

Lecture 2
Phonetics and Phonology.
Architecture of Classification.
The Traditional and Modern Designs of the Classificatory Model for Segmental Description.
Outline:
I. The difference between phonetics and phonology.
II. The traditional approach to the classification of segments.
III. J.Laver’s classification.
IY. The articulatory classification of the English consonants.
Y. The articulatory classification of English vowels.
I. The initial level of analysis of speech production is the acoustic level which is close to the physics of the original speech material itself. Two speech events are considered to be different at the acoustic level in either quality or timing. Two repetitions by a single speaker of vocal material that is linguistically and paralinguistically identical are not likely to be acoustically exactly the same. Two different speakers will always differ at the organic level even if they are producing linguistically and paralinguistically identical utterances. The level of analysis of such matter is the subject of phonetics which concerns voluntary learnable movements of the vocal apparatus. Phonetics is the study of the substance of the spoken language. One of the chief resources of phonetics is phonetic notation which is a set written symbols used for transcribing the phones of actual pronunciation.
Phonology is often said to be a study of the form of a spoken language. The function of phonology is to relate the phonetic events to grammatical units operating at the morphological, lexical, syntactic and semantic levels.
Phonology is a branch of linguistics which studies the sound system of language, it studies the sounds which have distinctive features. The sounds are organized into a system of contrasts which are analyzed in terms of phonemes. Some scholars regard phonology as structural and functional phonetics, because it studies the structure of the sounds and their function in the structure.
Let’s have a look at the relationship between phonetics and phonology.
If you only get to hear a word of a foreign language -- maybe only once, you have to cope with many sources of variation in pronunciation: individual, social and geographical, attitudinal and emotional. Any particular performance of a word simultaneously expresses the word, the identity of the speaker, the speaker's attitude and emotional state, the influence of the performance of adjacent words, and the structure of the message containing the word. Yet you have tease these factors apart so as to register the sound of the word in a way that will let you produce it yourself, and understand it as spoken by anyone else, in any style or state of mind or context of use. Thus, you (and those who listen to you speak) need to distinguish this one word accurately from tens of thousands of others.
The situation described above may be called this the pronunciation learning problem. If every word were an arbitrary pattern of sound, this problem would probably be impossible to solve. What makes it work? The answer is the Phonological Principle.
In human spoken languages, the sound of a word is not defined directly (in terms of mouth gestures and noises). Instead, it is mediated by encoding in terms of a phonological system:
1. A word's pronunciation is defined as a structured combination of a small set of elements
a) The available phonological elements and structures are the same for all words (though each word uses only some of them)
2. The phonological system is defined in terms of patterns of mouth gestures and noises -
a)This "grounding" of the system is called phonetic interpretation.
b) Phonetic interpretation is the same for all words.
How does the phonological principle help solve the pronunciation learning problem? Basically, by splitting it into two problems, each one easier to solve.
Phonological representations are digital, i.e. made up of discrete elements in discrete structural relations.
a) Copying can be exact: members of a speech community can share identical phonological representations
b) Within the performance of a given word on a particular occasion, the (small) amount of information relevant to the identity of the word is clearly defined.
2. Phonetic interpretation is general, i.e. independent of word identity
a) Every performance of every word by every member of the speech community helps teach phonetic interpretation, because it applies to the phonological system as a whole, rather than to any particular word.
To illustrate this, let's start with the (excessively simple) phonological system of a made-up language.
Outlandish has three vowels -- /a/, /i/, /u/ -- and every Outlandish syllable must contain one of these. There are seven consonants that can start syllables --- /p/, /t/, /k/, /b/, /d/, /g/, /s/ -- and a syllable may also lack an initial consonant. Syllables may optionally end with the consonant /n/.
Outlandish thus has 48 possible syllables: the syllable onset has 8 options (/p/, /t/, /k/, /b/, /d/, /g/, /s/ or nothing), the syllable nucleus has three options (/a/, /i/, /u/), and the syllable coda has two options (/n/ or nothing), and 8 x 3 x 2 = 48.
Outlandish words are made up of from 1 to 4 syllables. In consequence, there are 5,421,360 possible Outlandish words -- 48x48x48x48 + 48x48x48 + 48x48 + 48 = 5,421,360.
Thus the phonological elements of Outlandish, as we have described them, are /i/, /a/, /u/, /p/, /t/, /k/, /b/, /d/, /g/, /s/, /n/. The phonological structures of Outlandish include the notions of syllable, onset, nucleus, and coda.
Some examples of Outlandish words might /kanpiuta/ "electronic calculator", /kaa/ "automobile", /pi/ "climbing annual vine with edible seeds", /bata/ "emulsion of milkfat, water and air".
In giving the phonological encoding of these words, we've omitted the structure, because it is unambiguously recoverable from the string of elements. For instance, /kanpiuta/ must be a four-syllable word whose first syllable contains the onset /k/, the nucleus /a/, and the coda /n/, etc.
Real languages all have more complex phonological systems than our made-up language Outlandish does. However, it remains true that phonological structures are mostly recoverable from strings of phonological elements, and therefore can be omitted for convenience in writing. In this way of writing down phonological representations as strings of letter-like phonological elements, the "letters" are usually called phonemes.
We've exemplified half of the situation: the "Outlandish" example explains what kind of thing a phonological system is, and how the pronunciation of words can be specified by "spelling" them in phonological terms.
What about the phonetic interpretation of words, that is, the interpretation of phonemic strings in terms of mouth gestures and the accompanying noises? How does that work?
In the mid-19th century, Melville Bell invented a writing system that he called "Visible Speech." Bell was a teacher of the deaf, and he intended his writing system to be a teaching and learning tool for helping deaf students learn spoken language. However, Visible Speech was more than a pedagogical tool for deaf education -- it was the first system for notating the sounds of speech independent of the choice of particular language or dialect. This was an extremely important step -- without this step, it is nearly impossible to study the sound systems of human languages in any sort of general way.
In the 1860's, Melville Bell's three sons -- Melville, Edward and Alexander -- went on a lecture tour of Scotland, demonstrating the Visible Speech system to appreciative audiences. In their show, one of the brothers would leave the auditorium, while the others brought volunteers from the audience to perform interesting bits of speech -- words or phrases in a foreign language, or in some non-standard dialect of English. These performances would be notated in Visible Speech on a blackboard on stage.
When the absent brother returned, he would imitate the sounds produced by the volunteers from the audience, solely by reading the Visible Speech notations on the blackboard. In those days before the phonograph, radio or television, this was interesting enough that the Scots were apparently happy to pay money to see it!
After Melville Bell's invention, notations like Visible Speech were widely used in teaching students (from the provinces or from foreign countries) how to speak with a standard accent. This was one of the key goals of early phoneticians like Henry Sweet (said to have been the model for Henry Higgins, who teaches Eliza Doolittle to speak "properly" in Shaw's Pygmalion and its musical adaptation My Fair Lady).
The International Phonetic Association (IPA) was founded in 1886 in Paris, and has been ever since the official keeper of the Inernational Phonetic Alphabet (also IPA), the modern equivalent of Bell's Visible Speech. Although the IPA's emphasis has shifted in a more descriptive direction, there remains a lively tradition in Great Britain of teaching standard pronunciation using explicit training in the IPA.
The IPA and the dimensions of speech production
If you look at the ipa's table of "pulmonic eggressive" consonants you will see that it is organized along two main dimensions.
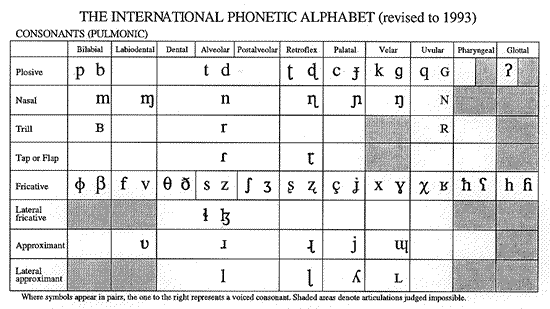
The columns are labelled by positions of constriction, moving from the lips (bilabial) past the teeth (dental) and the hard palate (palatal) and soft palate (velar) to the larynx (glottal). The rows are labelled by the type of manner of constriction: plosive, nasal, fricative, and so forth. The side-by-side pairs of plosives and fricatives are differentiated by whether layrngeal buzz is present during the constriction. Thus the dimensions along which the IPA is organized are basically the physical and functional dimensions of the human vocal tract The same was true of Bell's Visible Speech.
II. The traditional approach to the classification of segments was given in D. Abercrombie discussion of the analysis of articulatory action in segments representing consonants:
“We can arrive at a description of a consonant adequate enough by answering seven questions (although the answers will certainly not tell us everything about the segment). These questions are as follows:
1. What is the airstream mechanism?
2. Is the airstream ingressive or egressive?
3. What is the state of the glottis?
4. What is the position of the velum?
5. What is the active articulator?
6. What is the passive articulator?
7. What is the degree and nature of the stricture?
This widely followed method of classifying segments is usually called classification by place and manner of articulation. By “place” is meant the location of the maximum constriction (stricture) of the air channel. By “manner” is meant the type of stricture which the articulators are making to produce the segment, additionally it may include reference to the position of the velum and the airstream. Under this classification D. Abecrombier lists such terms as:
Fricative.
Stop.
Nasal.
Trill.
Flop.
Lateral.
Approximant.
Other writers tend to use a closely similar classifications. D. Abecrombier’s classification has been current for over a century and with minor differences is enshrined in the present structure of the IPA (International Phonetic Association) after the revision in Kiel Convention in 1989.
The traditional concept of “manner and place of articulation” appeals to the variety of classificatory criteria and thus has always been under the critics. (For example, the criticism offered by P. Roach.
III.
A more structural and coherent design for the classification of segments covering the terms “manner and place” was offered by J. Laver. The classification is called “The Classification of Segments by initiation, phonation, articulation and co-ordination. Thus, according to J.Laver the major categories of segmental classification are:

Initiation concerns the nature of the mecaniam which is responsible for setting the airstream in motion and for the consequent direction of the air flow.
The airstream can be pulmonic, glottalic and velaric. The initiation of the pulmonic airstream is the respiratory mechanism. In the case of the glottalic airstream, the initiator is the vertically moving larynx (glottis closed – voiceless sounds, vibrating – voiced sounds). In the velaric aiestream the tongue is the initiator (it traps the air within the mouth and compresses the pressure of the air). The direction of the air stream can be egressive (outwards from the body) and ingressive (inwards the body). Most sounds are made on a pulmonic eggresive airstrem. Other combinations are also possible:
glottalic eggressive airstream > adjective sounds;
glottalic inggressive airstream > implosive sounds;
velaric inggressive airstream > click sounds.
Phonation concerns the generation of acoustic energy at the larynx by the action of the vocal cords. The different major phonation types are:
voicelessness, whisper, voicing.
In its turn voicelessness is subdivided into nil phonation and breath phonation.
Voicing is divided into normal, creak and falsetto. Combinations such as whispery voice and creaky voice are possible and used for phonological and paralinguistic purposes. More elaborate combinations such as whispery creaky falsetto are physiologically possible but are not used for any phonological or paralinguistic purposes.
Articulation concerns the combination which organs along the vocal tract from the larynx to the lips make to shaping the airflow in audibly different ways. There are 3 subclassifications of articulation that characterize the performance of a segment:
the place of articulation (1);
the degree of stricture (2);
aspects of articulation (3).
(1) For the place of articulation the articulatory zones from lips to the glottis are as follows:
1) labial;
2) dental;
3) alveolar;
4) palatal;
5) velar;
6) uvular;
7) pharyngeal;
8) epiglottal;
9) glottal.
The constrictions can be made slightly further, forward or back to the margins of the identified zones. In this case the prefixes pre- and post – are used to characterize the segment:
Ex: post-alveolar, pre-palatal.
The articulation may also occur between 2 zones that are relatively close to each other and the label which will be given to the place of articulation in this case will be for example: labio-dental or denti-alveolar and etc.
Normally the constriction is achieved by an articulatory organ (usually the tongue) moving upwards towards the roof of the mouth. The moving articulator is called the active articulator and the stationary part of the vocal tract is called the passive articulator. For example, the sound k in the English word “cat”is made by the back of the tongue (the active articulator) and the soft palate (the passive articulator). This configuration of the vocal organs where the active articulator is able to make constrictions by interaction with the passive articulator that lies automatically directly opposite forms the neutral configuration. A smaller number of segments are made with the so called displaced configuration where the active articulator is dicplaced from its automatically neutral position. For example, the sounds f –v are made with the displaced configuration where the lower lip (active articulator) is displaced from its natural position right under the upper lip and it makes the constriction with the upper teeth (passive articulator).
A segment can be also characterized by simultaneous strictures made at more than 1 place of articulation. Where the two strictures are of equal degree the segment is said to have double articulation, for example the sound w (the first stricture is labial and is made by 2 lips and the second stricture is lingual and is made by the back of the tongue raised close to the soft palate. The important thing is that 2 strictures are made simultaneously.
There also may be secondary articulation where the primary is stricture of greater degree than the second one. In this case the suffix –ized – is given to indicate its non-primary nature. The example can be the labializaton of the sound sin its off-set position in the word soon.
(2) Talking about the degree of stricture we should remember the phases of articulation of a segment: on-set, medial phase, off-set. All segments can be described as having only 3 degrees of stricture:
1) complete closure (stops);
2) audible aerodynamic friction showing close approximation (fricatives);
3) the third degree is open approximation (the stricture here is any aperture that is large enough for airflow to go without significant turbulence (resonants).

(3) Aspect of articulation. It’s often necessary to make explicit reference in a segmental label to factors of articulation over and above those relating merely to the location and degree of stricture. These factors may include such matters as total air channel details of the topographical shape of the surface of the active articulator and the nature of the articulatory transition and the timing. Thes are the maun aspects of articulation which are subdivided into:
conformational (cover the detailed routing of the air channel, ex.: oral vs nasal);
topographical (concern categories of the shape of the tongue surface);
transitional (concern the articulatory maneuvers of the vocal organs when a steady state is not maintained during the medial phase of a segment).
Co-ordination concerns the articulatory and temporal relation between neighboring segments.