

Подготовка данных к анализу. Первичная обработка данных.
Пусть некоторые объекты или явления представляются множеством своих характеристик: X = (X1, X2, …, Xj, …Xm).
Матрицу наблюдений можно составить следующим образом:

В практических задачах приходится проводить статистическую обработку данных с целью исключения аномальных наблюдений, подбора однородных совокупностей, удаление дублирующих переменных и т.д.
Выявление и исключение резко выделяющихся наблюдений
Истинность некоторых индивидуальных наблюдений иногда вызывает сомнения, т.к. они резко выделяются на фоне основной массы наблюдений. Такие аномальные наблюдения могут появляться в следствии:
обычные колебания выборки обусловленные природой генеральной совокупности;
нарушение условий проведения наблюдений;
нарушение условий сбора статистических данных;
механические ошибки при регистрации данных и подготовки обработки на ЭВМ.
Единственно надежным способом исключения таких наблюдений является тщательное рассмотрение условий при которой они были получены. Если резко выделяющиеся наблюдения связаны с природой самого явления, то его нельзя исключать. Однако содержательный анализ не всегда доступен и в этом случае используется следующая логическая схема:
исходя из допущений о природе анализируемой совокупности задаём некоторую функцию которую называют мерой удалённости от основной массы;
этот индикатор является индикатором аномальности. Значение этой функции вычисляются для всех наблюдений и сравнивают их с некоторым пороговым (уставка, норма) значением 0;
Если < 0 , то наблюдение остается в совокупности;
Для всех наблюдений, для которых > 0 они либо исключаются из выборки, либо их значение подавляется с помощью весовых коэффициентов.
Если аномальные наблюдения выделены в группу для отдельного анализа, то все остальные подвергаются сглаживанию.
Для выделения аномальных наблюдений в нормально-распределённых данных применяют статистические критерии.
Рассмотрим каждый столбец матрицы наблюдений как одномерную выборку и представим элементы этого столбца в ранжированном виде, т. е. отсортируем столбец, например, по возрастанию. Тогда числа
х(1)j
![]() x(2)j
…
x(n)j
, в этом выражении (1), (2), …,(n)
– некоторая подстановка последовательности
индексов i=1, …,n.
x(2)j
…
x(n)j
, в этом выражении (1), (2), …,(n)
– некоторая подстановка последовательности
индексов i=1, …,n.
Составляем следующую комбинацию:
![]() ,
,
, где
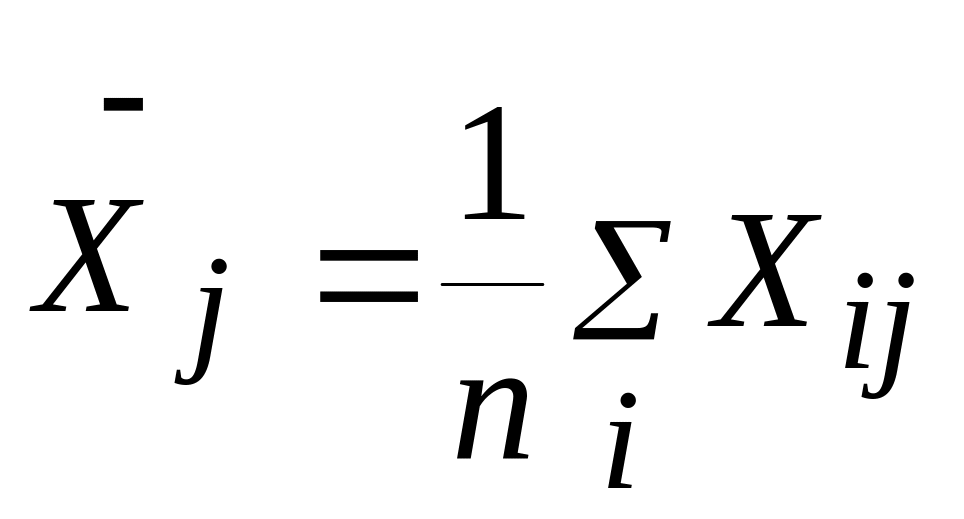 ,
,
![]()
Статистика Vj
описывается распределением Стьюдента.
Задавшись величиной
![]() -
уровень значимости по двум числам
,
n из таблиц находим величину
Vтабл. Проверяется
неравенство Vj<Vтабл.
Если неравенство выполняется, то значение
x(n)j
остается в выборке. Эта процедура
проводится до тех пор, пока не будут
отброшены все резковыделяющиеся
наблюдения.
-
уровень значимости по двум числам
,
n из таблиц находим величину
Vтабл. Проверяется
неравенство Vj<Vтабл.
Если неравенство выполняется, то значение
x(n)j
остается в выборке. Эта процедура
проводится до тех пор, пока не будут
отброшены все резковыделяющиеся
наблюдения.
Методика полностью справедлива, если числа выборки распределены по нормальному закону. В противном случае этой методикой можно пользоваться, если числа удается каким-либо преобразованием привести к форме нормального распределения (хотя бы приближенно).
Сглаживание кривых
Сглаживание заключается в уточнении ординаты каждой точки с учётом положения нескольких ближайших точек. Часто применяется метод линейного сглаживания по пяти точкам. В этом методе используют 5 формул по две для точек крайних справа и слева и одну для всех внутренних точек.
yS0 = 0,2(3y0 + 2y1 + y2 – y4) - крайняя левая точка
yS1 = 0,1(4y0 + 3y1 + 2y2 + y3) - следующая точка
ySn-1 = 0,1(yn-3 + 2yn-2 + 3yn-1 + 4yn) - предпоследняя точка
ySn= 0,2(3yn + 2yn-1 + yn-2 – yn-4) - крайняя правая
Для всех внутренних точек, т.е. таких, что i = 2, …, n-2 применяется:
ySi= 0,2(yi-2 + yi-1 + yi + yi+1 + yi+2)
Наиболее часто используется так называемое экспоненциальное сглаживание. При таком сглаживании предполагается что
xi = b +
xi – измерение; b – детерминированное число; - случайная ошибка.
Константа b относительно стабильна, но может иногда меняться со временем.
Одним из интуитивных способов выделения b, является использование скользящего среднего, в котором последним наблюдениям приписываются большие веса, чем предпоследним. В свою очередь предпоследним приписываются большие веса, чем предыдущим и т.д. Точная формула простого экспоненциального сглаживания имеет следующий вид:
Si = xi + (1-)Si-1
Si – сглаженное значение
xi – текущее значение
Si-1 – предыдущий сглаженный ряд
Когда эта формула применяется рекурсивно, то каждое новое сглаженное значение (которое одновременно является прогнозом) вычисляется как взвешенное среднее текущего наблюдения и сглаженного ряда. Коэффициент сглаживания выбирается из промежутка [0, 1] по принципу:
(Si – xi)2 min
Ряд функций MathCAD предназначены для выполнения сглаживания. В названии этих функций имеется слово Smooth (гладкий).
1: medsmooth (VY, n) − это функция для m -мерного VY возвращает m-мерный вектор сглаженных значений по методу скользящей медианы. n – это ширина окна сглаживания, должно быть нечётным числом n < m.
2 :
ksmooth
(VX,
VY,
b).
VX
и VY
n-мерные
вектора. b
– полоса пропускания. Возвращается
n-мерный
вектор сглаженных VY,
вычисленных на основе распределения
Гаусса.
:
ksmooth
(VX,
VY,
b).
VX
и VY
n-мерные
вектора. b
– полоса пропускания. Возвращается
n-мерный
вектор сглаженных VY,
вычисленных на основе распределения
Гаусса.
3: supSmooth (VX, VY) – эта функция осуществляет линейное сглаживание по принципу k ближайших соседей ( величина k выбирается адаптивно). VX в этих функциях должны быть отсортированы по возрастанию.