

3.2. Построение регрессионной модели и её интерпретация
Будем использовать алгоритм пошагового регрессионного анализа с последовательным исключением незначимых регрессоров, пока все входящие в регрессионную модель факторы не будут иметь значимые коэффициенты.
Построение и оценка регрессионной модели осуществляется в Excel с помощью модуля регрессии пакета анализа данных. (Если по каким-то причинам недоступен пакет анализа данных, все основные параметры регрессионной модели можно получить с помощью встроенной статистической функции Excel ЛИНЕЙН и остальные расчёты произвести по формулам, рассматриваемым далее).
Выбираем в меню (Office 2003)
 СЕРВИС
СЕРВИС
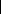 Анализ
данных (Data
Analysis)
Анализ
данных (Data
Analysis)
Регрессия (Regression)
или в меню Office 2007
 ДАННЫЕ
ДАННЫЕ
 Анализ
данных (Data
Analysis)
Анализ
данных (Data
Analysis)
Регрессия (Regression)
Элементы диалогового окна «Регрессия»
1. Входной интервал y (Input y Range)
Введите ссылку на диапазон анализируемых зависимых данных. Диапазон должен состоять из одного столбца - зависимой переменной Y.
2. Входной интервал X (Input X Range)
Введите ссылку на диапазон независимых данных, подлежащих анализу. Microsoft Excel располагает независимые переменные этого диапазона слева направо в порядке возрастания. Максимальное число входных диапазонов равно 16.
Введем массив объясняющих переменных (X1, X2, X3 , X4).
3. Метки (Labels)
Установите флажок, если первая строка или первый столбец входного интервала содержит заголовки. Снимите флажок, если заголовки отсутствуют; в этом случае подходящие названия для данных выходного диапазона будут созданы автоматически.
4. Уровень надежности (Confidence Level)
Установите флажок, чтобы включить в выходной диапазон дополнительный уровень. В соответствующее поле введите уровень надежности, который будет использован дополнительно к уровню 95%, применяемому по умолчанию.
Можно указать здесь ещё какой-нибудь уровень надёжности – например, 98%, тогда для коэффициентов регрессии будет построено два интервала – для γ=0,95 и γ=0,98).
5. Константа – ноль (Constant is Zero)
Установите флажок, чтобы линия регрессии прошла через начало координат.
У нас нет такой цели, поэтому этот флажок
не устанавливаем.
нас нет такой цели, поэтому этот флажок
не устанавливаем.
Важное замечание.
Это необходимо будет сделать тем, у кого на последнем этапе, когда в регрессионной модели все коэффициенты регрессии при всех факторных признаках Xi будут значимы, и окажется только коэффициент b0 (const) – незначим. Вот тогда регрессионный анализ проводят ещё раз, убирая из анализа эту незначимую константу, установив соответствующий флажок.
6. Выходной диапазон
Введите ссылку на левую верхнюю ячейку выходного диапазона. Отведите, по крайней мере, семь столбцов для итогового диапазона, который будет включать в себя: результаты дисперсионного анализа, коэффициенты регрессии, стандартную погрешность вычисления Y, среднеквадратичные отклонения, число наблюдений, стандартные погрешности для коэффициентов.
7. Новый лист
Установите переключатель, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. Если в этом есть необходимость, введите имя нового листа в поле, расположенном напротив соответствующего положения переключателя.
8. Новая книга
Установите переключатель, чтобы открыть новую книгу и вставить результаты анализа в ячейку A1 на первом листе в этой книге.
Пп. 6-8. Лучше всего выводить результаты регрессионного анализа на отдельный лист (выбрать п.7).
9. Остатки (Residuals)
Установите флажок, чтобы включить остатки в выходной диапазон.
10. Стандартизированные остатки (Standardized Residuals)
Установите флажок, чтобы включить стандартизированные остатки в выходной диапазон.
Пп. 9-10. Флажки в Остатки и Стандартизованные остатки имеет смысл установить на самом последнем этапе пошагового регрессионного анализа, когда все коэффициенты регрессионной модели значимы.
11. График остатков
Установите флажок, чтобы построить диаграмму остатков для каждой независимой переменной.
12. График подбора
Установите флажок, чтобы построить диаграммы наблюдаемых и предсказанных значений для каждой независимой переменной.
13. График нормальной вероятности
Установите флажок, чтобы построить диаграмму нормальной вероятности.
Эти графики (пп.11,12,13) в рамках данного исследования строить не нужно.
Итак, приступаем к анализу.
I ЭТАП РЕГРЕССИОННОГО АНАЛИЗА.
В модель включены все факторные признаки (X1, X2, X3 , X4).
Результаты регрессионного анализа выдаются в следующем виде (в скобках указаны принятые у нас обозначения):
|
ВЫВОД ИТОГОВ |
|
|
|
|
|
| |||||||
|
|
|
|
|
|
|
| |||||||
|
Регрессионная статистика |
|
|
|
|
| ||||||||
|
Множественный R |
0,75322 |
|
|
|
| ||||||||
|
R-квадрат |
0,56735 |
|
|
|
| ||||||||
|
Нормированный R-квадрат |
0,49812 |
|
|
|
| ||||||||
|
Стандартная ошибка |
4,09622 |
|
|
|
| ||||||||
|
Наблюдения |
30 |
|
|
|
| ||||||||
|
|
|
|
|
|
|
| |||||||
|
Дисперсионный анализ |
|
|
|
|
| ||||||||
|
|
df (число степеней свободы ν) |
SS (сумма квадратов отклонений Q) |
MS (средний квадрат MS=SS/ν) |
F (Fнабл= MSR/MSост) |
Значимость F | ||||||||
|
Регрессия |
4 |
550,065 (QR) |
137,5163 |
8,195725 |
0,000229 |
| |||||||
|
Остаток |
25 |
419,476 (Qост) |
16,77902 |
|
|
| |||||||
|
Итого |
29 |
969,541 (Qобщ) |
|
|
|
| |||||||
|
|
|
|
|
|
|
| |||||||
|
|
Коэффи-циенты (bi) |
Стандартная ошибка (Ŝbi) |
t-ста-тистика (tнабл) |
P-Значение
|
Нижние 95% (βimin) |
Верхние 95% (βimax) |
Нижние 98% (βimin) |
Верхние 98% (βimax) | |||||
|
Y-пересечение |
17,28356 |
6,62546 |
2,6087 |
0,0151 |
3,6382 |
30,9290 |
0,8186 |
33,7485 | |||||
|
Переменная X1 |
-0,50132 |
0,14108 |
-3,5534 |
0,0015 |
-0,7919 |
-0,2108 |
-0,8519 |
-0,1507 | |||||
|
Переменная X2 |
6,22430 |
2,20638 |
2,8210 |
0,0092 |
1,6802 |
10,7684 |
0,7412 |
11,7074 | |||||
|
Переменная X3 |
-0,21218 |
0,47694 |
-0,4449 |
0,6602 |
-1,1945 |
0,7701 |
-1,3974 |
0,9731 | |||||
|
Переменная X4 |
-0,05118 |
0,02013 |
-2,5423 |
0,0176 |
-0,0926 |
-0,0097 |
-0,1012 |
-0,0012 | |||||
В регрессионной статистике указываются множественный коэффициент корреляции (Множественный R) и детерминации (R-квадрат) между Y и массивом факторных признаков (что совпадает с полученными ранее значениями в корреляционном анализе).
Средняя часть таблицы (Дисперсионный анализ) необходима для проверки значимости уравнения регрессии.
Нижняя часть таблицы – точечные оценки bi генеральных коэффициентов регрессии βi, проверка их значимости и интервальная оценка.
Оценка вектора коэффициентов b (столбец Коэффициенты):

Тогда оценка уравнения регрессии имеет вид:
![]()
Необходимо проверить значимость уравнения регрессии и полученных коэффициентов регрессии.
Проверим на уровне α=0,05 значимость уравнения регрессии, т.е. гипотезу H0: β1=β2=β3=…=βk=0. Для этого рассчитывается наблюдаемое значение F-статистики:

Excel выдаёт это в результатах дисперсионного анализа:

В столбце F указывается значение Fнабл.
По таблицам F-распределения (см. Приложение, таб. П.2.3) или с помощью встроенной статистической функции FРАСПОБР для уровня значимости α=0,05 и числа степеней свободы числителя ν1=k=4 и знаменателя ν2=n-k-1=25 находим критическое значение F-статистики, равное
Fкр = 2,75871
Так как наблюдаемое значение F-статистики превосходит ее критическое значение 8,1957 > 2,7587, то гипотеза о равенстве вектора коэффициентов отвергается с вероятностью ошибки, равной 0,05. Следовательно, хотя бы один элемент вектора β=(β1,β2,β3,β4)T значимо отличается от нуля.
Проверим значимость
отдельных коэффициентов уравнения
регрессии, т.е. гипотезу
![]() .
.
Проверку значимости
регрессионных коэффициентов проводят
на основе t-статистики
![]() для уровня значимости
для уровня значимости![]() .
.
Наблюдаемые значения t-статистик указаны в таблице результатов в столбце t-статистика.
-
Коэффициенты
(bi)
t-статистика
(tнабл)
Y-пересечение
b0 = 17,28356
2,6087
Переменная X1
b1 = -0,50132
-3,5534
Переменная X2
b2 = 6,22430
2,8210
Переменная X3
b3 = -0,21218
-0,4449
Переменная X4
b4 = -0,05118
-2,5423
При отсутствии пакета анализа данных, t-статистики можно получить, исходя из результатов оценки коэффициентов модели и их стандартных ошибок:
![]()
![]()
![]()
![]()
![]()
Их необходимо сравнить с критическим значением tкр, найденным для уровня значимости α=0,05 и числа степеней свободы ν=n – k - 1.
Для этого используем встроенную статистическую функцию Excel СТЬЮДРАСПОБР, введя в предложенное меню вероятность α=0,05 и число степеней свободы ν= n–k-1=30-4-1=25. (Можно найти значения tкр по таблицам математической статистики (см. Приложение, таб. П.2.2)).
Получаем tкр=2,05953854.
Для
![]()
![]() наблюдаемое значениеt-статистики
больше критического по модулю
наблюдаемое значениеt-статистики
больше критического по модулю
![]()
![]()
Следовательно, гипотеза о равенстве нулю этих коэффициентов отвергается с вероятностью ошибки, равной 0,05, т.е. соответствующие коэффициенты значимы.
Для
![]() наблюдаемое значениеt-статистики
меньше критического значения по модулю
наблюдаемое значениеt-статистики
меньше критического значения по модулю
![]() ,
следовательно, гипотезаH0
не отвергается, т.е.
,
следовательно, гипотезаH0
не отвергается, т.е.
![]() - незначим.
- незначим.
Значимость регрессионных коэффициентов проверяют и следующие столбцы результирующей таблицы:
Столбец p-значение показывает значимость параметров модели граничным 5%-ым уровнем, т.е. если p≤0,05, то соответствующий коэффициент считается значимым, если p>0,05, то незначимым.
И последние столбцы – нижние 95% и верхние 95% и нижние 98% и верхние 98% - это интервальные оценки регрессионных коэффициентов с заданными уровнями надёжности для γ=0,95 (выдаётся всегда) и γ=0,98 (выдаётся при установке соответствующей дополнительной надёжности).
Если нижние и верхние границы имеют одинаковый знак (ноль не входит в доверительный интервал), то соответствующий коэффициент регрессии считается значимым, в противном случае – незначимым..
Как видно из таблицы, для коэффициента β3 p-значение p=0,6602 >0,05 и доверительные интервалы включают ноль, т.е. по всем проверочным критериям этот коэффициент является незначимым.
Согласно алгоритму
пошагового регрессионного анализа с
исключением незначимых регрессоров,
на следующем этапе необходимо исключить
из рассмотрения переменную X3
(фондовооруженность труда), имеющую
незначимый коэффициент регрессии
![]() .
.
В случае, когда
при оценке регрессии выявлено несколько
незначимых коэффициентов, первым из
уравнения регрессии исключается
регрессор, для которого t-статистика
(![]() )
минимальна по модулю.
)
минимальна по модулю.