

42. Классификация моделей надежности по.

Аналитическое моделирование надежности ПС включает четыре шага:
1) определение предположений, связанных с процедурой тестирования ПС;
2) разработка или выбор аналитической модели, базирующейся на предположениях о процедуре тестирования;
3) выбор параметров моделей с использованием полученных данных;
4) применение модели — расчет количественных показателей надежности по модели.
Статические модели принципиально отличаются от динамических прежде всего тем, что в них не учитывается время появления ошибок в процессе тестирования и не используется никаких предположений о поведении функции риска. Эти модели строятся на твердом статистическом фундаменте.
Эмпирические модели надежности
Эмпирические модели в основном базируются на анализе структурных особенностей программного средства (или программы). Как указывалось, ранее, эмпирические модели часто не дают конечных результатов показателей надежности, однако их использование на этапе проектирования ПС полезно для прогнозирования требующихся ресурсов тестирования, уточнения плановых сроков завершения проекта и т.д.
43. Модели надежности программного обеспечения: Шумана, Миллса, Нельсон
МОДЕЛЬ ШУМАНА относится к динамическим моделям дискретного времени, данные для которой собираются в процессе тестирования программного обеспечения в течение фиксированных или случайных интервалов времени. Каждый интервал — это стадия, на которой выполняется последовательность тестов и фиксируется некоторое число ошибок.
Целесообразность применения модели Шумана для оценки надежности программного и информационного обеспечения зависит от принятых допущений и условий, наиболее важным из которых является условие существования программы для исследования системы. Остальные допущения и условия не связаны с какими-либо специфическими свойствами программного обеспечения. Они сводятся к следующему.
Предполагается, что в начальный момент компоновки программных средств в системе имеется Еi ошибок. С этого момента начинается отсчет времени отладки tt которое включает затраты времени на выявление ошибок с помощью тестов, на контрольные проверки и т. п. При этом время исправного функционирования системы не учитывается.
Считается, что значение функции частоты отказов m(t) пропорционально числу ошибок, оставшихся в программном обеспечении после использования отведенного на отладку исследуемой программы времени T.
Программа тестирования системы должна снабжать испытываемые программные средства входными данными, отражающими реальные условия функционирования. Такие данные называются функциональным разрезом и определяются главным образом через распределение вероятностей значений входных переменных.
Использование модели Шумана предполагает, что тестирование проводится в несколько этапов. Каждый этап представляет собой выполнение программы на полном комплексе разработанных тестовых данных. Выявленные ошибки регистрируются (собирается статистика об ошибках), но не исправляются. По завершении этапа на основе собранных данных о поведении программно-информационной системы на очередном этапе тестирования может быть использована модель Шумана для расчета количественных показателей надежности. После этого исправляются ошибки, обнаруженные на предыдущем этапе. При необходимости корректируются тестовые наборы и проводится новый этап тестирования. При использовании модели Шумана предполагается, что исходное количество ошибок в программе постоянно и в процессе тестирования может уменьшаться по мере того, как ошибки выявляются и исправляются. Считается, что новые ошибки при корректировке не вносятся. Скорость обнаружения ошибок пропорциональна числу оставшихся ошибок. Общее число программных инструкций в рамках одного этапа тестирования постоянно.
Положим, что до начала тестирования имеется Et ошибок. В течение времени тестирования т обнаруживается £с ошибок в расчете на одну команду программы.
Таким образом, удельное число ошибок на одну команду, оставшихся в системе после т времени тестирования, равно

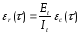
где It — общее число команд программы, которое предполагается постоянным в рамках одного этапа тестирования.
Будем считать, что значение функции частоты отказов Z(t) пропорционально числу ошибок, оставшихся в программе после использования отведенного для тестирования времени т:
![]()
![]()
где С— некоторая постоянная; t—время работы программы без отказов.
Тогда, если время работы программы без отказа отсчитывается от точки t = О, а х остается фиксированным, функция надежности, или вероятность безотказной работы в интервале от 0 до tt будет равна
![]()
![]()
![]()
![]()
Необходимо найти начальное значение ошибок Е и коэффициент пропорциональности С. В процессе тестирования собирается информация о времени и количестве ошибок на каждом прогоне, т. е. общее время тестирования т складывается из времени каждого прогона:
![]()
![]()
Предполагая, что интенсивность появления ошибок постоянна и равна X, можно вычислить ее как число ошибок в единицу времени:
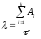
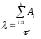
где
![]() — количество ошибок на i-м прогоне.
— количество ошибок на i-м прогоне.
Имея
данные для двух различных моментов
тестирования
![]() и
и![]() ,
которые выбираются произвольно при
условии, что можно записать следующие
соотношения:
,
которые выбираются произвольно при
условии, что можно записать следующие
соотношения:
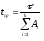
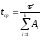
![]()
![]()
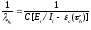

На основании приведенных выше уравнений получим
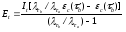
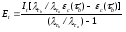
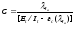
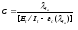
Определив значения £ и С, можно рассчитать надежность программной или информационной системы.
Модель Миллса. Использование этой модели предполагает внесение в программу некоторого количества известных ошибок. Они вносятся случайным образом и фиксируются в протоколе искусственных ошибок. Специалист, проводящий тестирование, не знает ни количества, ни характера внесенных ошибок до момента оценки показателей надежности по модели Миллса. Предполагается, что все ошибки (как имеющиеся в исследуемой программе, так и искусственно внесенные) имеют равную вероятность быть найденными в процессе тестирования. Тестируя программу в течение некоторого времени, собирают статистику об ошибках. В момент оценки надежности по протоколу искусственных ошибок все ошибки делятся на ошибки собственно программы и искусственные.
С помощью соотношения (формулы Миллса)
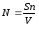
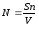
можно оценить первоначальное число ошибок в программе (N). Здесь S— количество искусственно внесенных ошибок, п — число найденных собственных ошибок, V— число обнаруженных к моменту оценки искусственных ошибок.
Например, если в программу внесено дополнительно 50 ошибок и к некоторому моменту тестирования обнаружено 25 собственных и 5 внесенных, то по формуле Миллса делается предположение, что первоначально в программе было 250 ошибок.
Вторая часть модели связана с проверкой гипотезы об оценке первоначального числа ошибок Nb программе. Допустим, что в программе имеется Л" собственных ошибок. Внесем в нее еще 5 ошибок.
Положим, что в процессе тестирования были обнаружены все S внесенных и л собственных ошибок программы. Тогда по формуле Миллса получим, что первоначально в программе было N= п ошибок. Вероятность, с которой можно высказать такое предположение, рассчитывается с помощью следующих соотношений:
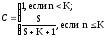
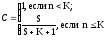
Величина С является мерой «доверия» к модели и показывает вероятность того, насколько правильно найдено значение N. Эти два связанных между собой по смыслу соотношения образуют полезную модель ошибок: первое предсказывает возможное число первоначально имевшихся в программе ошибок, а второе используется для установления доверительного уровня прогноза. Однако приведенная выше формула для расчета С не может быть использована, если не обнаружены все внесенные ошибки.
Если оценка надежности производится до момента обнаружения всех внесенных ошибок (S), величина С рассчитывается по модифицированной формуле:
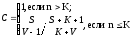
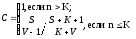
если п < К, где числитель и знаменатель при п< К являются биноминальными коэффициентами вида
![]()
![]()
В реальной практике модель Миллса можно использовать для оценки Nnoaie каждой найденной ошибки. Предлагается во время всего периода тестирования отвечать на графике число найденных ошибок и текущие значения N.
К достоинствам модели относят простоту применяемого математического аппарата, наглядность и возможность использования в процессе тестирования.
Самым существенным недостатком считают необходимость внесения искусственных ошибок (этот процесс плохо формализуем) и достаточно вольное допущение величины Я", которое основывается исключительно на интуиции и опыте испытателя, проводящего оценку, т. е. допускает большое влияние субъективного фактора.
Модель Нельсона создана в аэрокосмической компании CIIIATRW. При расчете надежности программно-информационного обеспечения учитывается вероятность выбора определенного тестового набора для очередного выполнения программы.
Для описания модели вводятся следующие обозначения.
Совокупность действий, включающая ввод выполнение программы и получение результата F'{E^, называется прогоном программы. При этом значения входных переменных, образующих не должны одновременно подаваться на вход программ. Таким образом, вероятность (Р) того, что прогон программы приведет к обнаружению дефекта, равна вероятности того, что набор данных Е.у используемый в прогоне, принадлежит множеству £.
Если обозначить через п число различных наборов входных данных, содержащихся в Е. то
![]()
![]()
есть вероятность того, что прогон программы на наборе входных данных случайно выбранном из Е среди равновероятных, закончится обнаружением дефекта.
Однако в процессе функционирования программы выбор входных данных из Е обычно осуществляется не с одинаковыми априорными вероятностями, а диктуется определенными условиями работы. Эти условия характеризуются некоторым распределением вероятностей (р) того, каким будет выбран определенный набор входных данных Е,
Распределение Р может быть найдено через р. с помощью величины у., которая принимает значение 0, если прогон программы на наборе £ заканчивается получением приемлемого результата, и значение 1, если этот прогон заканчивается обнаружением дефекта. Поэтому
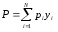

есть вероятность того, что прогон программы на наборе входных данных выбранных случайно с распределением вероятностей закончится обнаружением дефекта. При этом
![]()
![]()
есть вероятность того, что прогон программы на наборе входных данных Е., выбранных случайно с распределением вероятностей р., приведет к получению приемлемого результата.
Так как R— вероятность того, что единичный прогон программы не закончится отказом на наборе входных данных, выбранных в соответствии с распределением рс то вероятность успешного выполнения п прогонов этой программы при независимом для каждого прогона выборе входных данных в соответствии с распределением Р будет равна
![]()
![]()
Таким образом, можно дать следующее математическое определение надежности программы: надежность программы - это вероятность безотказного выполнения п прогонов программы. Поэтому прогон является единичным испытанием программы.
На практике выбор входных данных для каждого прогона нельзя считать независимым. Исключение составляют лишь такие последовательности прогонов, которые определяются возрастающими значениями некоторой входной переменной или некоторым порядком установленных процедур, как в случае программ, работающих в реальном масштабе времени.
С учетом введенного определения функциональный разрез должен быть переопределен в терминах вероятностей р выбора Е. в качестве входных данных при/м прогоне из некоторой последовательности прогонов. Тогда вероятность того, что прогон закончится отказом, может быть записана в виде
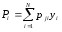
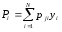
Надежность R(N) программы равна вероятности того, что в последовательности из П прогонов ни один из них не закончится отказом:
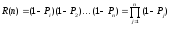
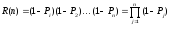
Эта формула может быть представлена в виде
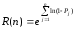
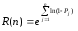
Некоторые свойства функции R(N) могут стать более явными при следующих допущениях:
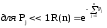
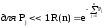
![]()
![]()
С
помощью соответствующих замен переменных
и подстановок можно выразить функцию
R(n) через время функционирования.
Обозначим через ΔT время выполнения
J-RO прогона, а через £
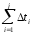 — суммарное время выполнения первых
прогонов программы. Введем А( А):
— суммарное время выполнения первых
прогонов программы. Введем А( А):
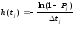
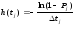
В случае Р« 1 функция A(t) может быть интерпретирована как функция интенсивности отказов, которая, будучи умноженной на Д^, дает условную вероятность появления отказов в интервале (t, t+Δt) при отсутствии отказов до момента t
Тогда
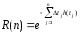
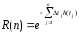
На практике вероятность выбора очередного набора данных для прогона (Р) определяется путем разбиения всего множества значений входных данных на подмножества и нахождения вероятностей того, что выбранный для очередного прогона набор данных будет принадлежать конкретному подмножеству. Определение этих вероятностей основано на эмпирической оценке вероятности появления тех или иных входов в реальных условиях функционирования.
Поскольку в основу модели Нельсона положены свойства программного обеспечения, она допускает развитие за счет более детального описания других аспектов надежности. Некоторые из полученных обобщений модели могут рассматриваться в контексте исследования проблемы безопасности программ. Вследствие отмеченных особенностей модели ее можно рассматривать в целом как математическую теорию надежности программного и информационного обеспечения, а не как простую модель надежности.