

2.7 Тестирование кластерного комплекса
В лаборатории кафедры созданный кластерный вычислительный комплекс может содержать до десяти рабочих станций имеющих следующую конфигурацию:
процессор Intel Celeron 800 МГц;
ОЗУ 128 МБ;
HDD 20 ГБ;
SVGA Riva TNT 32;
локальная сеть на коммутаторах Fast Ethernet 100 Mb/s.
В качестве теста производительности будем использовать прикладную программу, которая занимается трехмерным рендерингом – это класс приложений, которые работают на многокомпьютерных фирмах киностудий, в конструкторских бюро и на домашних компьютерах. Для этой цели будем использовать бесплатную и доступную в исходном коде, портированную на многие платформы программу трассировки лучей POV-Ray, позволяющую получить трехмерное изображение или анимацию. Изначально данная программа не поддерживает параллельное выполнение вычислений, однако существуют ее модификации для наиболее распространенных библиотек параллельных вычислений MPICH и PVM. В нащем случае будем использовать такой измененный вариант программы для библиотеки
Поскольку эта программа может принимать большое число параметров, то с целью упрощения ее запуска будем использовать скрипт для командного интерпретатора. Ниже приведен пример такого скрипта mpipov для запуска модифицированной для MPICH программы трассировки лучей POV-Ray:
#!/bin/sh
RESULT=/home/knoppix/cluster/results
mpirun -np $2 $3 /usr/local/bin/mpi-x-povray -I /usr/local/share/povray31/ /scenes/advanced/$1.pov -O $RESULT/$1.tga -L/usr/local/share/povray31/include/ +NW64 +NH64 +W1024 +H768
В переменной RESULT указывается путь для сохранения результатов рендеринга. После этого собственно и происходит запуск программы mpi-x-povray с помощью mpirun. Скрипт может принимать до трех аргументов, которые потом будут подставлены интерпретатором последовательно вместо $1, $2, $3 при запуске на выполнение mpirun. Модифицированная программа mpi-x-povray принимает следующие параметры запуска:
- I /usr/local/share/povray31/scenes/advanced/$1.pov – путь к файлу в котором содержится описание сцены для рендеринга, имя сцены будет передано параметром при запуске;
- O $RESULT/$1.tga – путь и имя файла для сохранения результатов;
- L/usr/local/share/povray31/include/ - путь в соответсвии с которым будет производится поиск подключаемых файлов, необходимых POV-Ray для произведения рендеринга;
+NW64 +NH64 +W1024 +H768 – эти параметры указывают что изображение имеет размер 1024x768 точек и каждый MPI процесс для рендеринга получает квадратный участок 64x64 точек изображения.
Для запуска данного скрипта на выполнение следует использовать следующую команду:
$ mpipov s n [-t],
где s – имя сцены, рендеринг которой необходимо выполнить. Все сцены находятся в директории /usr/local/share/povray31/scenes и имеют расширение *.pov;
n – количество выполняемых потоков. Желательно использовать n=(число узлов кластера+1);
t – включение тестового режима (можно не указывать).
Поскольку вычисления на кластере могут занимать многие часы, то перед запуском вычислений рекомендуется запустить скрипт со включенным тестовым режимом. Параметр –t запускает режим тестирования, в котором программы не запускается, а выводятся только действия, которые должны быть выполнены. При запуске скрипта mpipov с добавленным в него ключем –t на экране отображаются имена машин и номера процессов в том виде, в каком они будут распределены по узлам кластера, при этом вычисления не выполняются. Данный режим удобен и рекомендуется для предварительного запуска с целью проверки правильности распределения вычислительной нагрузки на различные узлы кластера, он позволяет выявить ошибки в конфигурации MPICH на ранней стадии.
Пример запуска рендеринга сцены skyvase в тестовом режиме с помощью скрипта mpipov на четырех узлах кластера:
$ mpipov skyvase 4
Данный скрипт запустит 4 вычислительных потока на первых четырех узлах кластерного комплекса. Список имен узлов или их IP-адресов хранится в уже упоминавшемся ранее файле machines.LINUX. Содержание этого файла приведено для кластера из десяти узлов:
clustersrv.evm.knure
node1.evm.knure
node2.evm.knure
node3.evm.knure
node4.evm.knure
node5.evm.knure
После запуска скрипта mpipov начинается рендеринг указанной сцены. Этот процесс может занять от нескольких секунд до нескольких часов в зависимости от сложности сцены и разрешения выходного изображения.
Аналогичным образом можно создать скрипт для запуска любой другой параллельной программы, которая при запуске использует большое число параметров, что значительно упростит работу пользователя.
Последовательно изменяя количество используемых узлов кластера от одного до десяти, производим запуск программы POV-Ray – выполняем рендеринг сцены Skyvase. Результаты выполнения программы приведены в таблице 2.2.
Таблица 2.2 – Время выполнения программы MPI POV-Ray
Количество задействованных узлов |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
Время выполнения программы, с |
78 |
40 |
26 |
21 |
17 |
13 |
12 |
11 |
10 |
9 |
Представим полученные результаты в виде диаграммы на рисунке 2.3
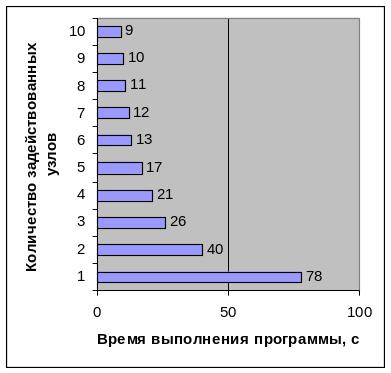
Рисунок 2.3 – Время выполнения программы MPI POV-Ray