

44) Принципы повышения надежности и готовности вычислительных систем.
Двумя основными проблемами построения вычислительных систем для критически важных приложений, связанных с обработкой транзакций, управлением базами данных и обслуживанием телекоммуникаций, являются обеспечение высокой производительности и продолжительного функционирования систем. Наиболее эффективный способ достижения заданного уровня производительности - применение параллельных масштабируемых архитектур. Задача обеспечения продолжительного функционирования системы имеет три составляющих: надежность, готовность и удобство обслуживания. Все эти три составляющих предполагают, в первую очередь, борьбу с неисправностями системы, порождаемыми отказами и сбоями в ее работе. Эта борьба ведется по всем трем направлениям, которые взаимосвязаны и применяются совместно.
Повышение надежности основано на принципе предотвращения неисправностей путем снижения интенсивности отказов и сбоев за счет применения электронных схем и компонентов с высокой и сверхвысокой степенью интеграции, снижения уровня помех, облегченных режимов работы схем, обеспечение тепловых режимов их работы, а также за счет совершенствования методов сборки аппаратуры. Повышение уровня готовности предполагает подавление в определенных пределах влияния отказов и сбоев на работу системы с помощью средств контроля и коррекции ошибок, а также средств автоматического восстановления вычислительного процесса после проявления неисправности, включая аппаратурную и программную избыточность, на основе которой реализуются различные варианты отказоустойчивых архитектур. Повышение готовности есть способ борьбы за снижение времени простоя системы. Основные эксплуатационные характеристики системы существенно зависят от удобства ее обслуживания, в частности от ремонтопригодности, контролепригодности и т.д.
Существует несколько типов систем высокой готовности, отличающиеся своими функциональными возможностями и стоимостью. Следует отметить, что высокая готовность не дается бесплатно. Стоимость систем высокой готовности на много превышает стоимость обычных систем. Вероятно поэтому наибольшее распространение в мире получили кластерные системы, благодаря тому, что они обеспечивают достаточно высокий уровень готовности систем при относительно низких затратах. Термин "кластеризация" на сегодня в компьютерной промышленности имеет много различных значений. Строгое определение могло бы звучать так: "реализация объединения машин, представляющегося единым целым для операционной системы, системного программного обеспечения, прикладных программ и пользователей". Машины, кластеризованные вместе таким способом могут при отказе одного процессора очень быстро перераспределить работу на другие процессоры внутри кластера. Это, возможно, наиболее важная задача многих поставщиков систем высокой готовности.
Кластеризация вычислительных систем.
Как свидетельствуют многочисленные публикации, наиболее рациональным (с точки зрения финансовых затрат) решением задач обеспечения отказоустойчивости вычислительных систем АСОИУ являются кластерные системы (называемые в инженерной практике кластерами).
Кластер представляет собой программно-аппаратный комплекс, предназначенный для организации единой вычислительной среды на распределенной аппаратной базе.
Кластерные системы имеют дополнительный уровень избыточности — избыточное количество ЭВМ (или вычислительных серверов) в составе кластера. ЭВМ связаны между собой локальной (внутренней) сетью (например, Ethernet) и взаимодействуют при помощи специального программного обеспечения (кластерного ПО).
Важным требованием, предъявляемым к кластерам, является «прозрачность» системы относительно запросов внешнего пользователя (удаленного сетевого клиента), т. е. при обращении к кластеру по сети для решения каких-либо задач пользователь не обязан знать о его внутренней структуре. Иными словами, кластер является единым целым с точки зрения удаленного сетевого клиента.
Термин «кластеризация» имеет много различных значений. Строгое определение могло бы звучать так: «реализация объединения машин, представляющегося единым целым для операционной системы, системного программного обеспечения, прикладных программ и пользователей». Машины, «кластеризованные» вместе, могут при отказе одного процессора быстро перераспределить работу на другие процессоры внутри кластера. Это, возможно, наиболее важная задача многих производителей систем высокой готовности.
Впервые в классификации вычислительных систем термин «кластер» определила компания Digital Equipment Corporation (DEC).
По определению DEC, кластер — это группа вычислительных машин, которые связаны между собою и функционируют как один узел обработки информации.
Кластер функционирует как единая система, т. е. для пользователя или прикладной задачи вся совокупность вычислительной техники выглядит как один компьютер. Именно это и является самым важным при построении кластерной системы.
К общим требованиям, предъявляемым к кластерным системам, относятся:
• высокая готовность;
• высокое быстродействие;
• масштабирование;
• общий доступ к ресурсам;
• удобство обслуживания.
Естественно, что при частных реализациях одни из требований ставятся во главу угла, а другие отходят на второй план. Так, при реализации кластера, для которого самым важным является быстродействие, для экономии ресурсов меньше значения придают высокой готовности.
В функциональной классификации кластеры можно разделить на высокоскоростные (High Performance, HP), системы высокой готовности (High Availability, НА), смешанные системы.
Смешанные системы объединяют особенности как первых, так и вторых. Позиционируя их, следует отметить, что кластер, который обладает параметрами как High Performance, так и High Availability, обязательно проиграет в быстродействии системе, ориентированной на высокоскоростные вычисления, и в возможном времени простоя системе, ориентированной на работу в режиме высокой готовности.
Функционал отказоустойчивого кластера обеспечивается дублированием всех жизненно важных компонентов. Максимально отказоустойчивая система должна не иметь ни единой критической точки (рис. 7.4), т. е. активного элемента, отказ которого может привести к потере функциональности системы. Такую характеристику, как правило, называют NSPF (No Single Point of Failure — отсутствие единой точки отказа). Коммутаторы 1 и 2 на рис. 7.4 служат для связи кластера с внешней сетью, а коммутаторы 3 и 4 — для организации внутренней сети кластера для передачи информации между узлами.
Благодаря кластеризации достигается такая схема функционирования, когда при отказе одного из компьютеров задачи перераспределяются между другими узлами кластера, которые функционируют исправно. Причем одной из важнейших задач производителей кластерного программного обеспечения является обеспечение минимального времени восстановления системы в случае сбоя, так как отказоустойчивость системы нужна именно для минимизации так называемого непланового простоя.
Схемы конфигурирования кластерных систем.
Существует огромное количество кластерных конфигураций. Иногда то, что называют кластером, представляет собой объединение нескольких кластеров, да еще вместе с дополнительными устройствами. Тем не менее каким бы ни был кластер, его всегда можно квалифицировать в соответствии со следующими двумя критериями.
Первый характеризует наличие оперативной памяти узлов кластера. Здесь возможны два варианта: либо все узлы кластера имеют независимую оперативную память, либо у них существует общая разделяемая память (возможно, вдобавок к независимой памяти), доступная всем узлам кластера.
Второй критерий характеризует степень доступности устройств ввода-вывода и прежде всего дисков.
Понятие кластеров с разделяемыми дисками (shared disk) подразумевает, что любой узел имеет прозрачный доступ к любой файловой системе общего дискового пространства. Помимо разделяемой дисковой подсистемы на
узлах кластера могут иметься локальные диски, но в этом случае они используются, главным образом, для загрузки ОС на узле. Такой кластер, как правило, имеет специальную подсистему, называемую «распределенный менеджер блокировок» (Distributed Lock Manager, DLM), для устранения конфликтов при одновременной записи в файлы с разных узлов кластера.
Кластеры без разделения ресурсов (shared nothing), как и следует из названия, не имеют общих устройств ввода-вывода. Правда, здесь есть одна тонкость: речь идет об отсутствии общих дисков на логическом, а не на физическом уровне. Это означает, что на самом деле дисковая подсистема может быть подключена сразу ко всем узлам. Если на дисковой подсистеме имеется несколько файловых систем (или логических/физических дисков), то в любой конкретный момент доступ к определенной файловой системе предоставляется только одному узлу. К другой файловой системе доступ может иметь (т. е. владеть ресурсом) совсем другой узел.
Такая схема применяется для того, чтобы в случае отказа одного узла ресурс мог быть передан другому узлу. Например, если ЭВМ 1 владеет диском 1, а ЭВМ 2 — диском 2, то при отказе ЭВМ 1 ЭВМ 2 получит прямой доступ (права владения ресурсом) как к диску 2, так и к диску 1. За счет этого и достигается высокий уровень доступности
в кластерах без разделения ресурсов с общей дисковой системой. Дисковые подсистемы обычно подключают через разделяемый интерфейс SCSI либо с помощью Fibre Channel.
В некоторых кластерных конфигурациях без разделения ресурсов с общей дисковой подсистемой узел может получать доступ к не принадлежащему ему ресурсу косвенным путем, через владельца ресурса.
Тем не менее широкое применение, особенно для вычислительных задач и сервиса Web, получили кластеры, у которых общие ресурсы вообще отсутствуют, даже подключенные на физическом уровне. Обычно в качестве хранилища информации они задействуют внешние серверы (файловые, серверы БД и т. д.).
Наиболее просто на аппаратном уровне и уровне ОС реализуется схема с разделяемыми дисками: достаточно установить многоканальную дисковую подсистему (это позволяют сделать многие массивы RAID) и подключить ее к узлам кластера, чтобы получить доступ к любой файловой системе. Однако написание такого драйвера представляет собой исключительно сложную задачу, поэтому обходится достаточно дорого. Большинство современных кластеров (и не только для процессоров Intel) задействуют схему без разделения ресурсов с общей дисковой подсистемой. Ее организовать гораздо проще, хотя она и требует определенных усилий по модернизации ОС и (или) программного обеспечения.
Конфигурирование работы кластерных систем высокой готовности.
Существует два варианта конфигурирования работы кластерных систем высокой готовности, которые отвечают требованиям различных пользователей и приложений. Кластеры конфигурируются по схемам «активный — активный» и «активный — резервный».
Схема «активный — резервный» — самое универсальное решение в том случае, если лишь часть ресурсов задействована для выполнения критичных по надежности приложений. В такой системе в простейшем случае имеются один активный сервер, выполняющий наиболее важные приложения, и резервная машина, которая может находиться в режиме ожидания или же решать менее критичные задачи. При сбое активного сервера все его приложения автоматически переносятся на резервный, где в свою очередь заканчивают работу приложения с более низким приоритетом. Такая конфигурация позволяет исключить замедление работы критичных приложений. При этом пользователи не заметят никаких изменений. Частный случай этой схемы — конфигурация «пассивный — резервный», в которой резервный сервер не несет никакой нагрузки и находится в режиме ожидания.
При построении кластеров с активным резервным сервером можно иметь полностью дублированные серверы с их собственными отдельными дисками. Для этого необходимо постоянно копировать данные с основного сервера на резервный. В случае возникновения сбоя резервный сервер будет иметь достоверные данные. Поскольку данные полностью продублированы, клиент получает доступ к любому серверу, что позволяет говорить о балансировке нагрузки в подобном кластере. К тому же узлы такого кластера могут быть разнесены географически, что делает конфигурацию устойчивой к различного рода критическим ситуациям. Данный подход обеспечивает высокодоступное решение, но имеет и ряд недостатков. Во-первых, необходимость постоянно копировать данные означает, что часть вычислительных и сетевых ресурсов будет непрерывно расходоваться на синхронизацию. Во-вторых, даже самый быстрый сетевой интерфейс между серверами внутри кластера не исключает задержек при передаче информации, что в конечном счете может привести к десинхронизации, если один сервер вышел из строя и не все транзакции, произведенные с его диском, отразились на диске второго сервера.
Конфигурация «активный — активный» подразумевает исполнение всеми серверами кластера отдельных приложений одинаково высокого приоритета. В случае сбоя приложения с неработающей машины распределяются по оставшимся, что, конечно, сказывается на общей производительности. Кластеры «активный — активный» могут существовать только в качестве выделенных систем и не позволяют запускать низкоприоритетные задачи типа поддержки офисной работы.
Технология резервирования данных RAID.
Кластеры могут иметь разделяемую память на внешних дисках, как правило, на дисковом массиве RAID. Дисковый массив RAID — это серверная подсистема ввода- вывода для хранения данных большого объема. В массивах RAID значительное число дисков относительно малой емкости используется для хранения крупных объемов данных, а также для обеспечения более высокой надежности и избыточности. Подобный массив воспринимается компьютером как единое логическое устройство.
Существуют
следующие уровни спецификации массивов
RAID: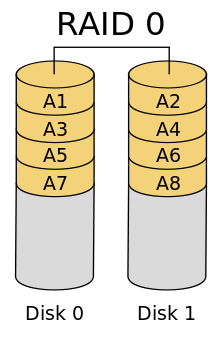
RAID 0 — дисковый массив повышенной производительности с чередованием, без отказоустойчивости;
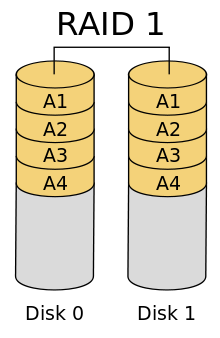
RAID 1 — зеркальный дисковый массив
RAID 2 зарезервирован для массивов, которые применяют код Хемминга;
RAID 3 и 4 — дисковые массивы с чередованием и выделенным диском чётности;
RAID
5 — дисковый массив с чередованием и
«невыделенным диском чётности»;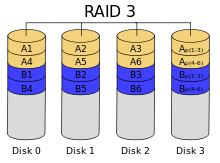
RAID
6 — дисковый массив с чередованием,
использующий две контрольные суммы,
вычисляемые двумя независимыми способами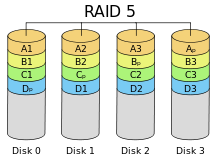
RAID
10 — массив RAID 0, построенный из массивов
RAID 1;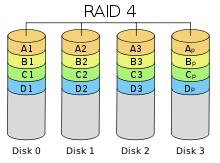
RAID 50 — массив RAID 0, построенный из массивов RAID 5;
RAID
60 — массив RAID 0, построенный из массивов
RAID 6.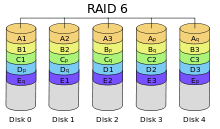
Сравнение уровней RAID представлено в таблице 2.
|
Уровень |
Количество дисков |
Эффективная ёмкость* |
Допустимое количество вышедших из строя дисков |
Надёжность |
Скорость чтения |
Скорость записи |
Примечание |
|
0 |
от 2 |
S * N |
нет |
очень низкая |
высокая |
высокая |
полная потеря данных при выходе из строя любого из дисков! |
|
1 |
от 2 |
S |
N-1 диск |
высокая |
высокая |
низкая |
двойная стоимость дискового пространства |
|
1E |
от 3 |
S * N / 2 |
N/2-1 диск |
высокая |
высокая |
низкая |
двойная стоимость дискового пространства |
|
10 |
от 4, чётное |
S * N / 2 |
от 1 до N/2 дисков** |
средняя |
высокая |
высокая |
двойная стоимость дискового пространства |
|
5 |
от 3 |
S * (N - 1) |
1 диск |
средняя |
высокая |
средняя |
|
|
50 |
от 6, чётное |
S * (N - 2) |
от 1 до 2 дисков*** |
низкая |
высокая |
высокая |
|
|
51 |
от 6, чётное |
S * (N - 1) / 2 |
от 2 до N/2+1 дисков**** |
высокая |
высокая |
низкая |
двойная стоимость дискового пространства |
|
5E |
от 4 |
S * (N - 2) |
1 диск |
средняя |
высокая |
высокая |
резервный накопитель работает на холостом ходу и не проверяется |
|
5EE |
от 4 |
S * (N - 2) |
1 диск |
средняя |
высокая |
высокая |
резервный накопитель работает на холостом ходу и не проверяется |
|
6 |
от 4 |
S * (N - 2) |
2 диска |
высокая |
высокая |
низкая |
|
|
60 |
от 8, чётное |
S * (N - 4) |
от 2 до 4 дисков*** |
средняя |
высокая |
средняя |
|
|
61 |
от 8, чётное |
S * (N - 2) / 2 |
от 4 до N/2+2 дисков**** |
высокая |
высокая |
низкая |
двойная стоимость дискового пространства |
Таблица 1
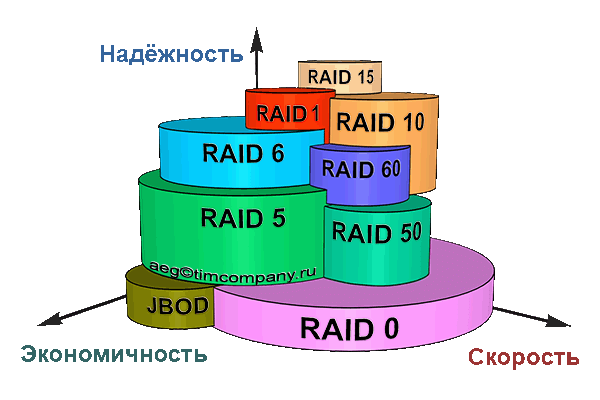
Проанализировав таблицу, можно построить диаграмму (см рис. 12), на которой эти массивы размещены в трехмерном пространстве надежности, производительности и ценовой эффективности.
Программное обеспечение, используемое на кластерных системах.
Выполняемые кластером программы условно делятся на следующие категории: обычные, рассчитанные на работу в кластере (cluster-aware) и истинно кластерные. Большинство пользователей в первую очередь интересует вопрос о возможности использования в кластерах обычных программ. На данный вопрос можно ответить утвердительно, хотя это справедливо не для всех приложений.
Действительно, на любом узле можно запустить обычную программу. Например, на ЭВМ 1 можно запустить сервис Web, а на ЭВМ 2 — сервис FTP. При этом сервис Web использует файловую систему Web, а сервис FTP — файловую систему FTP. Допустим, произошел отказ ЭВМ 1. В этом случае файловая система Web перейдет в распоряжение ЭВМ 2. Одновременно на этом же узле будет запущен сервис FTP. Данная процедура носит название миграции (failover) процесса и его ресурса. Процедура передачи прав на ресурс и условия миграции приложения задаются администратором по своему усмотрению. В частности, администратор может вообще отменить миграцию или, при наличии нескольких узлов, оговорить приоритет миграции по узлам. При восстановлении работоспособности узла ЭВМ 1 сервис Web вновь перейдет (fallback) в его владение. Администратор может определить условие, чтобы обратная миграция не производилась.
Кроме того, одну и ту же программу можно запускать на разных узлах кластера. Однако каждая копия программы должна использовать собственный ресурс (файловую систему), поскольку файловая система закрепляется за конкретным узлом. Таким образом, на ЭВМ 1 можно запустить сервер Web, обслуживающий определенный домен, а на ЭВМ 2 — сервер Web, обслуживающий другой домен. При отказе ЭВМ 1 сервис Web-домена и используемая им файловая система отойдут к ЭВМ 2.
Таким образом, масштабирование и увеличение производительности кластера для обычных приложений и служб достигаются путем их распределения между узлами. Следует иметь в виду, что не все приложения и службы поддерживают миграцию, хотя их значительное меньшинство.
Помимо обычных программ для кластеров существуют так называемые истинно кластерные приложения. Такие программы как бы разносятся по узлам кластера, а между частями программы, функционирующими на разных узлах, организуется взаимодействие. Истинно кластерные программы позволяют распараллелить нагрузку на кластер. В первом приближении можно считать, что любой узел кластера может обслуживать любой запрос клиента, за счет чего достигается динамическое выравнивание нагрузки на узлы кластера.
Подходов к их написанию существует множество, но большинство коммерческих истинно кластерных приложений построено по принципу «последовательная программа, параллельная подсистема» (Serial Program, Parallel Subsystem, SPPS). Под последовательной программой подразумевается обычная программа, рассчитанная на выполнение на одном сервере (в том числе SMP).
Согласно модели SPPS, разработчики пишут обычную программу, а за обеспечение параллелизма и взаимодействие между узлами кластера отвечает специальная подсистема (Parallel System). В соответствии с принципом SPPS построены практически все кластерные СУБД. Высокая доступность достигается благодаря тому, что выход из строя любого узла никак не влияет на работоспособность кластера, хотя тот и может испытывать некоторую перегрузку.
Промежуточную позицию занимают приложения, рассчитанные на работу в кластере. В отличие от истинно кластерных программ в них явный параллелизм не используется; фактически программа является обычной, но она способна задействовать некоторые возможности кластера, в первую очередь, с точки зрения миграции ресурсов.
Дело в том, что не все пользовательские программы позволяют одновременно запускать несколько своих копий на одном компьютере. В частности, на одной машине невозможно запустить несколько копий обычной (не кластерной) СУБД, даже если они обращаются к разным файлам (это связано с тем, что одна копия может обслуживать множество файлов).
Исходя из состава решаемых системой задач, можно выделить следующие этапы основного цикла работы кластера:
- опрос ЭВМ кластера (выявление работающих процессов и активных ЭВМ);
- анализ и принятие решений для поддержания работоспособности системы;
- исполнение действий в целях обеспечения работоспособности системы.
Для реализации такого цикла на распределенной системе необходимо предусмотреть два автономных программных модуля: исполнительный и управляющий.
Исполнительный модуль является представителем системы «на местах», т. е. осуществляет сбор информации о локальной ЭВМ по запросу «из центра» и выполнение управляющих указаний (запуск процесса, останов процесса и ряд других внутренних операций). Таким образом, этот модуль должен быть запущен на каждой ЭВМ в составе кластера.
Управляющий модуль является «мозгом» всей системы и запускается только на одной ЭВМ, которая на данный момент определена как ведущая. Именно он производит циклы последовательного опроса всех участников системы и делает выводы о неработоспособности того или иного процесса.
49
ДОСТОВЕРНОСТЬ ИНФОРМАЦИИ [reliability of information] — соответствие принятого сообщения переданному. Количественное ее определение основывается на вероятности возникновения ошибок при передаче информации. Причем одни авторы считают, что Д. и. — величина, изменяющаяся в обратно пропорциональной зависимости по отношению к вероятности ошибок, а другие определяют ее как разность — единица минус вероятность ошибки.
В любой информационной системе задача состоит в достижении максимальной достоверности передачи информации. Для этого применяются различные математические и логические приемы выявления ошибок, включаемые в компьютерные программы, а также многократное повторение передачи одинаковых данных. (См. Избыточная информация.) И все же какая-то доля ошибок неизбежна. Вероятность необнаруженных ошибок при решении экономических задач признается допустимой в пределах от одной тысячной (задачи оперативно-производственного планирования) до одной миллионной (бухгалтерский учет). При таких жестких условиях можно считать информацию достоверной.
В общем случае под достоверностью понимается форма существования истины, обоснованной каким-либо способом (например, экспериментом, логическим доказательством). Под достоверностью информации понимается степень или уровень адекватного отображения ею объективно существующих явлений, событий или процессов [15, 16]. Наряду с ценностью, своевременностью, полнотой, доступностью и т.д. достоверность является одним из основных свойств информации.
Достоверность, или надежность информации связана с вероятностью возникновения ошибок. Понятие "ошибка" в данном случае целесообразно рассматривать как искажение информации, поддающееся с определенной вероятностью обнаружению и регистрации.
Ошибки, возникающие в процессе функционирования ЭИС, можно рассматривать как композицию следующих потоков ошибок: разработки (проектирования); производства (ошибки операторов); исходных данных в линиях связи при передаче данных; возникающих при записи и хранении информации на магнитных носителях; сбоев технических устройств.
При исследовании достоверности могут использоваться уж рассмотренные ранее формы задания
распределений вероятностей случайных величин: F (x); f (x); Р (х); λ (x), т.е. достоверность может оцениваться вероятностью наличия ошибки в файле информации, плотностью ошибок, вероятностью отсутствия ошибки (собственно достоверность), интенсивностью ошибок. Следует отметить, что в качестве аргумента в данном случае могут использоваться как время (t), так и объем (Q) обрабатываемой информации (чаще всего в знаках). В случае экспоненциального характера функции вероятности отсутствия искажения интенсивность отказов является величиной обратной среднему объему информации, приходящемуся на одну ошибку.
В общем виде постановка задачи обеспечения рациональной достоверности результатной информации может быть сформулирована следующим образом: из допустимого множества приемов и методов повышения достоверности выбрать такое его подмножество, которое обеспечивало бы минимальные
суммарные потери, обусловленные, с одной стороны, приведенными затратами на создание и функционирование системы, а с другой – потерями от низкой достоверности результатной информации.
Состав допустимого множества приемов и методов повышения достоверности предопределяется причинами искажения информации в процессе ее обработки. К таким причинам чаще всего относят: ошибки проектирования; ошибки, связанные с потерей точности вследствие наличия погрешности в исходных данных, ограничений на длину машинного слова, погрешности расчетных формул; случайные или преднамеренные искажения при регистрации информации в первичных документах (или носителях); ошибки при переносе информации на машинные носители; помехи в линиях связи при передачи данных; искажения вследствие сбоев технических устройств; искажения, возникающие при хранении данных.
Каждому типу причин искажений информации может быть поставлен в соответствие один или несколько методов их устранения. Так, искажения, вызванные ошибками проектирования и потерей точности, во многом схожи с программными ошибками. Появление ошибок такого типа функционально зависит от текущей входной информации и состояния системы. Поэтому для их устранения могут быть использованы приемы и методы обеспечения надежности программ [19].
Остальные причины искажения информации имеют стохастический характер, что предопределяет возможность более широкого применения некоторых методов, известных из теории надежности технических систем. Однако с учетом специфики информации (например, отсутствие физического износа) и ее значения как продукта функционирования ЭИС можно выделить:
• приемы и методы, обеспечивающие уменьшение вероятности внесения ошибок;
• приемы и методы обнаружения и исправления ошибок.
К первой группе относятся методы, направленные на уменьшение вероятности сбоев технических средств, уменьшение удельного веса работ, выполняемых с участием человека как наименее надежного звена ЭИС [ 8, 15, 16 ]; повышение квалификации и стимулирование высокого качества работы операторов; использование удобных для оператора форм представления исходной информации и т.д.
Эффективность организационно-технических мероприятий, направленных на реализацию данных методов, имеет известные ограничения. Так, использование более надежных, а следовательно, и более дорогих технических средств может значительно снизить экономическую эффективность системы. Повышение качества работы оператора ограничено психофизиологическими возможностями человека и сопряжено, как правило, с увеличением времени выполнения соответствующих операций.
Методы второй группы предполагают выполнение контрольных операций и соответствующую выявленным ошибкам коррекцию информации.
В качестве аспектов классификации данных методов обычно выделяют:
• охват операций технологического процесса обработки данных;
• тип избыточности;
• используемые средства реализации контроля;
• используемый метод исправления ошибок.
С точки зрения охвата операций технологического процесса в множестве методов контроля и исправления данных можно выделить два подмножества: внутриоперационные и послеоперационные методы контроля. В первое подмножество входят методы контроля, позволяющие выявить и исправить ошибки, сделанные в ходе выполнения операции, результаты которой контролируются. Сюда, например, относят методы контроля перфорации, позволяющие определить ошибки в информации, возникающие при ее переносе на машинные носители, но не обнаруживающие искажения данных при их регистрации в первичных документах. Второе подмножество включает методы контроля, позволяющие выявить ошибки, сделанные при выполнении нескольких, а в частном случае всех предшествующих операций. К таким методам можно, например, отнести контроль, основанный на смысловой проверке информации.
В зависимости от типа избыточности выделяют методы контроля, использующие естественную избыточность и специально вводимую функциональную, техническую, информационную, программную, временную избыточность.
Естественная избыточность бывает, как правило, информационной и связана с наличием логических соотношений показателей и использованием имеющейся в системе нормативно-справочной информации. Кроме того, для многих ЭИС естественной является и временная избыточность, проявляю-
щаяся в наличии некоторого интервала времени между периодом наиболее раннего завершения обработки информации и моментом передачи информации пользователю. К данной группе методов относится различного типа логический контроль информации, содержащейся как в пределах одного массива, так и в разных наборах данных, контроль, основанный на сопоставлении со справочниками, номенклатурами-ценниками и т.д. Как показывает практика, методы контроля данной группы экономически наиболее эффективны, так как не требуют дополнительных затрат, связанных с введением специальной избыточности.
Однако возможности данных методов, как правило, ограничены, так как далеко не все обрабатываемые единицы информации взаимосвязаны.
Наиболее представительная группа методов контроля и исправления информации предполагает введение того или иного типа избыточности. Для большинства ЭИС является характерным введение специальной информационной избыточности. Сюда следует отнести методы, основанные на сравнении массивов, подготовленных на основе одних и тех же первичных документов, счетный контроль, верификацию, контроль по модулю, использование кода Хеминга и т.д.
С точки зрения используемых средств реализации контроля можно выделить методы контроля, реализуемые человеком (например, самоконтроль оператора), аппаратурные и программные методы. Выделение последней подгруппы до некоторой степени условно, так как естественно, что реализация программных средств предполагает использование техники, однако, в отличие от сугубо аппаратных методов в данном случае необходима разработка соответствующих программ.
В зависимости от используемых методов исправления ошибок следует выделять методы обеспечения достоверности с неавтоматическим и автоматическим исправлением ошибок. В настоящее время наиболее распространены методы первой группы, предполагающие участие человека в анализе результатов контроля и подготовке корректуры. Автоматическое исправление ошибок используется гораздо реже и распространено в основном на признанную информацию и в некоторых случаях на данные, передаваемые по каналам связи. Однако на практике известны примеры использования автоматической корректировки обрабатываемой информации. Один из возможных вариантов реализации такого подхода можно представить следующим образом. Предположим, в систему необходимо ввести очень важную информацию, представленную в виде документов табличной формы. На первом этапе обработки информации в данном случае рассчитываются контрольные суммы по строкам и графам документов. На втором этапе информация переносится на машинный носитель и вводится в память ЭВМ. С помощью программы контроля проверяются контрольные суммы, и в случае обнаружения расхождений определяются координаты ошибочного реквизита. При концентрации ошибок в одной графе или в одной строке документа происходит автоматическое их исправление и выдача соответствующего сообщения на печать. В противном случае выдаются традиционные сообщения об ошибках. Особенно выгоден данный подход при наличии соответствующей естественной избыточности (необходимых контрольных сумм).
Многообразие методов контроля и исправления информации, конкретные условия их использования не позволяют однозначно решить вопрос о их применении в том или ином случае без проведения расчетов, связанных с оценкой эффективности различных методов.