

26. Состав программного комплекса асу.
В составе АСУ выделяют:
- основную часть, в которую входят информационное, техническое и математическое обеспечение; и
- функциональную часть, к которой относятся взаимосвязанные программы, автоматизирующие конкретные функции управления.
27. Модели надежности программного обеспечения
Модель
надежности программного обеспечения
- это математическая модель, построенная
для оценки зависимости надежности
программного обеспечения от некоторых
определенных параметров.
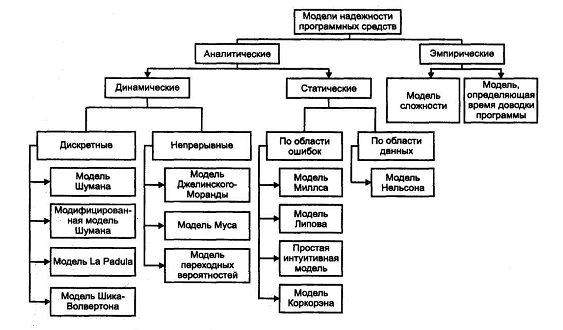
Аналитические модели позволяют рассчитать количественные показатели надежности, основываясь на данных о поведении программы в процессе тестирования. Делятся на динамические и статические. В динамических моделях поведение ПО (появление отказов) рассматривается во времени (дискретные – делятся на интервалы, статические – определнный момент времени на всей числовой оси).
В статических моделях появление отказов не связывают со временем, а учитывают зависимость количества ошибок либо от числа тестовых прогонов, либо от характеристики входных данных.
МОДЕЛЬ ШУМАНА Исходные данные собираются в процессе тестирования ПО. Выявляются ошибки, но не устраняются.
Предполагается, что на начальном этапе в системе имеется ЕT ошибок. После тестирования – EC ошибок обнаружено.
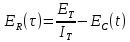
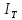 -
общее число машинных команд
-
общее число машинных команд
 -
удельное число ошибок на одну команду
-
удельное число ошибок на одну команду
Частота отказов:
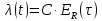
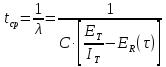
МОДЕЛЬ LA PADULA. По этой модели выполнение последовательности тестов производится за некоторое количество этапов. Каждый этап заканчивается внесением изменений (исправлений) в тестируемую программу. Надежность тестируемой программы в течение 1-го этапа определяется соотношением
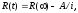
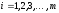
где А — параметр роста.
При бесконечном числе прогонов программы она будет обладать предельной надежностью R(∞):
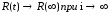
Модель является прогнозной и на основании данных тестирования позволяет предсказать вероятность безотказной работы программы на последующих этапах ее выполнения.
Модель Джелинского - Моранды Исходные данные собираются в процессе тестирования системы. Фиксируется время до очередного отказа. Значение интервалов времени тестирования между обнаружением двух ошибок имеет экспоненциальное распределение с частотой ошибок (или интенсивностью отказов), пропорциональной числу еще не выявленных ошибок. Каждая обнаруженная ошибка устраняется. При этом число оставшихся ошибок уменьшается на единицу.
Функция плотности распределения времени обнаружения I-ой ошибки, отсчитываемого от момента выявления (I-1)-ой ошибки, имеет вид
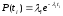
Здесь λ—частота отказов (интенсивность отказов), которая пропорциональна числу еще не выявленных ошибок в программе:
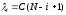
где N— число ошибок, первоначально присутствующих в программе; С— коэффициент пропорциональности.
Рассчитав
значение
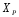 можно определить вероятность безотказной
работы в различных временных интервалах.
На основе полученных расчетных данных
строится график зависимости вероятности
безотказной работы от времени.
можно определить вероятность безотказной
работы в различных временных интервалах.
На основе полученных расчетных данных
строится график зависимости вероятности
безотказной работы от времени.
Модель Шика - Волвертона. Модификация модели Джелинского-Моранды для случая возникновения в рассматриваемом интервале более одной ошибки. Исправление ошибок производится по истечении интервала времени, в котором они возникли.
Частота отказов:
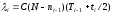
N – число ошибок, первоначально присутствующих в программе;
С – коэффициент пропорциональности;
В данной модели наблюдаемым событием является число ошибок, обнаруживаемых в заданном временном интервале, а не время ожидания каждой ошибки, как это было для модели Джелинского—Мо-ранды.
Модель
Муса
– динамическая модель непрерывного
времени. В процессе тестирования
фиксируется время выполнения программы
до очередного отказа. Предполагается,
что на протяжении всего ЖЦ процесса
выполнения программы может произойти
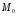 отказов
и при этом будут выявлены все N0
ошибок (до начала тестирования). Общее
число отказов связано с первоначальным
числом ошибок NQ соотношением
отказов
и при этом будут выявлены все N0
ошибок (до начала тестирования). Общее
число отказов связано с первоначальным
числом ошибок NQ соотношением
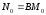

где В — коэффициент уменьшения числа ошибок.
m - отказы, n – ошибки
В модели Муса два вида времени:
1) суммарное время функционирования х – время тестирования до момента оценки;
2) оперативное время T— от контрольного момента и далее, при условии, что дальнейшего устранения ошибок не будет (время безотказной работы в процессе эксплуатации).
Время работы до отказа:
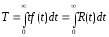
Средняя наработка на отказ:
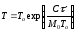
С— коэффициент сжатия тестов, который вводится для устранения избыточности при тестировании. Например, если 1 ч тестирования соответствует 12 ч работы в реальных условиях, то коэффициент сжатия тестов равен 12.
Модель Миллса. Внесение в программу некоторого количества известных ошибок. Собственные и внесенные ошибки имеют равную вероятность быть найденными.
Формулы Миллса – первоначальное число ошибок в программе:
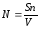
S— количество искусственно внесенных ошибок, п — число найденных собственных ошибок, V— число обнаруженных к моменту оценки искусственных ошибок.
Положим, что в процессе тестирования были обнаружены все S внесенных и л собственных ошибок программы. Тогда по формуле Миллса получим, что первоначально в программе было N= п ошибок. Вероятность, с которой можно высказать такое предположение:
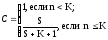
Модель Липова. Усовершенствованная модель Миллса. Собственные и внесенные ошибки имеют равную вероятность быть найденными.
Вероятность обнаружения п собственных и внесенных ошибок:
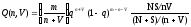
где m — количество тестов; q— вероятность обнаружения; S— общее количество внесенных ошибок; ЛГ— количество собственных ошибок, имеющихся в программе до начала тестирования.
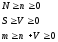
Модель Липова дополняет модель Миллса, позволяя оценить вероятность обнаружения определенного количества ошибок к моменту оценки.