

1manly_b_f_j_statistics_for_environmental_science_and_managem
.pdf16 Statistics for Environmental Science and Management, Second Edition
Example 1.7: Evaluating the Attainment of Cleanup Standards
Many environmental studies are concerned with the specific problem of evaluating the effectiveness of the reclamation of a site that has suffered from some environmental damage. For example, a government agency might require a mining company to work on restoring a site until the biomass of vegetation per unit area is equivalent to what is found on undamaged reference areas. This requires a targeted study as defined previously.
There are two complications with using standard statistical methods in this situation. The first is that the damaged and reference sites are not generally selected randomly from populations of potential sites, and it is unreasonable to suppose that they would have had exactly the same mean for the study variable even in the absence of any impact on the damaged site. Therefore, if large samples are taken from each site, there will be a high probability of detecting a difference, irrespective of the extent to which the damaged site has been reclaimed. The second complication is that, when a test for a difference between the two sites does not give a significant result, this does not necessarily mean that a difference does not exist. An alternative explanation is that the sample sizes were not large enough to detect a difference that does exist.
These complications with statistical tests led to a recommendation by the U.S. Environmental Protection Agency (US EPA 1989a) that the null hypothesis for statistical tests should depend on the status of a site, in the following way:
1.If a site has not been declared to be contaminated, then the null hypothesis should be that it is clean, i.e., there is no difference from the control site. The alternative hypothesis is that the site is contaminated. A nonsignificant test result leads to the conclusion that there is no real evidence that the site is contaminated.
2.If a site has been declared to be contaminated, then the null hypothesis is that this is true, i.e., there is a difference (in an unacceptable direction) from the control site. The alternative hypothesis is that the site is clean. A nonsignificant test result leads to the conclusion that there is no real evidence that the site has been cleaned up.
The point here is that, once a site has been declared to have a certain status, pertinent evidence should be required to justify changing this status.
If the point of view expressed by items 1 and 2 is not adopted, so that the null hypothesis is always that the damaged site is not different from the control, then the agency charged with ensuring that the site is cleaned up is faced with setting up a maze of regulations to ensure that study designs have large enough sample sizes to detect differences of practical importance between the damaged and control sites. If this is not done, then it is apparent that any organization wanting to have the status of a site changed from contaminated to clean should carry out the smallest study possible, with low power to detect even a large difference from the control site. The probability of a nonsignificant test result (the site is clean) will then be as high as possible.
As an example of the type of data that may be involved in the comparison of a control site and a possibly contaminated one, consider some measurements of 1,2,3,4-tetrachlorobenzene (TcCB) in parts per
The Role of Statistics in Environmental Science |
17 |
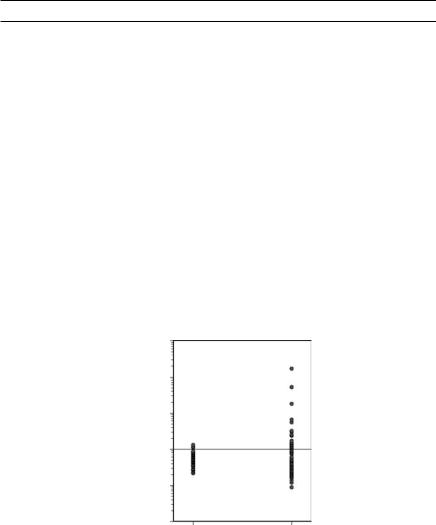
thousand million given by Gilbert and Simpson (1992, p. 6.22). There are 47 measurements made in different parts of the control site and 77 measurements made in different parts of the possibly contaminated site, as shown in Table 1.3 and Figure 1.6. Clearly the TcCB levels are much more
Table 1.3
Measurements of 1,2,3,4-Tetrachlorobenzene from Samples Taken at a Reference Site and a Possibly Contaminated Site
Reference Site (n = 47)
0.60 |
0.50 |
0.39 |
0.84 |
0.46 |
0.39 |
0.62 |
0.67 |
0.69 |
0.81 |
0.38 |
0.79 |
0.43 |
0.57 |
0.74 |
0.27 |
0.51 |
0.35 |
0.28 |
0.45 |
0.42 |
1.14 |
0.23 |
0.72 |
0.63 |
0.50 |
0.29 |
0.82 |
0.54 |
1.13 |
0.56 |
1.33 |
0.56 |
1.11 |
0.57 |
0.89 |
0.28 |
1.20 |
0.76 |
0.26 |
0.34 |
0.52 |
0.42 |
0.22 |
0.33 |
1.14 |
0.48 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Mean |
0.60 |
|
|
|
|
|
|
|
|
|
|
SD |
0.28 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
Possibly Contaminated Site (n = 75) |
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
1.33 |
0.09 |
0.12 |
0.28 |
0.14 |
0.16 |
0.17 |
0.47 |
0.17 |
0.18 |
0.19 |
0.09 |
18.40 |
0.20 |
0.21 |
0.12 |
0.22 |
0.22 |
0.22 |
168.6 |
0.24 |
0.25 |
0.25 |
0.20 |
0.48 |
0.26 |
5.56 |
0.21 |
0.29 |
0.31 |
0.33 |
3.29 |
0.33 |
0.34 |
0.37 |
0.25 |
2.59 |
0.39 |
0.40 |
0.28 |
0.43 |
6.61 |
0.48 |
0.17 |
0.49 |
0.51 |
0.51 |
0.38 |
0.92 |
0.60 |
0.61 |
0.43 |
0.75 |
0.82 |
0.85 |
0.23 |
0.94 |
1.05 |
1.10 |
0.54 |
1.53 |
1.19 |
1.22 |
0.62 |
1.39 |
1.39 |
1.52 |
0.33 |
1.73 |
2.35 |
2.46 |
1.10 |
51.97 |
2.61 |
3.06 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Mean |
4.02 |
|
|
|
|
|
|
|
|
|
|
SD |
20.27 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
TcCB
1000
100
10
1
0.1
0.01
1 |
2 |
|
Site |
Figure 1.6
Comparison of TcCB measurements in parts per thousand million at a contaminated site (2) and a reference site (1).
18 Statistics for Environmental Science and Management, Second Edition
variable at the possibly contaminated site. Presumably, this might have occurred from the TcCB levels being lowered in parts of the site by cleaning, while very high levels remained in other parts of the site.
Methods for comparing samples such as these in terms of means and variation are discussed further in Chapter 7. For the data in this example, the extremely skewed distribution at the contaminated site, with several very extreme values, should lead to some caution in making comparisons based on the assumption that distributions are normal within sites.
Example 1.8: Delta Smelt in the Sacramento–San Joaquin Delta
The final example considered in this chapter concerns the decline in the abundance of delta smelt (Hypomesus transpacificus) in the Sacramento– San Joaquin Delta in California, that apparently started in about 2000. The delta smelt is classified as a threatened species in the delta, so that there has been particular concern in the decline of this fish, although there is also evidence of the decline of other pelagic fish numbers at the same time.
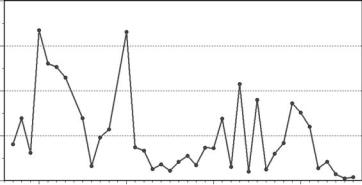
A number of surveys of the abundance of delta smelt take place each year. One of these surveys is called the fall midwater trawl, which samples adults over the four months September to December. From the survey results, an index of abundance is constructed by weighting the densities of fish observed in different parts of the delta by values that reflect the different amounts of habitats expected in those different regions. It is then assumed that the actual abundance of adult delta smelt in any year is proportional to the index value, at least approximately. Figure 1.7 shows the values of the fall midwater trawl index for the years since sampling began. The decline in numbers since 1999 is very clear.
There is much speculation about the cause of the decline in delta smelt numbers. Some claim that it is the result of the water being pumped out of the delta for use in towns and for agriculture, while others suggest
FMWT Abundance Index
2000
1500
1000
500
0
1970 |
1980 |
1990 |
2000 |
Figure 1.7
The fall midwater trawl abundance index for delta smelt for the years since sampling began in 1967, with no sampling in 1974 and 1979.

The Role of Statistics in Environmental Science |
19 |
that, although pumping may cause some reduction in delta smelt numbers, the effect is not enough to account for the very large decline that has been observed. Unfortunately, determining the true cause of the decline is not a simple matter. Regression methods, as discussed in Chapter 3, can be used to find relationships between different variables, but this is not the same as proving causal relationships. To date, a number of explanations for the decline have been proposed, but the true cause is still unknown (Bennett 2005).
1.3 The Importance of Statistics in the Examples
The examples that are presented above demonstrate clearly the importance of statistical methods in environmental studies. With the Exxon Valdez oil spill, problems with the application of the study designs meant that rather complicated analyses were required to make inferences. With the Norwegian study on acid rain, there is a need to consider the impact of correlation in time and space on the water-quality variables that were measured. The estimation of the yearly survival rates of salmon in the Snake River requires the use of special models for analyzing mark-recapture experiments combined with the use of the theory of sampling for finite populations. Monitoring studies such as the one involving the measurement of tree-ring width in Argentina call for the use of methods for the detection of trends and abrupt changes in distributions. Monitoring of whole ecosystems as carried out by the Commission for the Conservation of Antarctic Marine Living Resources requires the collection and analysis of vast amounts of data, with many very complicated statistical problems. The comparison of samples from contaminated and reference sites may require the use of tests that are valid with extremely nonnormal distributions. Attempts to determine the cause of the recent decline in delta smelt and other fish numbers in the Sacramento–San Joaquin Delta has involved many standard and not-so-standard analyses to try to determine the relationship between delta smelt numbers and other variables. All of these matters are considered in more detail in the pages that follow.
1.4 Chapter Summary
•Statistics is important in environmental science because much of what is known about the environment comes from numerical data.
•Three broad types of study of interest to resource managers are baseline studies (to document the present state of the environment), targeted studies (to assess the impact of particular events), and regular monitoring (to detect trends and other changes in important variables).

20Statistics for Environmental Science and Management, Second Edition
•All types of study involve sampling over time and space, and it is important that sampling designs be cost effective and, if necessary, that they can be justified in a court of law.
•Eight examples are discussed to demonstrate the importance of statistical methods to environmental science. These examples involve the shoreline impact of the Exxon Valdez oil spill in Prince William Sound, Alaska, in March 1989; a Norwegian study of the possible impact of acid precipitation on small lakes; estimation of the survival rate of salmon in the Snake and Columbia Rivers in the Pacific Northwest of the United States; a large-scale perturbation experiment carried out in Wisconsin in the United States, involving changing the piscivore and planktivore composition of a lake and comparing changes in the chlorophyll composition with changes in a control lake; monitoring of the annual ring widths of Andean alders near Tucuman in Argentina; monitoring marine life in the Antarctic, comparing a possibly contaminated site with a control site in terms of measurements of the amounts of a pollutant in samples taken from the two sites; and the determination of the cause or causes of a reduction in the numbers of a species of fish (Hypomesus transpacificus, delta smelt) in the Sacramento–San Joaquin Delta.
Exercises
Exercise 1.1
Despite the large amounts of money spent on them, the studies on the effects of the Exxon Valdez oil spill on the coastal habitat of Alaska all failed to produce simple, easily understood estimates of these effects. What happened was that the oil spill took everyone by surprise, and none of the groups involved (state and federal agencies and Exxon) apparently was able to quickly produce a good sampling design and start collecting data. Instead, it seems that there were many committee meetings, but very little actually done while the short Alaskan summer was disappearing. With the benefit of hindsight, what do you think would have been a good approach to use for estimating the effects of the oil spill? This question is not asking for technical details—just a broad suggestion for how a study might have been designed.
Exercise 1.2
The study designs for the estimation of the survival rate of fish through the dams on the Snake River in Washington State have been criticized because the releases of batches of fish were made over short periods of time during only part of the migration season. The mark–recapture estimates may therefore not reflect the average survival rate for all fish over
The Role of Statistics in Environmental Science |
21 |
the whole season if this rate varies during the season. (Issues like this seem to come up with all studies in controversial areas.) Assuming that you know the likely length of the migration season, and roughly how many fish are likely to pass through the dam each week, how would you suggest that the average survival rate be estimated?

2
Environmental Sampling
2.1 Introduction
All of the examples considered in the previous chapter involved sampling of some sort, showing that the design of sampling schemes is an important topic in environmental statistics. This chapter is therefore devoted to considering this topic in some detail. The estimation of mean values, totals, and proportions from the data collected by sampling is covered at the same time, and this means that the chapter includes all methods that are needed for many environmental studies.
The first task in designing a sampling scheme is to define the population of interest as well as the sample units that make up this population. Here the population is defined as a collection of items that are of interest, and the sample units are these items. In this chapter it is assumed that each of the items is characterized by the measurements that it has for certain variables (e.g., weight or length), or which of several categories it falls into (e.g., the color that it possesses, or the type of habitat where it is found). When this is the case, statistical theory can assist in the process of drawing conclusions about the population using information from a sample of some of the items.
Sometimes defining the population of interest and the sample units is straightforward because the extent of the population is obvious, and a natural sample unit exists. At other times, some more-or-less arbitrary definitions will be required. An example of a straightforward situation is where the population is all the farms in a region of a country and the variable of interest is the amount of water used for irrigation on a farm. This contrasts with the situation where there is interest in the impact of an oil spill on the flora and fauna on beaches. In that case, the extent of the area that might be affected may not be clear, and it may not be obvious which length of beach to use as a sample unit. The investigator must then subjectively choose the potentially affected area and impose a structure in terms of sample units. Furthermore, there will not be one correct size for the sample unit. A range of lengths of beach may serve equally well, taking into account the method that is used to take measurements. The choice of what to measure will also, of course, introduce some further subjective decisions.
23

24 Statistics for Environmental Science and Management, Second Edition
2.2 Simple Random Sampling
A simple random sample is one that is obtained by a process that gives each sample unit the same probability of being chosen. Usually it will be desirable to choose such a sample without replacement so that sample units are not used more than once. This gives slightly more accurate results than sampling with replacement, whereby individual units can appear two or more times in the sample. However, for samples that are small in comparison with the population size, the difference in the accuracy obtained is not great.
Obtaining a simple random sample is easiest when a sampling frame is available, where this is just a list of all the units in the population from which the sample is to be drawn. If the sampling frame contains units numbered from 1 to N, then a simple random sample of size n is obtained without replacement by drawing n numbers one by one in such a way that each choice is equally likely to be any of the numbers that have not already been used. For sampling with replacement, each of the numbers 1 to N is given the same chance of appearing at each draw.
The process of selecting the units to use in a sample is sometimes facilitated by using a table of random numbers such as the one shown in Table 2.1. As an example of how such a table can be used, suppose that a study area is divided into 116 quadrats as shown in Figure 2.1, and it is desirable to select a simple random sample of ten of these quadrats without replacement. To do this, first start at an arbitrary place in the table such as the beginning of row five. The first three digits in each block of four digits can then be considered, to give the series 698, 419, 008, 127, 106, 605, 843, 378, 462, 953, 745, and so on. The first ten different numbers between 1 and 116 then give a simple random sample of quadrats: 8, 106, and so on. For selecting large samples, essentially the same process can be carried out on a computer using pseudo-random numbers in a spreadsheet, for example.
2.3 Estimation of Population Means
Assume that a simple random sample of size n is selected without replacement from a population of N units, and that the variable of interest has values y1, y2, …, yn, for the sampled units. Then the sample mean is
n |
|
y = ∑(yi/n) |
(2.1) |
i=1
the sample variance is

Environmental Sampling |
25 |
Table 2.1
Random Number Table
1252 |
9045 |
1286 |
2235 |
6289 |
5542 |
2965 |
1219 |
7088 |
1533 |
9135 |
3824 |
8483 |
1617 |
0990 |
4547 |
9454 |
9266 |
9223 |
9662 |
8377 |
5968 |
0088 |
9813 |
4019 |
1597 |
2294 |
8177 |
5720 |
8526 |
3789 |
9509 |
1107 |
7492 |
7178 |
7485 |
6866 |
0353 |
8133 |
7247 |
6988 |
4191 |
0083 |
1273 |
1061 |
6058 |
8433 |
3782 |
4627 |
9535 |
7458 |
7394 |
0804 |
6410 |
7771 |
9514 |
1689 |
2248 |
7654 |
1608 |
2136 |
8184 |
0033 |
1742 |
9116 |
6480 |
4081 |
6121 |
9399 |
2601 |
5693 |
3627 |
8980 |
2877 |
6078 |
0993 |
6817 |
7790 |
4589 |
8833 |
1813 |
0018 |
9270 |
2802 |
2245 |
8313 |
7113 |
2074 |
1510 |
1802 |
9787 |
7735 |
0752 |
3671 |
2519 |
1063 |
5471 |
7114 |
3477 |
7203 |
7379 |
6355 |
4738 |
8695 |
6987 |
9312 |
5261 |
3915 |
4060 |
5020 |
8763 |
8141 |
4588 |
0345 |
6854 |
4575 |
5940 |
1427 |
8757 |
5221 |
6605 |
3563 |
6829 |
2171 |
8121 |
5723 |
3901 |
0456 |
8691 |
9649 |
8154 |
6617 |
3825 |
2320 |
0476 |
4355 |
7690 |
9987 |
2757 |
3871 |
5855 |
0345 |
0029 |
6323 |
0493 |
8556 |
6810 |
7981 |
8007 |
3433 |
7172 |
6273 |
6400 |
7392 |
4880 |
2917 |
9748 |
6690 |
0147 |
6744 |
7780 |
3051 |
6052 |
6389 |
0957 |
7744 |
5265 |
7623 |
5189 |
0917 |
7289 |
8817 |
9973 |
7058 |
2621 |
7637 |
1791 |
1904 |
8467 |
0318 |
9133 |
5493 |
2280 |
9064 |
6427 |
2426 |
9685 |
3109 |
8222 |
0136 |
1035 |
4738 |
9748 |
6313 |
1589 |
0097 |
7292 |
6264 |
7563 |
2146 |
5482 |
8213 |
2366 |
1834 |
9971 |
2467 |
5843 |
1570 |
5818 |
4827 |
7947 |
2968 |
3840 |
9873 |
0330 |
1909 |
4348 |
4157 |
6470 |
5028 |
6426 |
2413 |
9559 |
2008 |
7485 |
0321 |
5106 |
0967 |
6471 |
5151 |
8382 |
7446 |
9142 |
2006 |
4643 |
8984 |
6677 |
8596 |
7477 |
3682 |
1948 |
6713 |
2204 |
9931 |
8202 |
9055 |
0820 |
6296 |
6570 |
0438 |
3250 |
5110 |
7397 |
3638 |
1794 |
2059 |
2771 |
4461 |
2018 |
4981 |
8445 |
1259 |
5679 |
4109 |
4010 |
2484 |
1495 |
3704 |
8936 |
1270 |
1933 |
6213 |
9774 |
1158 |
1659 |
6400 |
8525 |
6531 |
4712 |
6738 |
7368 |
9021 |
1251 |
3162 |
0646 |
2380 |
1446 |
2573 |
5018 |
1051 |
9772 |
1664 |
6687 |
4493 |
1932 |
6164 |
5882 |
0672 |
8492 |
1277 |
0868 |
9041 |
0735 |
1319 |
9096 |
6458 |
1659 |
1224 |
2968 |
9657 |
3658 |
6429 |
1186 |
0768 |
0484 |
1996 |
0338 |
4044 |
8415 |
1906 |
3117 |
6575 |
1925 |
6232 |
3495 |
4706 |
3533 |
7630 |
5570 |
9400 |
7572 |
1054 |
6902 |
2256 |
0003 |
2189 |
1569 |
1272 |
2592 |
0912 |
3526 |
1092 |
4235 |
0755 |
3173 |
1446 |
6311 |
3243 |
7053 |
7094 |
2597 |
8181 |
8560 |
6492 |
1451 |
1325 |
7247 |
1535 |
8773 |
0009 |
4666 |
0581 |
2433 |
9756 |
6818 |
1746 |
1273 |
1105 |
1919 |
0986 |
5905 |
5680 |
2503 |
0569 |
1642 |
3789 |
8234 |
4337 |
2705 |
6416 |
3890 |
0286 |
9414 |
9485 |
6629 |
4167 |
2517 |
9717 |
2582 |
8480 |
3891 |
5768 |
9601 |
3765 |
9627 |
6064 |
7097 |
2654 |
2456 |
3028 |
Note: Each digit was chosen such that 0, 1, …, 9 were equally likely to occur. The grouping of four digits is arbitrary so that, for example, to select numbers from 0 to 99999, the digits can be considered five at a time.