

Индексно-произвольный метод
В отличие от предыдущего, этот метод основан на использовании плотного индекса. В этом случае число статей индекса равно количеству информационных записей. Суть метода состоит в следующем. Для информационной структуры (файла) формируется индекс, который содержит значения ключей поиска и ссылки на соответствующие записи. При поиске записи вначале в индексе выбирается статья с искомым ключом, затем по ссылке выбирается непосредственно требуемая запись. Поиск однозначен, если он производится по первичному или другому уникальному индексу. В случае вторичного ключа результат поиска – выборка из записей с равными ключами.
Как и в индексно-последовательном методе, нужно стремиться к тому, чтобы весь индекс размещался в памяти. Но в данном случае, в силу плотности индекса, ситуация хуже из-за большего размера индекса. Более того, иногда он может превышать размер информационного файла. Уменьшение области поиска достигается, например, построением многоуровневого индекса. Ключи обычно бывают упорядоченными для последующего дихотомического поиска, но не исключаются и другие алгоритмы. Естественно, упорядоченность записей в информационном файле не существенна, однако иногда она позволяет заметно сократить время работы. Например, выдача отчета по всему файлу с сортировкой по ключу поиска приведет к последовательному просмотру статей индекса, но к хаотичному выбору записей в случае их сильного перемешивания по этому ключу. Это, в свою очередь, приводит к «дерганью» головки дисковода, что резко увеличивает время доступа. Решение проблемы – сортировка по ключу поиска. К замедлению поиска приводит и дублирование значений ключей, следовательно, этот метод наиболее эффективен для первичных индексов.
Итак, эффективность доступа во многом зависит от способа поиска статьи индекса, то есть от способа его организации. Кроме того, на него могут оказывать влияние некоторые свойства ключей (случайное расположение в файле, повторяемость).
Эффективность хранения зависит от размера индекса.
Пример
В приведенном примере список студентов размещается в информационном файле (правый прямоугольник), ссылки на записи хранятся в индексном файле (слева), в качестве ключа выбираются фамилии.
Бабаев Назаров Артюхов Беляев Днепров Селин Яковлева Мурадян
Артюхов 3 Бабаев
1 Беляев
4 Днепров
5 Мурадян
8 Назаров
2 Селин
7 Яковлева
6


Инвертированные списки
Два предыдущих метода ориентировались, в основном, на поиск записей с уникальным значением ключа. Однако нередко возникает задача выбора группы записей по определенным параметрам, каждый из которых не уникален. Более того, записей с каким-то фиксированным значением параметра может быть очень много. Это характерно, например, для библиотечного поиска, когда требуется подобрать книгу с заданным годом издания, автором, издательством и т.п. Для подобных задач существуют специальные методы, наиболее популярный из которых – метод инвертированных списков или инвертированный метод.
Считается, что поиск может проводиться по значениям любых полей (вторичных ключей) или их комбинации. Для каждого вторичного ключа создается индекс. В нем на каждое значение ключа формируется список указателей на записи файла с этим значением. Это не обязательно физическая ссылка, допускается и первичный ключ. Таким образом, инвертированный индекс группируется по именам полей, которые в свою очередь группируются по значениям. При поиске записи с заданным значением ключа выбирается нужный индекс, в нем каким-то способом (например, индексно-произвольным) выбирается статья с этим значением, затем выбирается все список ссылок на записи с искомым значением. Легко видеть, что поиск по комбинации значений полей сводится к выбору соответствующих списков и их пересечению (операция И) или объединению (операция ИЛИ).
Достоинства метода – независимость от объема файла при выборе данных по произвольным значениям ключа, отбор списка записей по сложным условиям без обращения к файлу. Особенно эффективно применение инвертированных списков при выборке данных по совокупности критериев, если атрибуты имеют сравнительно небольшой диапазон значений. Недостаток – большие затраты времени на создание и обновление инвертированных индексов, причем, время зависит от объема данных. Этот метод обычно используется лишь для поиска. Для начальной загрузки данных и обновления используют другие методы.
Эффективность доступа зависит от эффективности поиска в индексе, но в любом случае она ниже 0,5 (доступ к индексу и доступ к записи файла). Для повышения эффективности следует размещать индексы в оперативной памяти.
Студент
Оценка
Бабаев
3 Назаров
5 Артюхов
4 Беляев
5 Днепров
4 Селин
3 Яковлева
4 Мурадян
5
Запись 1 6
Запись 3 5 7
Запись 2 4 8
Оценка
список 3 1 4 2 5 3








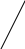

Пример
В приведенном примере в информационном файле (правый прямоугольник) размещается список студентов с оценками. Требуется выбрать всех студентов, имеющих одинаковое значение оценки. Левый прямоугольник символизирует индекс, в котором находится единственный вторичный ключ – «оценка». Каждому его значению соответствует список, в котором перечислены соответствующие номера записей информационного файла. Выбор всех двоечников сводится к нахождению в индексе соответствующего значения ключа «оценка» и загрузки записей, указанных в списке. Если нужно найти тех, кто получил «4» или «5», следует найти и объединить соответствующие списки. Подобные действия выполнялись бы, если бы запись содержала еще один вторичный ключ, скажем, предмет. Тогда для выборки тех, кто получил пятерки по предмету «Базы данных», следовало бы в соответствующих индексах найти списки для требуемых значений и взять их пересечение.
Конец примера