

4.7. Использование процедур
В традиционных языках программирования при вызове модуля или процедуры используется имя процедуры. При разработке систем искусственного интеллекта выбор модуля (образца или правила) осуществляется на основе текущего состояния проблемной области.
Совокупность правил, реализованных в управляющей структуре в соответствии с алгоритмом на основе исходной структуры данных, выполняется процедурами различного вида:
семантического и синтаксического контроля;
моделирования;
обработки и изменения структур данных и сред их сопровождения;
поиска решений.
Экспертная система должна выполнять процедуры, позволяющие реализовать процессы таким же образом, как это делает человек при использовании собственного опыта экспертных знаний и рассуждений. К одной из самых важных особенностей человеческого мышления можно отнести способность вырабатывать достаточно грамотные решения, опираясь на явно неполный или противоречивый набор исходных данных. Таким образом, в полноценной ЭС должны быть реализованы процедуры обработки неопределенностей.
4.8. Представление неопределенности в информационных приложениях с базами знаний
Организация логического вывода в экспертных системах предполагает наличие процедур описания процесса или его моделирования, организацию диалога с пользователем, а также обработку неполной и неточной информации. Это связано с тем, что описание процесса моделирования определяется не только данными, составляющими информационное ядро проекта, но и сведениями из БЗ, а также полученными в результате диалога с пользователем.
Неопределенность (рис. 4.6) можно определить как степень соответствия процесса или состояния характеристикам реального мира. Например, в системах искусственного интеллекта для обработки изображений неопределенностью является само изображение. Для его определения используются не только детерминированные, но и статистические и эвристические процедуры.
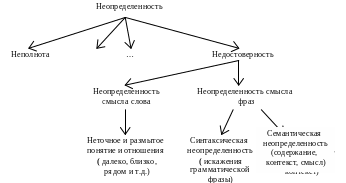
Рис. 4.6. Фрагмент классификация неопределенностей
Для исключения семантической неопределенности слов используются вероятностные характеристики и аппарат нечетких множеств.
Неопределенность смысла фраз идентифицируется с использованием лингвистического анализатора текста, причем отдельно анализируется как синтаксическая неопределенность (за счет грамматических искажений), так и семантическая (смысловые искажения).
Оценка семантической составляющей неопределенности может быть получена следующими методами:
с помощью вероятностных показателей различного рода;
с помощью коэффициентов уверенности и мощности правил в методе редукции;
с помощью введения интервалов значений и вероятностей попадания в заданный интервал;
использованием формулы Байеса;
использованием лингвистических переменных;
использованием переменных неопределенности и др.
Мощность правила – это апостериорная характеристика, определяемая по формуле:
Рпр = Куф * Купр , (4.1)
где Куф − коэффициент уверенности факта в условии,
Купр − коэффициент уверенности правила.
В зависимости от назначения системы коэффициенты уверенности либо определяются разработчиком системы, либо вносятся в систему пользователем в процессе ее эксплуатации.
Интервалы в определении неопределенности задаются как [-1, +1]. Конкретные значения показателей являются вероятностными характеристиками, однако: «-1» − всегда «ложь», а «+1» − всегда «истина».
Формула Байеса [18] имеет следующий вид:
![]() ,
(4.2)
,
(4.2)
где P(Hi) − априорная вероятность гипотезы Hi;
P(Hi | E) − вероятность гипотезы Hi при наступлении события E (апостериорная вероятность);
P(E | Hi) − вероятность наступления события E при истинности гипотезы Hi;
P(E) − вероятность наступления события E.
Апостериорная вероятность некоторого события E определяется через совокупность попарно несовместных гипотез Hi, образующих полную группу событий. Событие E существует, если существует гипотеза Hi. Вероятность вычисляется для каждой пары «гипотеза Hi − событие E».
Использование лингвистических переменных и переменных неопределенности характерно для систем, связанных с обработкой естественного языка. Переменная неопределенности описывается следующим кортежем:
Xнеопр. := < a, X, m >, (4.3)
где а – наименование переменной,
X – область определения значений переменных,
m – нечеткое множество, в которое попадает X значение нечеткой переменной или переменной неопределенности.
Лингвистическая переменная является следствием использования переменной неопределенности или используется вместо нее в системах обработки текстов. Лингвистическая переменная определяется кортежем:
Xл := < , , Х, S, T >, (4.4)
где – наименование лингвистической переменной;
– интервал значений, в который попадает лингвистическая переменная, областью для которой является X;
S – синтаксическая процедура использования лингвистической переменной;
T – семантическая процедура использования лингвистической переменной.