

Void main()
{
int i, n, x, y;
int num_threads=4;
int a[10], b[10];
for(i=0; i<10; i++)
{
a[i]=i+1;
b[i]=i+1;
printf("a[%d]=%d b[%d]=%d\n", i, a[i], i, b[i]);
}
printf("\n START REDUCTION \n");
x=0; y=5; // начальные значения
omp_set_num_threads(num_threads);
#pragma omp parallel for private(i) reduction(+: x, y)
for (i=0; i<10; i++)
{
x = x + a[i];
y = y + b[i];
n=omp_get_thread_num();
printf("n=%d \t x=%d \t y=%d\n", n, x, y);
}
printf("\n RESULT REDUCTION \n");
printf("x=%d \t y=%d\n", x, y);
}
X
= 0 + 6 +15 +15 + 19 = 55

Y
= 5 + 6 +15 +15 + 19 = 60
Директива threadprivate
Синтаксис директивы:
#pragma omp threadprivate(список)
Каждая копия переменной с атрибутом доступа threadprivate инициируется в программе один раз до первого обращения к копии этой переменной в каждой нити(т.е., как при последовательном исполнении программы). Если переменная определена как threadprivate, а значение переменной изменяется до первого обращения к копии переменной, то поведение переменной не определено.
Аналогично приватными переменными, нити не имеют связи с копиями переменной threadprivate других нитей. На протяжении последовательных областей программы и областей программы, выполняемых основной нитью, значение переменной будет равно значению переменной в основной нити.
После выполнения первой параллельной области, значения переменных типа threadprivate гарантировано сохраняются только в том случае, если нет механизма динамического изменения числа нитей, т.е. число нитей остается неизменным для всех параллельных областей.
Ограничения, накладываемые на использование директивы threadprivate:
1. Директива threadprivate должна встречаться вне любого определения или объявления и предшествовать всем обращениям (ссылкам) к любым переменным в списке.
2. Если переменная определена в директиве threadprivate в одном модуле трансляции, то она должна быть определена в директиве threadprivate в каждом модуле трансляции.
3. Переменные threadprivate не разрешены в операторах private, firstprivate, lastprivate, shared или reduction. На эти переменные не оказывает влияние оператор default.
4. Переменная threadprivate не может быть ссылкой.
Пример. Программа начинает последовательное выполнение, до начала параллельной области (#pragma omp parallel for). При входе в параллельную область порождается 4 нити, нити нумеруется автоматически, основная нить имеет номер 0. Каждая нить получает свою копию private переменной i.
#include<stdio.h>
#include<omp.h>
Void main()
{
int i, n;
int num_threads=4; // количество нитей
Int a[10], b[10], c[10]; // целочисленные массивы
for(i=0; i<10; i++) // инициализация элементов массивов
{
a[i]=i+1; b[i]=i+1;
printf("a[%d]=%d b[%d]=%d\n",i,a[i],i,b[i]);
}
printf("\n RESULT \n");
omp_set_num_threads(num_threads); // функция OpenMP, устанавливает
// количество нитей параллельной области
// вход в параллельную область, порождение установленного числа нитей,
#pragma omp parallel for private(i)
for(i=0; i<10; i++)
{
n=omp_get_thread_num(); // функция OpenMP, возвращает номер нити
c[i]=a[i]+b[i];
printf("n=%d c[%d]=%d\n",n,i,c[i]);
}
}
Лекция 9
Технология программирования OpenMP. Конструкции разделения работ
Конструкция разделения работ распределяет выполнение операторов среди группы нитей. Директивы разделения работ не порождают новые нити и не выполняют синхронизацию при входе в конструкцию разделения работ. OpenMP определяет три конструкции разделения работ:
1. оператор for
2. оператор sections
3. оператор single
1. Оператор for
Оператор for определяет итерационную конструкцию для некоторой области данных, в которой итерации соответствующего цикла будут выполняться параллельно. Итерации цикла for распределяются среди уже существующих нитей. Синтаксис конструкции for:
#pragma omp for [оператор [ оператор] ... ]
цикл for
цикл for должен иметь классическую форму языка Си:
for (выражение; логическая_операция; приращение)
{
Тело цикла
}
Оператор может иметь один из следующих типов:
private(список)
firstprivate(список)
lastprivate(список)
reduction(оператор: список)
ordered
schedule(вид [, длина_порции])
nowait
Операторы private, firstprivate, lastprivate и reduction рассматривались ранее.
Оператор ordered определяет блок, в котором итерации цикла выполняются в последовательном режиме. Не допускается использование в конструкции for оператора ordered более одного раза.
Оператор schedule определяет, как итерации цикла делятся между нитями группы. Правильность программы не должна зависеть от того, какая нить выполняет конкретную итерацию. Вид планирования может быть одним из следующих:
static |
schedule (static, длина_порции) - итерации делятся на порции длиной, равной длина_порции. Порции назначаются нитям в группе в порядке увеличения номеров нитей. Количество итераций делится на порции, которые приблизительно равны между собой, и каждой нити назначается одна порция. Значение порции статическое (не меняется) |
dynamic |
schedule (dynamic, длина_порции) - порция итераций длиной длина_порции назначается каждой нити. Когда нить завершит присвоенную ей порцию итераций, ей динамически назначается следующая порция, пока все порции не закончатся. Последняя порция может иметь меньшее число итераций. По умолчанию (длина_порции - не определена) значение равно 1. |
guided |
schedule(guided, длина_порции) - итерации назначаются нитям порциями с уменьшением размера порции. Когда нить завершает выполнение своей порции итераций, то назначается следующая порция до тех пор, пока их не останется. Если длина_порции=1, то длина_порции равна отношению числа итераций на число нитей. По умолчанию длина_порции =1. |
runtime |
schedule(runtime) - распределение и размер порции выбираются во время выполнения по значению переменной OMP_SCHEDULE(устанавливает способ планирования и длину порции, аналогично static, dynamic и guided, п. export OMP_SCHEDULE = guided,4 или export OMP_SCHEDULE = dynamic). Если перем-я среды не установлена, то планирование зависит от реализации OpenMP. Параметр, определяющий размер порции не указывается. |
Примеры использования циклов:
int a[10];
#pragma omp parallel private(i)
{
#pragma omp for schedule(static, 3)
for(i=0; i<10; i++)
a[i] = i+1;
}
индекс элемента |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
значение |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
номер нити |
0 |
1 |
0 |
1 |
||||||
int a[10];
#pragma omp parallel private(i)
{
#pragma omp for schedule(dynamic, 3)
for(i=0; i<10; i++)
a[i] = i+1;
}
индекс элемента |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
значение |
1 |
2 |
3 |
4 |
5 |
6 |
5 |
6 |
9 |
10 |
номер нити |
0 |
1 |
0 |
|||||||
int a[10];
#pragma omp parallel private(i)
{
#pragma omp for schedule(guided, 3)
for(i=0; i<10; i++)
a[i] = i+1;
}
индекс элемента |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
значение |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
6 |
9 |
10 |
номер нити |
0 |
1 |
0 |
|||||||
Пример: Цикл выполняет инициализацию элементов двумерного массива целых чисел. Количество потоков равно 2.
Внешний цикл по переменной i объявлен параллельным, внутренний цикл по переменной j будет выполняться последовательно каждой нитью. Выполняется блочно-циклическое распределение итераций внешнего цикла по две итерации в блоке.
int a[4][4];
#pragma omp parallel private(i)
{
#pragma omp for schedule(static, 2)
for(i=0; i<4; i++)
{
Нить
с номером 0
Нить
с номером 1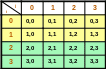
{
a[i] [j]= i+1;
}
}
}
Пример: внутренний цикл по переменной j объявлен параллельным, внешний цикл переменной i будет выполняться последовательно каждой нитью. Выполняется блочно-циклическое распределение итераций внутреннего цикла по две итерации в блоке.
int a[4][4];
for(i=0; i<4; i++)
{
Нить
с номером 0
Нить
с номером 1
{
#pragma omp for schedule(static,2 )
for(j=0; j<4; j++)
{
a[i][j]=i+1;
}
}
}
Оператор nowait – если не указан, то конструкция for завершится барьерной синхронизацией.
Ограничения к применению for. Цикл for
1. должен быть блоком (т.е. должны использоваться фигурные скобки),
2. не должен содержать оператор break,
3. содержать только один оператор schedule, ordered, nowait,
4. Значение длина_порции должно быть одно и тоже для всех нитей в группе.
Пример: Если внутри параллельной области несколько независимых циклов, можно использовать nowait, чтобы избежать барьерной синхронизации в конце директивы for. В параллельной области сначала будет выполнен первый цикл, итерации распределяются динамически и, не дожидаясь окончания первого цикла, первая свободная нить начнет выполнять второй цикл.
#pragma omp parallel
{
#pragma omp for nowait
for (i=0; i<n; i++)
b[i] = (a[i] + a[i-1]) / 2.0;
#pragma omp for nowait
for (i=0; i<m; i++)
y[i] = sqrt(z[i]);
}
Динамическая привязка директив должна придерживаться следующих правил:
Директивы for, sections, single, master и barrier динамически привязываются к внешней директиве parallel, если она, конечно, существует. Если нет параллельной области, выполняемой в данный момент, вышеуказанные директивы не имеют никакого действия.
Директива ordered динамически привязывается к внешней директиве for.
Директива atomic навязывает монопольный доступ в соответствии с директивой atomic во всех нитях, и не только в текущей группе.
Директива critical навязывает монопольный доступ в соответствии с директивой critical во всех нитях, и не только в текущей группе.
Директива никогда не может быть привязана к любой директиве вне ближайшей директивы parallel.
Динамическое вложение директив должно придерживается следующих правил:
Директива parallel динамически вне другой директивы parallel логически порождает новую группу, которая состоит только из текущей нити, если только вложенный параллелизм разрешен.
Директивы for, sections и single, которые привязаны к одной и тоже директиве parallel, не могут быть вложенными одна в другую.
Критическая секция не может быть вложена в другую критическую секцию с тем же именем.
Директива master запрещена в блоках директив for, sections и single.
Секция ordered запрещена в в блоке секции critical.
Директивы for, sections и single не допустимы в блоках critical, ordered и master.
Директива barrier не допустима в блоках for, ordered, sections, single, master, и critical.