

Кодирование Шеннона-Фано
Необходимо перечислить все сообщения в порядке убывания их вероятностей, затем этот список разбивается на приблизительно равновероятные разделы (два раздела для двоичного кода, три – для троичного, и т.д.). Первой часть списка назначается – 0, второй – 1, и т.д. Процесс продолжается до тех пор, пока не останется непронумерованных разделов.
Кодирование Хаффмана
Процесс кодирования Хаффмана выполняется следующим образом. Символы сообщения, которые нужно закодировать, перечисляются в порядке убывания вероятности (Т.е. символы с самой высокой вероятностью должны быть в верхней части этого списка). Если используется двоичный кодовый алфавит, то две ветви с самыми низкими вероятностями объединяются (со сложением их вероятностей), но перед этим одна из них маркируется как 0, а другая – как 1. Затем эти ветви вновь упорядочиваются по вероятности и процесс повторяется. Процесс продолжается до тех пор, пока не останется только одна ветвь. Затем считываются кодовые слова, причем чтение выполняется в обратном порядке от последнего элемента с добавлением в кодовое слово встречающихся по пути нулей и единиц.
Например, возьмем систему со следующими вероятностями: A 0,25; B 0,3; C 0,35; D 0,1. Ранжируем их. Самые маленькие вероятности у элементов А и D (0,25 и 0,1). Они объединяются в одну AD ветвь, ветвь А маркируется как 0, а ветвь D как 1, и выполняется новое упорядочивание по убыванию вероятности:
С – 0,35; AD – 0,35; B – 0,3.
Относительно упорядочивания компонента AD имеется свобода выбора: располагать его можно либо выше, либо ниже компонента C. В каждом случае будут получены разные, но эквивалентные коды.
Затем объединяются компоненты AD и B, причем AD помечается как 0, а B – как 1. Это приводит к следующему списку:
ADB – 0,65; C – 0,35.
в котором компонента ADB маркируется как 0, а С – как 1, что дает только одну ветвь, на этом процесс заканчивается.
Извлечение кодовых слов выполняется следующим образом (начиная с последнего столбца, в обратном порядке):
А: 0 – от ветви ADB (последний столбец), 0 – от ветви AD (средний столбец) и 0 – от ветви А (первый столбец), что дает первое кодовое слово: 000;
В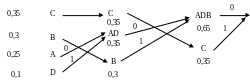 :
0 – от ветви ADB,
1 – от ветви В (средний столбец), что дает
второе кодовое слово: 01 и т.д.
:
0 – от ветви ADB,
1 – от ветви В (средний столбец), что дает
второе кодовое слово: 01 и т.д.
Рис. 1 Пример построения кода Хаффмана
Чтобы использовать кодирование Хаффмана для кодовых алфавитов, состоящих из большего количества символов, нужно выполнить небольшую модификацию этапа группировки: вместо объединения двух самых маловероятных компонентов перед переходом к следующему этапу нужно объединять n таких компонентов, где n – число символов кодового алфавита. Эти символы следует использовать для нумерации последних ветвей дерева на различных этапах процесса построения кодов Хаффмана. Следовательно, на каждом этапе этого процесса удаляются (n-1) входов (элементов) списка. Поскольку, в конце концов, остается элемент помеченный как 1, то в предыдущем списке должно быть 1+(n-1) элементов, а в его предшественнике – 1+2(n-1) элементов и т.д.
Задания
Информационный источник без памяти генерирует 8 различных символов с вероятностями 1/2, 1/4, 1/8, 1/16, 1/32, 1/64, 1/128 и 1/128. Эти символы кодируются как 000, 001, 010, 011, 100, 101, 110 и 111 соответственно:
Определить, чему равна энтропия на символ данного источника;
Какова эффективность данного кода;
Построить код, используя алгоритм Шеннона-Фанно, и вычислить его эффективность;
Построить код, используя алгоритм Хаффмана, и вычислить его эффективность;
Постройте код для источника без памяти с шестью символами, используя трехзначный кодовый алфавит {0, 1, 2}. Пусть выборка вывода такого источника выглядит так: ACAAABEBCDAEABDCAEFAABDF. Определите эффективность этого кода. Сравните ее с эффективностью кода {A:00, B:01, C:02, D:10, E:11, F:12}.
Удаленные датчики могут иметь два состояния – SET (Установлен) и CLEAR (Сброшен). В среднем 99% датчиков находятся в состоянии CLEAR:
Используйте одноразрядный код: 0 – CLEAR, 1 – SET. Определите его эффективность.
Для повышения эффективности постоянно используются два смежных одноразрядных сообщения. Определите подходящий двоичный код для этой ситуации и вычислите его эффективность.
Повторите процедуру предыдущего пункта для групп, состоящих из 3 символов.
Контрольные вопросы
Что такое энтропия?
Дайте определение источника информации?
Какие типы сжатия используются для кодирования источника?
Как выполняется процесс кодирования Хаффмана?
Лабораторная работа № 2
Системы шифрования с частными ключами
Цель работы
Научиться шифровать данные, используя системы с частными ключами.
Краткие теоретические сведения
Системы шифрования с частными ключами также называются симметричными системами, потому что обе связывающиеся стороны имеют тот же самый ключ, а расшифровка – это просто обратное кодирование с помощью ключа. Преимущества: эти системы для данного уровня защиты обладают достаточно невысокой сложностью.
Перестановочные шифры
В перестановочных шифрах позиции символов сообщения изменяются, но значение сообщения остается неизменным. Простой шифр – это специальная таблица, куда сообщение вписывается одним способом, а затем считывается – другим. Например, сообщение вписывается в строки сетки, а считывается по столбцам. Все, что нужно сделать прослушивающему – это определить глубину сетки.
T |
H |
I |
S |
I |
S |
A |
M |
E |
S |
S |
A |
G |
E |
T |
O |
S |
E |
N |
D |
|
Рис. 2 Простой перестановочный шифр
Усовершенствование этой методики состоит в том, чтобы читать столбцы сетки в более сложном порядке, чем просто слева направо. Для указания порядка считывания столбцов можно использовать ключевое слово, алфавитное упорядочивание букв которого и определяет порядок чтения столбцов. Например, если бы ключевым словом было слово cipher, то мы вписывали бы шифруемое сообщение в 6 столбцов, а затем считывали бы столбцы в следующем порядке 1(c), 5(e), 4(h), 2(i), 3(p), 6(r). Однако такая система остается все еще очень восприимчивой к нападению по методу проб и ошибок.