

10. Функция omp_get_nested
Возвращает ненулевое значение, если вложенный параллелизм разрешен, и нулевое значение, если вложенный параллелизм запрещен.
Int omp_get_nested(void)
Если реализация OpenMP не поддерживает вложенный параллелизм, функция всегда возвращает нулевое значение.
Лекция 11
Достоинства и недостатки организации параллельных вычислений на рбщей и распределенной памяти. Понятие модели распределенного глобального адресного пространства (PGAS). Основные понятия.
На эффективность параллельных приложений влияют три основных фактора:
архитектура вычислительного комплекса (производительность ЦП, топология сети, быстродей-ствие коммуникаций и т.д.
средства разработки парал-лельных программ (компиля-торы, библиотеки функций, программные средства иссле-дования эффективности и т.д.
Особенности алгоритма задачи, возможность его распараллеливания, квалификация разработчиков

Достоинством организации параллельных вычислений на ВС с общей памятью, является использование без обменных средств распараллеливания, что значительно увеличивает производительность параллельного приложения при правильном обращении к общей памяти.
Недостатком организации параллельных вычислений на ВС с общей памятью, является доступ разных процессоров к общим данным и обеспечение, в этой связи, однозначности значений данных (cache coherence problem), т.е. необходимость выполнения явной синхронизации для обеспечения безопасного доступа к данным.
Достоинства организации параллельных вычислений на распределенной памяти:
1. Использование распределенной памяти упрощает задачу создания мультипроцессорных вычислительных систем.
2. Каждый процесс обладает собственными ресурсами и выполняется в собственном адресном пространстве, таким образом, данные, находящиеся на каждом процессе защищены от неконтролируемого доступа.
3. Универсальность, т.к. алгоритмы с передачей сообщений могут выполняться на большинстве сегодняшних суперкомпьютеров.
4. Легкость отладки. Отладка параллельных программ все еще остается сложной задачей. Однако процесс отладки происходит легче в программах с передачей сообщений. Это связано с тем, что самая распространенная причина ошибок заключается в неконтролируемой перезаписи данных в памяти. Модель с передачей сообщений, явно управляет обращением к памяти, и, тем самым, облегчает локализацию ошибочного чтения или записи в память.
Недостатки организации параллельных вычислений на распределенной памяти:
1. Каждый процессор вычислительной системы может использовать только свою локальную память, поэтому для доступа к данным, располагаемым на других процессорах, необходимо явно выполнять операции передачи сообщений (message passing operations).
2. Проблема эффективного использования распределенной памяти приводят к существенному повышению сложности параллельных вычислений.
Современные вычислительные системы представляют собой распределенные SMP узлы. При такой архитектуре можно использовать два варианта выполнения параллельных программ:
1. на каждом вычислительном SMP узле порождается отдельный процесс. Процессы внутри узла обмениваются сообщениями через разделяемую память.
2. каждый вычислительный SMP узел захватывается монопольно одним процессом, внутри которого выполняется распараллеливание в модели "общей памяти", например с помощью директив OpenMP.
Модель распределенного глобального адресного пространства (PGAS)
Эффективной альтернативой широко известным моделям параллельного программирования способна стать модель распределенного глобального адресного пространства (PGAS – partitioned global address space). Одна из моделей PGAS реализованна в языке параллельного программирования UPC (Unified Parallel C), который был разработан Университетом Дж. Вашингтона, США в 2001 году. UPC относится к архитектурно-независимым языкам программирования. В основе UPC лежит функционально расширенный стандарт языка Си.
Функциональность и основные характеристики UPC
UPC представляет собой набор функций и операторов. Важной особенностью UPC, как языка параллельного программирования является возможность использования указателей при обращении к ячейкам общей памяти, что отличает UPC от потокового программирования OpenMP, являясь дополнительным средством оптимизации работы с данными.
На рисунке схематично отображен механизм обращения процессов(потоков) к адресному пространству задачи для трех технологий параллельного программирования: MPI, OpenMP и PGAS.
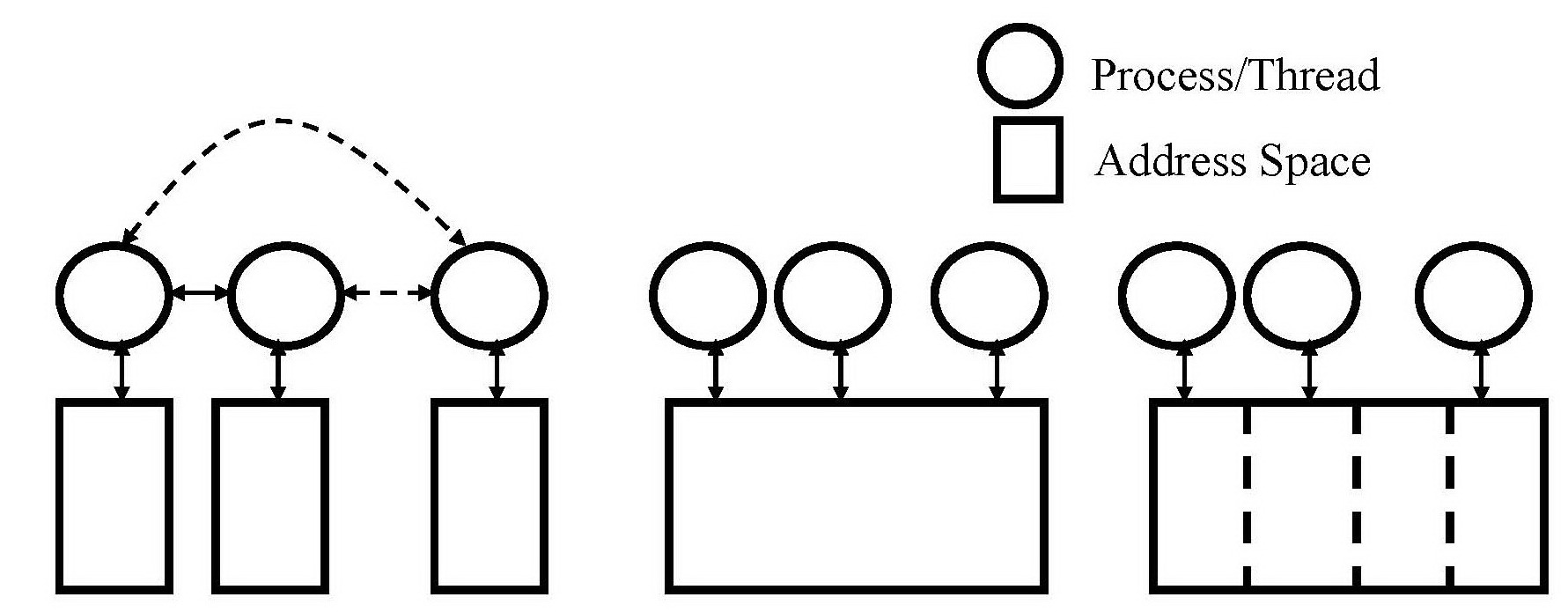
MPI OpenMP PGAS
Рисунок – механизм обращения процессов(потоков) к адресному пространству задачи
В отличие от MPI, в языке UPC не реализован механизм передачи данных между вычислительными процессами, поэтому UPC относится к безобменным средствам распараллеливания. При этом, аналогично MPI, UPC использует модель распределенного адресного пространства, суть которой заключается в том, что по умолчанию каждый поток хранит полную копию блока данных. Распараллеливание осуществляется процедурами и программными средствами языка UPC. Для обеспечения целостности, массивы данных объявляются общими (shared), однако каждый процесс(поток) может обращаться только к “своему” подблоку данных, ограниченному собственным адресным пространством, таким образом, параллельная обработка данных на каждом потоке выполняется в защищенном режиме и не требует обязательной синхронизации. Это существенно отличает UPC от потокового программирования на общей памяти с использованием OpenMP интерфейса.
Язык программирования UPC обладает следующими характеристиками и функциональными возможностями:
Модели памяти - локальные и разделяемые массивы и данные, методы распределения данных между процессами/потоками.
Указатели и специальные функции и операторы, связанные с потоками и разделяемой памятью: upc_threadof, upc_phaseof, upc_localsizeof, upc_blocksizeof и др.
Разделение работ итерационного типа между процессами/потоками с помощью конструкции upc_forall.
Динамическое выделение памяти.
Коллективные операции.
Методы синхронизации - барьеры (upc_barrier), запирания (upc_lock), ограничители (upc_fence), контроль непротиворечивости памяти (upc_strict и upc_relaxed).
Важное замечание: Разработка UPC приложений требует наличия в среде разработки UPC компилятора и реализации языка UPC. Для корректной работы компилятора расширение файлов приложений должно быть .c или .upc
Опции, содержащие mpi обращения необходимы для построения GASNet (Global Address Space Networking) механизма, который обеспечивает поддержку высокопроизводительного сетевого интерфейса в приложениях, использующих технологию PGAS. Технология PGAS является безобменной и не содержит функций передачи данных, однако, при выполнении UPC приложений на распределенной памяти работа с данными, находящимися на распределенных узлах требует использования механизма сетевого доступа. Поэтому, при использовании UPC на вычислительных системах смешанной архитектуры необходима поддержка механизма GASNet.