

Аппаратное обеспечение
r1.msiu.ru: 1 процессор Pentium III/1GHz, 512Mb оперативной памяти;
r2.msiu.ru: 1 процессор Pentium III/1GHz, 512Mb оперативной памяти;
apps.msiu.ru: 1 процессор Pentium III/550MHz, 512Mb оперативной памяти;
аудитория 1201: 10 машин - 1 процессор Pentium III 866MHz, 512Mb оперативной памяти в каждом;
аудитория 1209: 10 машин - 1 процессор Pentium III 866MHz, 512Mb оперативной памяти в каждом;
аудитория 1217: 10 машин - 1 процессор Pentium III 866MHz, 512Mb оперативной памяти в каждом;
аудитория 1218: 10 машин - 1 процессор Pentium III 866MHz, 512Mb оперативной памяти в каждом,
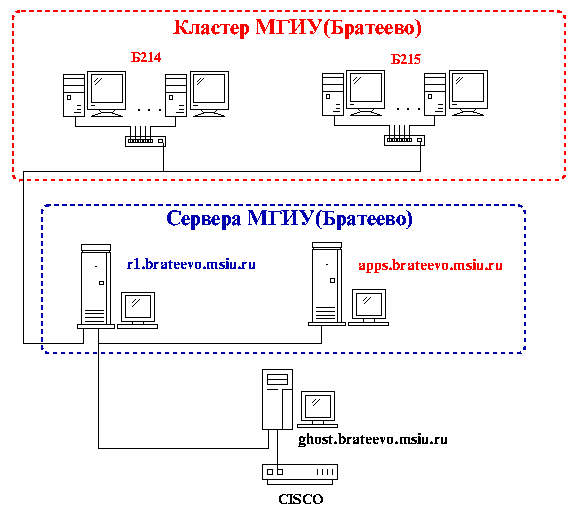
"Кластер МГИУ(Братеево)"
Кластер состоит из двух компьютерных классов ЦКТ и одного сервера - apps.brateevo.msiu.ru. На всех компьютерах загружается по сети бездисковая версия загрузки OC RedHat-7.3. В качестве сетевых коммуникаций используются концентраторы.
Метакластер состоит кластера МГИУ и кластера МГИУ в Братеево, связь с кластером МГИУ осуществляется через интернет.
Посмотреть схему
Аппаратное
обеспечение
apps.msiu.ru: 1 процессор Pentium III 800MHz, 512Mb оперативной памяти;
аудитория Б214: 10 машин - 1 процессор PIII 866MHz, 512Mb оперативной памяти в каждом;
аудитория Б215: 10 машин - 1 процессор PIII 866MHz, 512Mb оперативной памяти в каждом;
Результаты измерений основных характеристик кластера МГИУ
Пропускная способность и латентность
Для измерения пропускной способности использовалась система тестов производительности для параллельных компьютеров разработанных в Лаборатории Параллельных информационных технологий НИВЦ МГУ. Все тесты распространяются свободно и доступны на сервере http://www.parallel.ru/ в виде исходных текстов на языке С.
Основными характеристиками быстродействия сети являются латентность (latency) и пропускная способность (bandwidth). Под пропускной способностью R сети будем понимать количество информации, передаваемой между узлами сети в единицу времени (байт в секунду). Очевидно, что реальная пропускная способность снижается программным обеспечением за счет передачи разного рода служебной информации.
Латентностью (задержкой) называется время, затрачиваемое программным обеспечением и устройствами сети на подготовку к передаче информации по данному каналу. Полная латентность складывается из программной и аппаратной составляющих.
В кластере планируется использовать несколько видов компьютеров: сервера, рабочие станции, компьютерные классы. Результаты тестирования помогают понять, как лучше объединить компьютеры в кластер и как использовать его для различных задач.
Передача сообщений между серверами
Латентность (время задержки сообщений) в рамках MPI поверх Fast Ethernet составляет примерно 98,7 мксек, а максимальная достигнутая скорость однонаправленных пересылок составляет 8,26 Мбайт/сек.
На рисунке 1 представлена зависимость скорости пересылок больших сообщений от размера их (от 1K до 16 Мбайт).
Рис. 1. Передача больших сообщений между серверами
На рисунке 2 представлена зависимость скорости пересылок небольших сообщений от размера их (от 16 байт до 1К).
Рис. 2. Передача небольших сообщений между серверами
На рисунке 3 представлена зависимость времени пересылок небольших сообщений от размера их (от 1 байта до 256 байт).
Рис. 3. Латентность серверов
Передача сообщений между серверами и рабочими станциями
Латентность (время задержки сообщений) в рамках MPI поверх Fast Ethernet составляет примерно 116,7 мксек, а максимальная достигнутая скорость однонаправленных пересылок составляет 7,76 Мбайт/сек. На рисунке 4 представлена зависимость скорости пересылок больших сообщений от размера их (от 1K до 16 Мбайт).
Рис. 4. Передача больших сообщений между серверами и рабочими станциями
На рисунке 5 представлена зависимость скорости пересылок небольших сообщений от размера их (от 16 байт до 1К).
Рис. 5. Передача небольших сообщений между серверами и рабочими станциями
На рисунке 6 представлена зависимость времени пересылок небольших сообщений от размера их (от 1 байта до 256 байт).
Рис. 6. Латентность серверов и рабочих станций
Передача сообщений между компьютерными классами
Латентность (время задержки сообщений) в рамках MPI поверх Fast Ethernet составляет примерно 121,3 мксек, а максимальная достигнутая скорость однонаправленных пересылок составляет 6,7 Мбайт/сек. На рисунке 7 представлена зависимость скорости пересылок больших сообщений от размера их (от 1K до 16 Мбайт).
Рис. 7. Передача больших сообщений между компьютерными классами
На рисунке 8 представлена зависимость скорости пересылок небольших сообщений от размера их (от 16 байт до 1К).
Рис. 8. Передача небольших сообщений между компьютерными классами
На рисунке 9 представлена зависимость времени пересылок небольших сообщений от размера их (от 1 байта до 256 байт).
Рис. 9. Латентность между компьютерными классами
Передача сообщений в компьютерных классах
Латентность (время задержки сообщений) в рамках MPI поверх Fast Ethernet составляет примерно 69,5 мксек, а максимальная достигнутая скорость однонаправленных пересылок составляет 9,08 Мбайт/сек. На рисунке 10 представлена зависимость скорости пересылок больших сообщений от размера их (от 1K до 16 Мбайт).
Рис. 10. Передача больших сообщений в компьютерных классах
На рисунке 11 представлена зависимость скорости пересылок небольших сообщений от размера их (от 16 байт до 1К).
Рис. 11. Передача небольших сообщений в компьютерных классах
На рисунке 12 представлена зависимость времени пересылок небольших сообщений от размера их (от 1 байта до 256 байт).
Рис. 12. Латентность компьютерных классов
Передача сообщений между сервером и компьютерными классами
Латентность (время задержки сообщений) в рамках MPI поверх Fast Ethernet составляет примерно 124,3 мксек, а максимальная достигнутая скорость однонаправленных пересылок составляет 8,99 Мбайт/сек. На рисунке 13 представлена зависимость скорости пересылок больших сообщений от размера их (от 1K до 16 Мбайт).
Рис. 13. Передача больших сообщений между сервером и компьютерными классами
На рисунке 14 представлена зависимость скорости пересылок небольших сообщений от размера их (от 16 байт до 1К).
Рис. 14. Передача небольших сообщений между сервером и компьютерными классами
На рисунке 15 представлена зависимость времени пересылок небольших сообщений от размера их (от 1 байта до 256 байт).
Рис. 15. Латентность сервера и компьютерных классов
Сравнительные диаграммы
Ниже приведены сравнительные диаграммы передачи сообщений между различными типами машин.
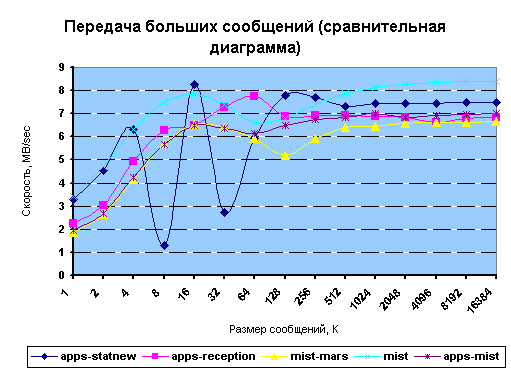
Рис. 16. Передача больших сообщений (сравнительная диаграмма)
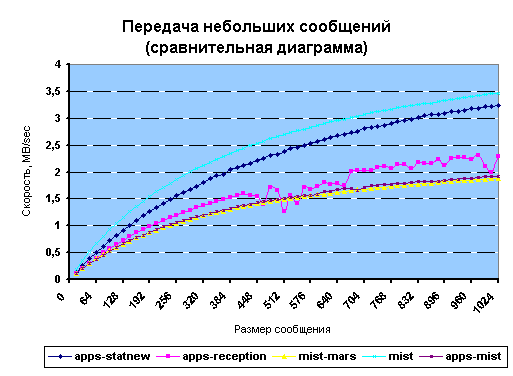
Рис. 17. Передача небольших сообщений (сравнительная диаграмма)
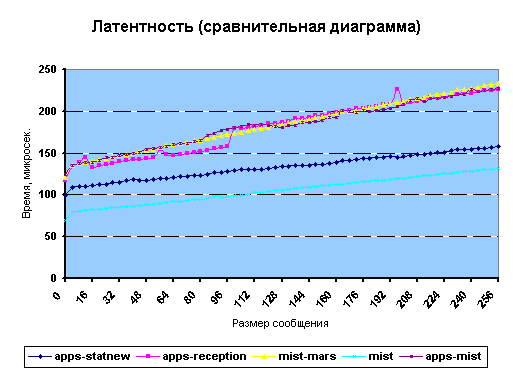
Рис. 18. Латентность (сравнительная диаграмма)
Принципы построения распределенных компьютерных систем
Компьютерные системы претерпевают революцию. С 1945 года, когда началась эпоха современных компьютеров, до приблизительно 1985 года компьютеры были большими и дорогими. Даже мини-компьютеры стоили сотни тысяч долларов. В результате большинство организаций имели в лучшем случае лишь несколько компьютеров, и, поскольку методы их соединения отсутствовали, эти компьютеры работали независимо друг от друга.
Однако в середине восьмидесятых под воздействием двух технологических новинок ситуация начала меняться.
Первой из этих новинок была разработка мощных микропроцессоров. Изначально они были 8-битными, затем стали доступны 16-, 32- и 64-битные процессоры. Многие из них обладали вычислительной мощностью мэйнфреймов (то есть больших компьютеров), но лишь частью их цены.
Скорость роста, наблюдавшаяся в компьютерных технологиях в последние полвека, действительно потрясает. Ей нет прецедентов в других отраслях. От машин, стоивших 100 миллионов долларов и выполнявших одну команду в секунду, мы пришли к машинам, стоящим 1000 долларов и выполняющим 10 миллионов команд в секунду. Разница в соотношении цена/производительность достигла порядка 1012. Если бы автомобили за этот период совершенствовались такими же темпами, «роллс-ройс» сейчас стоил бы один доллар и проходил миллиард миль на одном галлоне бензина (к сожалению, к нему потребовалось бы 200-страничное руководство по открыванию дверей).
Второй из новинок было изобретение высокоскоростных компьютерных сетей.
Локальные сети (Local-Area Networks, LAN) соединяют сотни компьютеров, находящихся в здании, таким образом, что машины в состоянии обмениваться небольшими порциями информации за несколько микросекунд. Большие массивы данных передаются с машины на машину со скоростью от 10 до 1000 Мбит/с.
Глобальные сети (Wide-Area Networks, WAN) позволяют миллионам машин во всем мире обмениваться информацией со скоростями, варьирующимися от 64 кбит/с (килобит в секунду) до гигабит в секунду.
В результате развития этих технологий сегодня не просто возможно, но и достаточно легко можно собрать компьютерную систему, состоящую из множества компьютеров, соединенных высокоскоростной сетью. Она обычно называется компьютерной сетью, или распределенной системой (distributed system), в отличие от предшествовавших ей централизованных (centralized systems), или однопроцессорных (single-processor systems), систем, состоявших из одного компьютера, его периферии и, возможно, нескольких удаленных терминалов.