

5. Модель клиент-сервер рс
В этом разделе мы кратко рассмотрим модель клиент-сервер.
5.1. Клиенты и серверы
В базовой модели клиент-сервер все процессы в распределенных системах делятся на две возможно перекрывающиеся группы. Процессы, реализующие некоторую службу, например службу файловой системы или базы данных, называются серверами (servers). Процессы, запрашивающие службы у серверов путем посылки запроса и последующего ожидания ответа от сервера, называются клиентами (clients). Взаимодействие клиента и сервера, известное также под названием режим работы запрос-ответ (request-reply behavior), иллюстрирует рис. 1.18.
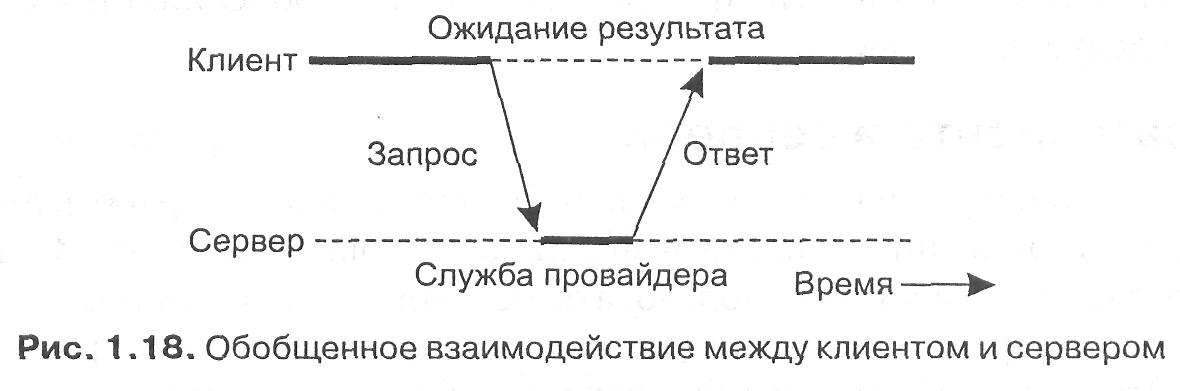
Если базовая сеть так же надежна, как локальные сети, взаимодействие между клиентом и сервером может быть реализовано посредством простого протокола, не требующего установления соединения.
В этом случае клиент, запрашивая службу, облекает свой запрос в форму сообщения с указанием в нем службы, которой он желает воспользоваться, и необходимых для этого исходных данных.
Затем сообщение посылается серверу. Последний, в свою очередь, постоянно ожидает входящего сообщения, получив его, обрабатывает, упаковывает результат обработки в ответное сообщение и отправляет его клиенту.
Использование не требующего соединения протокола дает существенный выигрыш в эффективности. До тех пор пока сообщения не начнут пропадать или повреждаться, можно вполне успешно применять протокол типа запрос-ответ.
К сожалению, создать протокол, устойчивый к случайным сбоям связи, — нетривиальная задача. Все, что мы можем сделать, — это дать клиенту возможность повторно послать запрос, на который не был получен ответ. Проблема, однако, состоит в том, что клиент не может определить, действительно ли первоначальное сообщение с запросом было потеряно или ошибка произошла при передаче ответа. Если потерялся ответ, повторная посылка запроса может привести к повторному выполнению операции. Если операция представляла собой что-то вроде «снять 10 000 долларов с моего банковского счета», понятно, что было бы гораздо лучше, если бы вместо повторного выполнения операции вас просто уведомили о произошедшей ошибке. С другой стороны, если операция была «сообщите мне, сколько денег у меня осталось», запрос прекрасно можно было бы послать повторно. Нетрудно заметить, что у этой проблемы нет единого решения.
В качестве альтернативы во многих системах клиент-сервер используется надежный протокол с установкой соединения. Хотя это решение в связи с его относительно низкой производительностью не слишком хорошо подходит для локальных сетей, оно великолепно работает в глобальных системах, для которых ненадежность является «врожденным» свойством соединений. Так, практически все прикладные протоколы Интернета основаны на надежных соединениях по протоколу TCP/IP. В этих случаях всякий раз, когда клиент запрашивает службу, до посылки запроса серверу он должен установить с ним соединение. Сервер обычно использует для посылки ответного сообщения то же самое соединение, после чего оно разрывается. Проблема состоит в том, что установка и разрыв соединения в смысле затрачиваемого времени и ресурсов относительно дороги, особенно если сообщения с запросом и ответом невелики.
Примеры клиента и сервера
Чтобы внести большую ясность в то, как работают клиент и сервер, в этом пункте мы рассмотрим описание клиента и файлового сервера на языке С. И клиент, и сервер должны совместно использовать некоторые определения, которые мы соберем вместе в файл под названием header.h, текст которого приведен в листинге 1.3. Эти определения затем включаются в тексты программ клиента и сервера следующей строкой:
#include <header.h>
Эта инструкция вызовет активность препроцессора, который посимвольно вставит все содержимое файла header.h в текст программы до того, как начнется ее компиляция.
Листинг 1.3. Файл header.h, используемый клиентом и сервером
/* Определения, необходимые и клиентам, и серверам */
#define TRUE I
/* Максимальная длина имени файла */
fdefine MAX_PATH 255
/* Максимальное количество данных, передаваемое за один раз */
#define BUFJIZE 1024
/* Сетевой адрес файлового сервера */
fdefine FILE SERVER 243
-
/* Определения разрешенных операций */
/* создать новый файл */
#define CREATE I
/* считать данные из файла и вернуть их */
fdefine READ 2
/* записать данные в файл */
#define WRITE 3
/* удалить существующий файл */
fdefine DELETE 4
i /* Коды ошибок */
/* операция прошла успешно */
Idefine OK О
/* запрос неизвестной операции */
fdefine E_BAD_OPER -I
/* ошибка в параметре */
fdefine E_BAD_PARAM -2
/* ошибка диска или другая ошибка чтения-записи */
fdefine E_IO -3
/* Определение формата сообщения */ struct message {
long source; /* идентификатор источника */
long dest; /* идентификатор приемника */
long opcode: /* запрашиваемая операция */
long count; /* число передаваемых байт */
long offset; /* позиция в файле, с которой начинается
ввод-вывод */
long result; /* результат операции */ char name[MAX_PATH]; /* имя файла, с которым производятся
операции */ char data[BUF_SIZE]; /* данные, которые будут считаны или
записаны */ }:
Итак, перед нами текст файла header.h. Он начинается с определения двух констант, МАХ_РАТН и BUF_SIZE, которые определяют размер двух массивов, используемых в сообщении. Первая задает число символов, которое может содержаться в имени файла (то есть в строке с путем типа /usr/ast/books/opsys/chapter1.t). Вторая задает размер блока данных, который может быть прочитан или записан за одну операцию путем установки размера буфера. Следующая константа, FILE_ SERVER, задает сетевой адрес файлового сервера, на который клиенты могут посылать сообщения.
Вторая группа констант задает номера операций. Они необходимы для того, чтобы и клиент, и сервер знали, какой код представляет чтение, какой код — запись и т. д. Мы приводим здесь только четыре константы, в реальных системах их обычно больше.
Каждый ответ содержит код результата. Если операция завершена успешно, код результата обычно содержит полезную информацию (например, реальное число считанных байтов). Если нет необходимости возвращать значение (например, при создании файла), используется значение ОК. Если операция по каким-либо причинам окончилась неудачей, код результата (E_BAD_OPER, E_BAD_PARAM и др.) сообщает нам, почему это произошло.
Наконец, мы добрались до наиболее важной части файла header.h — определения формата сообщения. В нашем примере это структура с 8 полями. Этот формат используется во всех запросах клиентов к серверу и ответах сервера. В реальных системах, вероятно, фиксированного формата у сообщений не будет (поскольку не во всех случаях нужны все поля), но здесь это упростит объяснение. Поля source и dest определяют, соответственно, отправителя и получателя. Поле opcode — это одна из ранее определенных операций, то есть create, read, write или delete. Поля count и offset требуются для передачи параметров. Поле result в запросах от клиента к серверу не используется, а при ответах сервера клиенту содержит значение результата. В конце структуры имеются два массива. Первый из них, name, содержит имя файла, к которому мы хотим получить доступ. Во втором, data, находятся возвращаемые сервером при чтении или передаваемые на сервер при записи данные.
Давайте теперь рассмотрим код в листингах 1.4 и 1.5. Листинг 1.4 — это программа сервера, листинг 1.5 — программа клиента. Программа сервера достаточно элементарна. Основной цикл начинается вызовом receive в ответ на сообщение с запросом. Первый параметр определяет отправителя запроса, поскольку в нем указан его адрес, а второй указывает на буфер сообщений, идентифицируя, где должно быть сохранено пришедшее сообщение. Процедура receive блокирует сервер, пока не будет получено сообщение. Когда оно, наконец, приходит, сервер продолжает свою работу и определяет тип кода операции. Для каждого кода операции вызывается своя процедура. Входящее сообщение и буфер для исходящих сообщений заданы в параметрах. Процедура проверяет входящее сообщение в параметре m1 и строит исходящее в параметре m2. Она также возвращает значение функции, которое передается через поле result. После посылки ответа сервер возвращается к началу цикла, выполняет вызов receive и ожидает следующего сообщения.
В листинге 1.5 находится процедура, копирующая файлы с использованием сервера. Тело процедуры содержит цикл чтения блока из исходного файла и записи его в файл-приемник. Цикл повторяется до тех пор, пока исходный файл не будет полностью скопирован, что определяется по коду возврата операции чтения — должен быть ноль или отрицательное число.
Первая часть цикла состоит из создания сообщения для операции чтения и пересылки его на сервер. После получения ответа запускается вторая часть цикла, в ходе выполнения которой полученные данные посылаются обратно на сервер для записи в файл-приемник. Программы из листингов 1.4 и 1.5 — это только набросок кода. В них опущено множество деталей. Так, например, не приводятся процедуры do_xxx (которые на самом деле выполняют работу), отсутствует также обработка ошибок. Однако общая идея взаимодействия клиента и сервера вполне понятна. В следующих пунктах мы ближе рассмотрим некоторые дополнительные аспекты модели клиент-сервер.
Листинг 1.4. Пример сервера
finclude <header.h> void main(void) {
struct message ml, m2; /* входящее и исходящее сообщения */
int г; /* код результата */
while(TRUE) { /* сервер работает непрерывно */
receive(FILE_SERVER, Sml): /* блок ожидания сообщения */ switch(mi.opcode) { /* в зависимости от типа запроса */
case CREATE: г = do_create(&ml, &m2); break;
case READ: г = do_read(&ml, &m2) break:
case WRITE: г = do_write(&ml. &m2); break;
case DELETE: г = do_delete(&ml, &m2): break;
default: r = E_BAD_OPER;
}
m2.result = r; /* вернуть результат клиенту */
send(m1.source. &m2): /* послать ответ */
} }
Листинг 1.5. Клиент, использующий сервер из листинга 1.4 для копирования файла
#include <header.h>
/* процедура копирования файла через сервер */
int copy(char *src, char *dst){
struct message ml; /* буфер сообщения */
long position; /* текущая позиция в файле */
long client = НО; /* адрес клиента */
initializeO; /* подготовиться к выполнению */
position = 0;
do {
ml.opcode = READ; /* операция чтения */ ml.offset = position; /* текущая позиция в файле */ ml.count = BUF_SIZE; /* сколько байт прочитать */ strcpy(&ml.name, src); /* скопировать имя читаемого
файла*/
send(FILESERVER, &ml); /* послать сообщение на файловый сервер*/ receive(client, &ml); /* блок ожидания ответа */ /* Записать полученные данные в файл-приемник. */
ml.opcode = WRITE; /* операция: запись */ ml.offset = position; /* текущая позиция в файле */ ml.count = ml.result; /* сколько байт записать */ strcpy(&ml.name, cist): /* скопировать имя записываемого
файла*/
send(FILE_SERVER, &m1); /* послать сообщение на файловый сервер */ receive(client. &ml); /* блок ожидания ответа */ position += ml.result; /* в ml.result содержится количество записанных байтов */
} while( ml.result > 0 ): /* повторять до окончания */ /* вернуть ОК или код ошибки */
return(ml.result >= 0 ? OK : ml.result); }