

На рисунке 3.2 представлена диаграмма, отображающая сравнение производительности коммуникационных библиотек mpi и pvm.
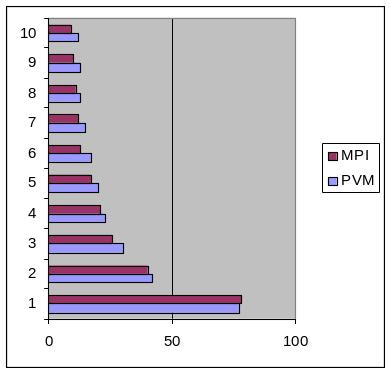
Рисунок 3.2 – Сравнение производительности библиотек MPI и PVM
3.5 Сходства и различия pvm и mpi
При сравнении MPI и PVM часто допускают ошибку, сравнивая спецификацию MPI с реализацией PVM. Для спецификаций и стандартов характерна меньшая гибкость, чем для их реализаций. В спецификациях MPI описываются возможности, которые рекомендуется включать в возможные реализации.
Для того чтобы выбор был правильным и точным, следует учесть, что авторы обеих систем ставили перед собой разные цели. В отличие от PVM, которая с самого начала развивалась в рамках исследовательского проекта, спецификация MPI разрабатывается комитетом, состоящим из специалистов в области высокопроизводительных вычислений, которые активно работают как в исследовательских организациях, так и в промышленности. Отправной точкой деятельности комитета MPI Forum было то, что каждый производитель мультипроцессорных систем обычно создавал собственную систему обмена сообщениями. В этом случае не могло быть и речи о совместимости программного обеспечения. Совместимость мог бы обеспечить только стандарт для системы обмена сообщениями. Во главу угла деятельности MPI Forum была положена борьба за производительность, которую поддерживали производители суперкомпьютеров. С учетом этого не удивительно, что MPI позволяет в подавляющем большинстве случаев обеспечить более высокую производительность на массивно-параллельных системах, чем PVM.
MPI Forum не ориентировался на конкретные приложения, занимаясь созданием стандарта системы параллельного программирования. При этом в жертву стандартизации отчасти была принесена функциональность системы – потеря универсальности почти неизбежна при выработке любого стандарта.
Форум MPI декларировал и зафиксировал в спецификации ряд целей, некоторые из них приведены ниже:
MPI должна быть библиотекой, пригодной для разработки параллельных прикладных программ, а не распределенной средой выполнения или распределенной операционной системой;
MPI не ориентируется на многопоточные реализации, хотя и допускает их. Безопасность работы в многопоточной среде подразумевает отсутствие таких сущностей, как активный буфер или активное сообщение;
масштабируемость и корректность коллективных операций могут быть эффективно реализованы, только если группы процессов являются статическими;
MPI должна быть модульной системой, что позволяет ускорить разработку переносимых параллельных библиотек. Следствием этого является то, что ссылки должны относиться к модулю, а не ко всей программе. Процессы-источники и адресаты должны задаваться рангом в группе, а не абсолютным идентификатором. Контекст обмена должен быть скрыт от программиста;
MPI должна быть расширяемой системой, что дает возможность развивать ее для будущих применений. Это приводит к объектно-ориентированному стилю программирования в этой системе, хотя и без использования объектно-ориентированных языков. Для этого требуются операции с объектами, что является одной из причин относительно большого числа функций в MPI;
МРI должна в какой-то степени поддерживать вычисления в гетерогенной среде (для этого введен такой объект, как MPiDatatype), хотя и не требуется, чтобы все реализации системы были гетерогенными;
MPI должно обеспечивать определенное поведение программ.
Разработчики PVM изначально старались сделать программный и пользовательский интерфейс системы простым и понятным. Переносимости отдавалось предпочтение перед производительностью, исследования участников проекта сосредоточились на проблемах улучшения масштабируемости, надежности и поддержки гетерогенных вычислительных систем. В PVM принята довольно простая схема обмена сообщениями. В процессе развития проекта сохранялась обратная совместимость PVM-программ, чтобы уже работающие приложения оставались работоспособными и в новых версиях системы по крайней мере, в рамках второй версии PVM. С другой стороны, можно выделить и характерные особенности MPI:
большой набор подпрограмм двухточечного обмена;
большой набор подпрограмм коллективного обмена;
использование контекста обмена, который позволяет создавать надежные библиотеки параллельных подпрограмм;
возможность создания и использования топологий обмена;
возможность создания производных типов данных, позволяющих обмениваться сообщениями, которые содержат данные, расположенные в памяти не непрерывно.
В спецификации MPI-1 не была стандартизована процедура запуска MPI-программ в кластерах рабочих станций, что создавало проблемы с переносимостью. Одной из целей разработки спецификации MPI-2 было решение этой проблемы с помощью включения новых функций, среди которых:
подпрограммы запуска процессов;
односторонние операции коммуникации (put и get);
неблокирующие операции коллективного обмена.
В MPI-2 к 128 функциям MPI-1 было добавлено еще 120 функций, что в результате дало гораздо более богатый набор подпрограмм, чем в PVM. Вместе с тем, пока в МРI нет тех полезных возможностей, которые предоставляет PVM. Это средства создания устойчивых к аппаратным сбоям приложений, динамическое определение доступных ресурсов и некоторые другие. Система PVM строится на основе концепции виртуальной машины, которая составляет базу поддержки гетерогенности, универсальности и других особенностей системы. MPI фокусируется на обмене сообщениями. Интерфейс MPI должен был вобрать максимальное количество конструкций, связанных с обменом сообщениями и учесть особенности различных многопроцессорных систем так, чтобы программы могли выполняться на всех этих системах. Переносимость программ в MPI такова, что программа, написанная для одной архитектуры, может быть скопирована на другую архитектуру, откомпилирована и запущена на выполнение без модификации исходного кода. Такую переносимость поддерживает и PVM, но переносимость в PVM понимается в более широком смысле. Программы PVM также могут компилироваться на разных архитектурах и запускаться на выполнение, но при этом они могут обмениваться между собой данными. MPI-программа может выполняться на любой архитектуре, но архитектуры хостов должны совпадать. PVM-программа может работать на разнородном по архитектуре кластере. Спецификация MPI не запрещает поддержку гетерогенного исполнения, но и не включает его в разряд обязательных свойств. Это и понятно – сложно заставить одного производителя пожертвовать производительностью своей собственной системы ради совместимости с системой другого производителя.
Перед разработчиком системы обмена сообщениями всегда стоит дилемма: универсальность или производительность? Достичь максимальной производительности можно, используя особенности конкретной архитектуры, но это лишает систему универсальности.
В PVM производительность отчасти приносится в жертву гибкости и универсальности системы, которая должна поддерживать гетерогенность в максимальной степени. При выполнении обменов локально на одном компьютере или между компьютерами с одинаковой архитектурой, PVM использует собственные функции коммуникации для данной системы, как, впрочем, и MPI. Обмены между системами с разной архитектурой в PVM реализуются на основе стандартных сетевых протоколов. Для выбора механизма передачи сообщения PVM должна выполнить дополнительную работу, что снижает производительность системы.
Имеется различие между PVM и MPI в организации межъязыкового взаимодействия. В PVM возможно взаимодействие между программами, написанными на языках С и FORTRAN. В MPI это взаимодействие не поддерживается по причине сложности согласования программных интерфейсов обоих языков.
Если говорить об управлении распределением ресурсов, следует отметить динамический характер PVM. Конфигурация виртуальной машины может изменяться динамически, как вручную, так и из прикладной программы. Это дает возможность программисту полнее реализовать динамически сбалансированную загрузку узлов, устойчивую работу программы.
Потребности прикладной программы могут меняться в процессе ее выполнения. Для эффективного использования вычислительного комплекса необходимо, чтобы система обеспечивала гибкий контроль применения и распределения ресурсов. Программа может часть времени работать в режиме последовательного выполнения, а в какие-то моменты времени ей могут потребоваться дополнительные процессоры для исполнения параллельной части кода. В этом случае не стоит сразу загружать множество процессоров одной задачей, гораздо выгоднее изменять загрузку параллельной системы в ходе выполнения программы. Подобные ситуации часто встречаются в программировании. В MPI нет средств, обеспечивающих такую динамику – это статическая по своей природе система. Статичность является в этом случае оплатой за производительность. Виртуальная машина в PVM является абстракцией, скрывающей в общем случае разнородную систему и позволяющую управлять ресурсами вычислительной системы. Вместе с тем, при необходимости, программист может отказаться от использования абстракции самого высокого уровня, переходя к более тонкой детализации. Спецификация MPI не поддерживает абстрагирования такого рода, оставляя программиста наедине с проблемой управления ресурсами.
MPI предлагает другой вид абстракции – топологию обменов, которая является надстройкой над множеством доступных вычислительных ресурсов. Топология является логической, т. е. она обусловлена логической структурой алгоритма и схемой обмена данными в конкретной задаче. В соответствии с топологией выполняется переупорядочивание подзадач, относящихся к параллельной прикладной программе. В PVM такой возможности нет.
Устойчивость работы является важным требованием, предъявляемым к программам с большим временем выполнения. Чем больше время выполнения программы и чем больше для ее выполнения используется процессоров, тем важнее устойчивость системы, поскольку возрастает вероятность возникновения сбоя. Для обеспечения устойчивой работы система должна обладать средствами сбора информации о конфигурации, средствами определения аппаратных и программных сбоев и т. д.
В PVM имеется механизм уведомления об особых ситуациях, когда система сообщает задачам об изменении состояния виртуальной машины или об аварийном завершении процесса. Уведомлением является специальное сообщение и программист может предусмотреть собственную реакцию программы на то или иное событие. Один из процессов может играть особую роль, являясь, например, сервером. Если хост, на котором выполняется эта задача, по какой-то причине перестает работать, программа, получив соответствующее уведомление, может запустить сервер на другом хосте. При изменении конфигурации виртуальной машины может быть предусмотрено и программное перераспределение ресурсов. Это обеспечивает эффективное выполнение параллельной PVM-программы.
В PVM имеется механизм уведомлений о прошедших событиях. Задача может с помощью этого механизма определить, например, завершил ли какой-то процесс работу. Может быть получено уведомление и о добавлении в виртуальную машину нового хоста. В MPI-1 таких возможностей нет, а в MPI-2 включена поддержка механизма уведомлений. Причина отсутствия в MPI средств обеспечения устойчивой работы и уведомлений об особых событиях – статический характер групп процессов МРI. В этом случае параллельная программа сразу же запускается на выполнение как коллектив взаимодействующих процессов, и если один из этих процессов аварийно завершит свою работу, завершится работа и всей программы. Статическая реализация групп следует естественным образом из системы приоритетов при разработке MPI – на первом месте производительность. В этом случае экономия достигается за счет отказа от средств мониторинга (наблюдения) за состоянием системы. Конфигурация группы процессов известна с самого начала.
Система PVM строится на основе концепции виртуальной машины, которая составляет базис поддержки гетерогенности, универсальности и других особенностей системы. MPI фокусируется на обмене сообщениями. При запуске программы MPI создается универсальный коммуникатор MPI_COMM_WORLD, в состав которого входят все запущенные процессы. При формировании новой группы процессов (области взаимодействия) выполняется синхронный вызов необходимых подпрограмм, результатом которого является создание нового контекста обмена. В такой схеме создания группы не требуется участие специального сервера или демона. Контекст разрушается при завершении работы хотя бы одного процесса из вновь созданного коммуникатора. При разработке спецификации MPI было решено, что генерация уникальных тегов контекстов обмена в разных группах может нанести ущерб производительности системы. Вместе с тем, наличие одинаковых тегов делает обмены в разных группах небезопасными из-за возможности их пересечения, поэтому и были введены интеркоммуникаторы, которые обеспечивают безопасный межгрупповой обмен, позволяя процессам "договориться" о контексте обмена. Напомним, что этот обмен всегда двухточечный.
Группы в MPI и в PVM являются различными объектами, хотя и имеющими определенное сходство (например, в MPI адреса процессов определяются относительно группы, а в PVM они являются абсолютными и задаются в терминах идентификаторов задач).
В PVM, благодаря наличию демонов, несложно создать уникальный контекст обмена, что приводит к более простой и универсальной модели контекста. Имеются средства создания контекста и работы с ним. Эти средства похожи на средства MPI. При создании группы процессов она наделяется уникальным контекстом, и нет необходимости создавать такие дополнительные объекты, как коммуникаторы. Новые процессы в PVM могут использовать уже существующие контексты обмена, что позволяет им передавать сообщения и принимать их от членов группы. Безусловно, это полезное свойство. В MPI изменение состава группы, прежде всего, удаление из нее процесса, разрушает коммуникатор и делает работу программы непредсказуемой.
В PVM можно использовать сервер имен, роль которого играет демон системы. Сервером имен называют программу, которая возвращает информацию о заданном имени. Если независимо запускаются несколько программ, можно дать возможность одной программе получить информацию о другой программе. Особенно это полезно в такой динамической системе, как PVM. В MPI-1 сервер имен просто не нужен, обходится без него и MPI-2.
В PVM нет средств параллельного ввода/вывода. Многие параллельные операции ввода/вывода являются коллективными и лучше всего определяются в терминах статических групп, механизм которых используется в MPI. В PVM затруднено программирование многопоточных приложений.
В настоящее время наблюдается определенное сближение обеих систем. Оно включает появление возможностей динамического управления процессами в MPI, статических групп и контекстов обмена в PVM.
Кластер на основе пакета openMosix