

5. Операции редукции (обработки данных)
Функция MPI_Reduce объединяет элементы входного буфера каждого процесса в группе, используя операцию op, и возвращает объединенное значение в выходной буфер процесса с номером root.
MPI_Reduce(sendbuf, recvbuf, count, datatype, op, root, comm)
IN sendbuf адрес посылающего буфера
OUT recvbuf адрес принимающего буфера (исп-ся только корневым процессом)
IN count количество элементов в посылающем буфере (целое)
IN datatype тип данных элементов посылающего буфера
IN op операция редукции
IN root номер главного процесса (целое)
IN comm коммуникатор
Базовые (предопределенные) типы операций MPI

Входной и выходной буфер на всех процессах одинаковой длины и одного типа данных. Каждый процесс может содержать один элемент или последовательность (массив) элементов, в этом случае операция выполняется над всеми элементами этой последовательности.
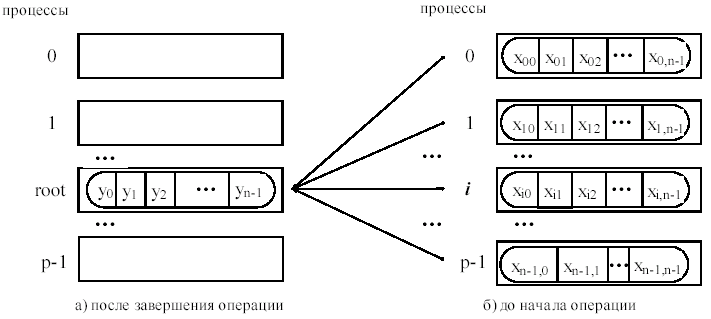
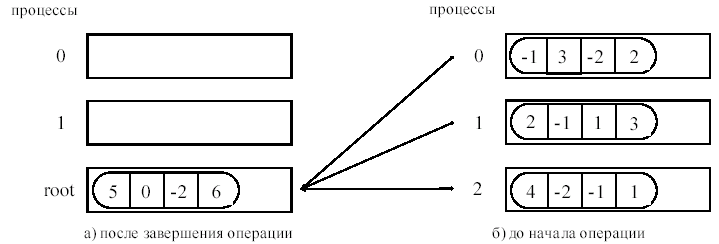
Пример выполнения операции суммирования элементов массива для 3-ех процессов (в каждом массиве по 4 элемента, сообщения собираются на процессе с рангом 2)
Операции MPI_MINLOC и MPI_MAXLOC
Операции MPI_MINLOC/MPI_MAXLOC используются для определения глобального минимума/максимума и соответствующих им индексов. Каждый процесс предоставляет значение и свой номер в группе. Операция редукции с op = MPI_MAXLOC возвратит значение максимума и номер первого процесса с этим значением. Аналогично, MPI_MINLOC возвратит значение минимума и номер процесса, если процессов с таким значением несколько будет возвращен номер первого.
Чтобы использовать MPI_MINLOC и MPI_MAXLOC в операции редукции, нужно определить тип данных datatype, который представляет пару (значение и индекс). MPI предоставляет девять таких предопределенных типов данных – 3 фортрана и 6 Си:
MPI_FLOAT_INT переменные типа float и int
MPI_DOUBLE_INT переменные типа double и int
MPI_LONG_INT переменные типа long и int
MPI_2INT пара переменных типа int
MPI_SHORT_INT переменные типа short и int
MPI_LONG_DOUBLE_INT переменные типа long double и int
Пример. Функция MPI_Reduce с операцией MPI_MAXLOC
#include <stdio.h>
#include <mpi.h>
struct{
double value; int proc;
}local_max,global_max;
void main( int argc, char *argv[] ) {
int i, rank, size;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
double array[10];
double max_value;
for(i=0; i<10; i++) array[i]=(double)rand()/RAND_MAX + 0.1*rank;
max_value=array[0];
for(i=0; i<10; i++){
if(array[i]>max_value)
max_value=array[i];
}
local_max.value=max_value;
local_max.proc=rank;
MPI_Reduce(&local_max,&global_max,4,MPI_DOUBLE_INT,MPI_MAXLOC,size-1, MPI_COMM_WORLD );
if (rank == size-1)
printf("global maximum=%f number process=%d\n",global_max.value, global_max.proc);
MPI_Finalize();
}
Пример. Функция MPI_Reduce с операцией MPI_SUM
#include <stdio.h>
#include <mpi.h>
void main( int argc, char *argv[] ) {
int a[]={1,4,7,2,1,9,6,8,3,5}, summa[10];
int i, rank;
MPI_Init( &argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Reduce(&a[0],&summa[0],10,MPI_INT,MPI_SUM,1,MPI_COMM_WORLD );
if (rank ==1) { //результат помещается на root процесс, root=1
for (i=0; i<10; i++) {
printf("%d\n", summa[i]);
}
}
MPI_Finalize();
}
Лекция 5
Конструкторы типов данных. Функции упаковки и распаковки данных.
Поддерживаемые MPI языки программирования, в частности Си имеют средства создания собственных “нестандартных” типов данных, например, с помощью структур. Но передать за одну отправку переменные такого типа мы не можем. Почему? Проблема заключается в том, что в функциях передачи и приемы в качестве параметра, который определяет длину сообщения, используется количество передаваемых данных в единицах данных типа. Длина сообщения вычисляется как произведение указанного типа данных на число элементов.
Другая проблема заключается в том, что мы не можем передать за одну отправку, используя стандартные типы данных MPI переменные разных типов, например int и double или более сложные конструкции, например структуры с различными по типу и размеру полями. Выполнить такую передачу можно несколькими способами:
преобразовать данные меньшего типа к большему, в данном случае int к double. Естественно, что при выполнении такой передачи длина сообщения будет больше, поскольку каждый 4-ух байтовый int будет преобразован в 8-ми байтовый double. Поэтому, чем больше данных типа int и меньше данных типа double, тем больше увеличится объем передаваемого сообщения. Это неэффективно.
использовать операцию упаковки и распаковки. Это лучше предыдущего способа, но если необходимо часто передавать нестандартные данные, то многократный вызов операций MPI_Pack/MPI_Unpack также приводят к дополнительным накладным расходам, поскольку выполняют большую работу по переписыванию данных из одной области памяти в другую. Что при больших объемах данных занимает достаточно много времени.
Создать новый тип данных и использовать его на протяжении всей работы программы.
Операции упаковки и распаковки данных
Тип MPI_PACKED используется для передачи данных, которые были явно упакованы, или для получения данных, которые будут явно распакованы.
MPI_Pack (inbuf, incount, datatype, outbuf, outsize, position, comm)
IN inbuf начало входного буфера (альтернатива)
IN incount число единиц входных данных (целое)
IN datatype тип данных каждой входной единицы (дескриптор)
OUT outbuf начало выходного буфера (альтернатива)
IN outsize размер выходного буфера в байтах (целое)
INOUT position текущая позиция в буфере в байтах (целое)
IN comm коммуникатор для упакованного сообщения
MPI_Pack пакует сообщение из буфера передачи, который определяется аргументами inbuf, incount, datatype в выходной буфер. Выходной буфер это непрерывная область памяти, содержащая outsize байтов, начиная с адреса outbuf (длина подсчитывается в байтах, а не элементах).
Входное значение position - это первая ячейка в выходном буфере, которая используется для упаковки. Далее рosition увеличивается на размер упакованного сообщения (в байтах), таким образом выходное значение рosition - это первая ячейка в выходном буфере, следующая за упакованным сообщением.
MPI_Unpack (inbuf, insize, position, outbuf, outcount, datatype, comm)
IN inbuf начало входного буфера (альтернатива)
IN insize размер входного буфера в байтах (целое)
INOUT position текущая позиция в байтах (целое)
OUT outbuf начало выходного буфера (альтернатива)
IN outcount число единиц для распаковки (целое)
IN datatype тип данных каждой выходной единицы данных (дескриптор)
IN comm коммуникатор для упакованных сообщений (дескриптор)
MPI_Unpack распаковывает сообщение в приемный буфер, который определяется аргументами outbuf, outcount, datatype из буфера, определенного аргументами inbuf и insize. Входной буфер - это непрерывная область памяти, содержащая insize байтов, начиная с адреса inbuf.
Входное значение position есть первая ячейка во входном буфере, занятом упакованным сообщением. Далее значение рosition увеличивается на размер упакованного сообщения, таким образом выходное значение рosition - это первая ячейка во входном буфере после сообщением, которое было упаковано.
В основном функции используются в том случае, если необходимо сформировать один буфер передачи из нескольких. В этом случае, выполняется несколько последовательно связанных обращений к MPI_Pack, где первый вызов определяет position = 0, и каждый последующий вызов вводит значение position, которое было выходом для предыдущего вызова, и то же самое значение для outbuf, outcount. Этот упакованный объект содержит эквивалентное сообщение, которое выполнялось бы по одной передаче отдельно с каждым буфером передачи.
Упакованный объект передается и принимается с типом MPI_PACKED любой операцией передачи сообщений (двухточечной или коллективной) с последующей распаковкой.
Если упакованный объект был последовательно сформирован из нескольких буферов, т.е. выполнено несколько операций MPI_Pack, то он может быть распакован в несколько последовательных сообщений последовательностью вызовов функции MPI_Unpack, где первый вызов определяет position = 0, а каждый последующий вызов вводит значение position, которое было выходом предыдущего обращения.
Очевидно, что количество упаковок должно совпадать с количеством распаковок.
Следующий вызов позволяет определить, объем памяти, который необходимо выделить для упаковки сообщений.
MPI_Pack_size(incount, datatype, comm, size)
IN incount аргумент count для упакованного вызова (целое)
IN datatype аргумент datatype для упакованного вызова (дескриптор)
IN comm аргумент communicator для упакованного вызова (дескриптор)
OUT size верхняя граница упакованного сообщения в байтах (целое)
Функция MPI_Pack_size возвращает в size верхнюю границу значения position, которая создана обращением к функции упаковки MPI_Pack.
Пример. Функция MPI_Pack/MPI_Unpack
#include <stdio.h>
#include <mpi.h>
void main( int argc, char *argv[] ) {
int ii, iii=2;
double jj, jjj=5.3;
int position, count;
char buff_pack[100], buff_unpack[100];
MPI_Status stat;
if (rank == 0) {
position = 0;
MPI_Pack(&iii,1,MPI_INT,buff_pack,100, &position, MPI_COMM_WORLD);
MPI_Pack(&jjj,1,MPI_DOUBLE,buff_pack,100,&position, MPI_COMM_WORLD);
MPI_Send(&buff_pack[0], position, MPI_PACKED, 1, 0, MPI_COMM_WORLD);
}
else {
MPI_Probe(0, 0, MPI_COMM_WORLD, &stat);
MPI_Get_count(&stat, MPI_PACKED, &count);
MPI_Recv( &buff_unpack[0], count, MPI_PACKED, 0, 0, MPI_COMM_WORLD, &stat);
position = 0;
MPI_Unpack(&buff_unpack[0],count,&position, &ii,1, MPI_INT, MPI_COMM_WORLD);
MPI_Unpack(&buff_unpack[0],count,&position, &jj,1, MPI_DOUBLE,
MPI_COMM_WORLD);
printf("ii=%d jj=%f\n",ii,jj);
}
MPI_Finalize();
}
MPI содержит механизм, который позволяет передавать данные различной структуры и размера, выполняя передачу данные непосредственно из памяти, т.е. без дополнительного копирования. Аналогично тому, как создаются производные типы данных в Си, производные типы данных MPI, конструируются из базовых типов с использованием специальных конструкторов.
В общем случае описываемые значения не обязательно непрерывно располагаются в памяти. Каждый тип данных MPI имеет карту типа (type map), состоящую из последовательности пар значений, первое задает базовых тип данных, второе - смещение адреса в памяти относительно начала базового адреса, т.е.
![]()
Часть карты типа с указанием только базовых типов называется сигнатурой типа:
![]()
Сигнатура типа описывает, какие базовые типы данных образуют производный тип данных MPI. Смещения карты типа определяют, где находятся значения данных.
Например, пусть в сообщение должны входить значения переменных:
double a; /* адрес 24 */
double b; /* адрес 40 */
int n; /* адрес 48 */
Тогда производный тип для описания таких данных должен иметь карту типа следующего вида: { (MPI_DOUBLE,0), (MPI_DOUBLE,16), (MPI_INT,24) }
Для характеристики типа данных в MPI используется следующий ряд понятий:
- нижняя
граница типа
![]()
- верхняя
граница типа
![]()
- протяженность типа extent(TypeMap) = ub(TypeMap)-lb(TypeMap).
Нижняя граница – определяет смещение для первого байта значений типа данных.
Верхняя граница – определяет смещение для байта, расположенного за последним элементом типа данных. При этом величина смещения для верхней границы может быть округлена вверх с учетом требований выравнивания адресов.
Понятие протяженности отличается от понятия размер типа. Протяженность – это размер памяти в байтах, который нужно отводить для одного элемента производного типа. Размер типа данных - это число байтов, которые занимают в памяти данные (разность между адресами последнего и первого байтов данных). Отсюда - различие в значениях протяженности и размера зависит от величины округления при выравнивании адресов. Так, в рассматриваемом примере размер типа равен 28, а протяженность – 32 (предполагается, что выравнивание выставлено на 8 байт).
Итак, создание общего типа данных определяется:
последовательностью базовых типов данных,
последовательностью смещений байтов.