов содержится один и тот же набор web-страниц, и всякий раз, когда одна из web-страниц обновляется, ее копии незамедлительно рассылаются на все серверы. Сервер, которому будет передан приходящий запрос, выбирается по правилу «карусели» (round-robin). Эта форма горизонтального распределения весьма успешно используется для выравнивания нагрузки на серверы популярных web-сайтов.
Таким же образом, хотя и менее очевидно, могут быть распределены и клиенты. Для несложного приложения, предназначенного для коллективной работы, мы можем не иметь сервера вообще. В этом случае мы обычно говорим об одноранговом распределении (peer-to-peer distribution). Подобное происходит, например, если пользователь хочет связаться с другим пользователем. Оба они должны запустить одно и то же приложение, чтобы начать сеанс. Третий клиент может общаться с одним из них или обоими, для чего ему нужно запустить то же самое приложение.
Метакомпьютинг:вычислительная ифраструктура будущего
Проекты_метакомпьютинга. Тенденции развития компьютерной индустрии определяются разнообразными факторами: научными открытиями, новыми промышленными технологиями, конъюктурой на финансовых рынках. , главной движущей силой которых выступают высокопроизводительные приложения, то есть такие, для которых требуются компьютерные архитектуры с пиковыми на сегодняшний день техническими характеристиками, с наивысшей пропускной способностью и которые вызваны к жизни самыми трудными, но и наиболее значимыми проблемами науки и инженерии.
Есть все основания полагать — и это стимулирует всеобщий интерес, — что те существенные продвижения, которые уже были сделаны, и те ожидания, которые возлагаются на будущее, связаны не только собственно с областью высокопроизводительных вычислений. Предлагаемые подходы способны оказать глубокое влияние на компьютерную индустрию в целом, включая и то, что принято называть массовым рынком.
Направление, о котором идет речь, можно обозначить как использование компьютерных сетей для создания распределенной вычислительной инфраструктуры национального и мирового масштаба. На сегодня сети доказали беспрецендентную практическую полезность, выступая как средство глобальной доставки различных форм информации. Однако потециал сетей раскрыт не полностью: они могут стать еще и средством организации вычислений следующего поколения.
Что представляет собой Internet? Это множество узлов с собственными процессорами, оперативной и внешней памятью, устройствами ввода/вывода. Узлы соединены друг с другом коммутационным оборудованием и линиями передачи данных. Такая конструкция весьма напоминает многопроцессорную систему, в которой роль магистральных шин выполняет Сеть.
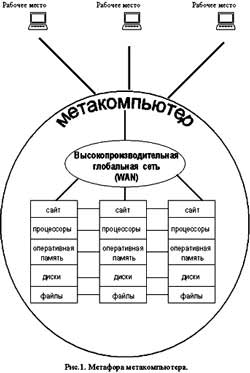
Цель заключается в том, чтобы превратить аналогии в реальность, то есть стереть барьеры между разнородными, пространственно распределенными вычислительными системами, образовав сверхкомпьютер или метакомпьютер, который для пользователей и программистов выступал бы как единая вычислительная среда, доступная непосредственно с рабочего места (ПК или рабочей станции).
Центральное понятие метакомпьютера можно определить как метафору виртуального компьютера, динамически организующегося из географически распределенных ресурсов, соединенных высокоскоростными сетями передачи данных (рис.1). Отдельные установки являются составными частями метакомпьютера и в то же время служат точками подключения пользователей.
Необходимо подчеркнуть принципиальную разницу метакомпьютерного подхода и сегодняшних программных средств удаленного доступа.
В метакомпьютере этот доступ прозрачен, то есть пользователь имеет полную иллюзию использования одной, но гораздо более мощной, чем та, что стоит на его столе, машины и может с ней работать в рамках той же модели, которая принята на его персональном вычислителе.
Прежде всего имеет смысл остановиться на вопросе: зачем может быть нужна такая среда? Как уже говорилось, непосредственные потребности исходят от высокопроизводительных приложений.
В различных прикладных областях (космологии, гидрологии окружающей среды, молекулярной биологии и т.д.) поставлены весьма важные задачи, характеризующиеся, например , следующими требованиями к компьютерным ресурсам:
— 0.2 — 20 Tflops процессорной мощности; — 100 — 200 GB оперативной памяти; — 1— 2 TB дисковой памяти; — 0.2 — 0.5 GB/sec ширина полосы пропускания ввода/вывода.
Нижняя граница таких запросов — это уникальные архитектуры типа SGI/CRAY Origin с тысячами
процессоров.
С другой стороны суммарный объем ресурсов в достаточно большом фрагменте Сети далеко превосходит эти цифры, вопрос в том, как эти ресурсы объединить и дать в руки реальному потребителю.
Такая постановка очень серьезно воспринимается во всем мире и в первую очередь в Соединенных Штатах. Здесь роль организующего начала взял на себя фонд Национальный научный фонд NSF — — National Science Foundation. Для NSF проект вычислительной сетевой среды стал естественным продолжением предыдущей общенациональной программы создания суперкомпьютерных центров, начатой в 1985 году и завершившейся в сентябре 1997-CТРАТЕГИЧЕСКАЯ КОМПЬЮТЕРНАЯ ИНИЦИАТИВА.
В результате суперкомпьютерные мощности стали доступны практически всем заинтересованным исследователям, произошла быстрая эволюция архитектур: от векторных систем (PVP) к машинам с массовым параллелизмом (MPP) и далее к машинам с симметричным мультипроцессированием на базе разделяемой памяти (SMP). Кстати говоря, опыт этой программы показал, насколько неверно представление, что суперкомпьютеры — это экзотика, и даже в научном мире они не найдут большого применения.
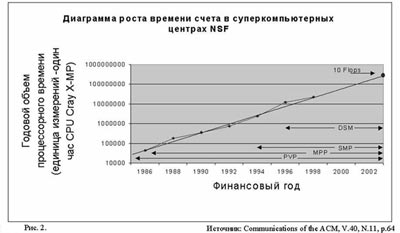
После того как в 1992 году в строй ввели 512 — процессорную CM-5, количество проектов Национального центра суперкомпьютерных приложений (National Center for Supercomputing Applicaions — NCSA), потребляющих свыше 1000 процессорных часов в год (в единицах CRAY X-MP), увеличилось с 10 до 100 (рис.2). Желающие есть, были бы возможности.

На следующий же день (1 октября 1997) по окончании Суперкомпьютерной программы стартовала новая — Partnership for Advanced Computational Infrastructure (PACI) (рис.3).
Она выполняется сразу двумя крупными научными объединениями: National Computational Science Aliance (далее Aliance) и National Partnership for Advanced Computational Infrastructure (NPACI) с суммарным финансированием в 340 миллионов долларов, осуществляемым NSF, DARPA, NASA, Министерством обороны (программа модернизации).
План Aliance ставит задачу (и за истекший период она достаточно успешно реализуется) создания Национальной Технологической Сети GRID, которая способна открыть доступ с рабочих мест к самой большой из когда—либо собранных вычислительных сред для решения сложнейших научных и инженерных задач.
Термин GRID используется для обозначения вычислительной среды по аналогии с электрической сетью: включение в GRID пользователей должно быть столь же легким, как и включение бытовых приборов.
Имея штаб-квартиру в NCSA при Университете штата Иллинойс, Aliance объединяет исследователей из более чем 50 университетов, национальных лабораторий и промышленных организаций. Структуру проекта опрелеляют три главных направления (команды) — Новейшей техники (Advanced Hardware), Прикладных технологий (Application Technology) и Системных технологий (Enabling Technology). Включение в проект команды AT дает возможность двум другим отталкиваться от конкретных потребностей реальных задач, а также опробовать собственные решения на практике, так что GRID существует в виде постоянно действующего и развивающегося прототипа.