Методичні рекомендації
Для лінійної апроксимації статистичних даних у = тх +b, де т — тангенс кута нахилу прямої до вісі абсцис, b — ордината точки перетину прямої з віссю ординат, Ms Excel має такі функції прогнозування, що належать до категорії статистичних функцій: ПРЕДСКАЗ, ТЕНДЕНЦИЯ.
За допомогою функції ПРЕДСКАЗ обчислюється одне значення рівняння лінійної регресії. Вона має такий синтаксис: ПРЕДСКАЗ (х; відомі_знач_у; відомі_знач_х), де х — значення незалежної величини, що спостерігається (наприклад, певне значення часу), для якого передбачається значення залежної величини, що спостерігається; відомі_знач_у — масив відомих значень залежної величини, значення якої спостерігаються; відомі_знач_х — масив відомих значень незалежної величини (наприклад, значення часу), для яких відомі значення залежної величини, що спостерігається. Розмір масивів відомі_знач_у та відомі_знач_х має бути однаковим.
Якщо немає аргументу відомі_знач_х, то вважається, що це масив {1; 2; 3; ...; п}, де п — розмір масивів відомі_знач_у та відомі _знач_х.
Замість значень у ролі аргументів можуть бути адреси комірок та їх діапазони. Наприклад, у комірку В2 введено формулу:
![]()
За допомогою функції ТЕНДЕНЦИЯ вираховується значення рівняння лінійної регресії для діапазону значень незалежної змінної як для випадку одновимірного, так і для багатовимірного рівняння регресії. Багатовимірна лінійна модель регресії має такий вигляд:
![]() (1)
(1)
Функція має такий синтаксис:
ТЕНДЕНЦИЯ (відомі_знач_у; відомі_знач_х; нові__знач_ х; стала),
де нові знач__х— масив значень незалежної величини, що спостерігається (наприклад, певне значення часу), для якого передбачається значення залежної величини, що спостерігається; відомі_знач_у— масив відомих значень залежної величини, значення якої спостерігаються; відомі_знач_х — масив відомих значень незалежної величини (наприклад, значення часу), для яких відомі значення залежної величини, що спостерігається; стала — логічне значення, яке вказує, чи потрібно, щоб стала b у формулі (1) дорівнювала 0: істина або відсутність цього аргументу — b обчислюється, хибність — b вважається таким, що дорівнює 0.
Розмір масивів відомі_знач_у та відомі_знач_х має бути однаковим.
Для багатовимірного рівняння регресії слід задавати масиви відомі_знач_х та нові_знач_ х для кожної незалежної змінної. Якщо немає аргументу нові_знач_ х, то вважається, що масив нові_знач_ х збігається з масивом відомі_знач_х.
Для експоненціальної апроксимації статистичних даних
![]()
де с, b - сталі, Ms Excel має функцію прогнозування РОСТ.
Функція РОСТ має такий синтаксис:
РОСТ (відомі_знач_у; відомі_знач_х; нові_знач_ х; стала), де нові_знач_х — масив значень незалежної величини, що спостерігається (наприклад, певне значення часу), для якого передбачається значення залежної величини, що спостерігається; відомі_знач_у — масив відомих значень залежної величини, значення якої спостерігаються; відомі_знач_х — масив відомих значень незалежної величини (наприклад, значення часу), для яких відомі значення залежної величини, що спостерігається; стала — логічне значення, яке вказує, чи потрібно, щоб стала b у формулі (1) дорівнювала 0: істина або брак цього аргументу — b обчислюється, хибність — b вважається таким, що дорівнює 0.
Розмір масивів відомі_знач_у та відомі_знач_х має бути однаковим.
Для багатовимірного рівняння регресії варто задавати масиви відомі_знач_х і нові_знач_х для кожної незалежної змінної. Якщо аргументу нові_знач_х немає, то вважається, що масив нові__значх збігається з масивом відомі_знач_х.
Якщо немає аргументу відомі_знач_х, то вважається, що це масив {1; 2; 3; ...; п), де п — розмір масивів відомі знач_у та відомі знач_х.
Алгоритм розв'язання
У поточній книзі створіть робочий аркуш з ім'ям Функції, прогнозування.
Перевіримо, чи є підстави застосовувати функції прогнозування лінійного тренда ПРЕДСКАЗ та ТЕНДЕНЦИЯ. Скопіюємо на цей робочий аркуш вихідну таблицю із робочого аркуша Линия тренда, побудуємо гістограму і на ній — лінію тренда на зразок Линейная з відображенням величини достовірності апроксимації R^2 .
Якщо значення R^2 > 0,9 це дає підстави вважати рівняння лінії тренда прийнятним для прогнозування.
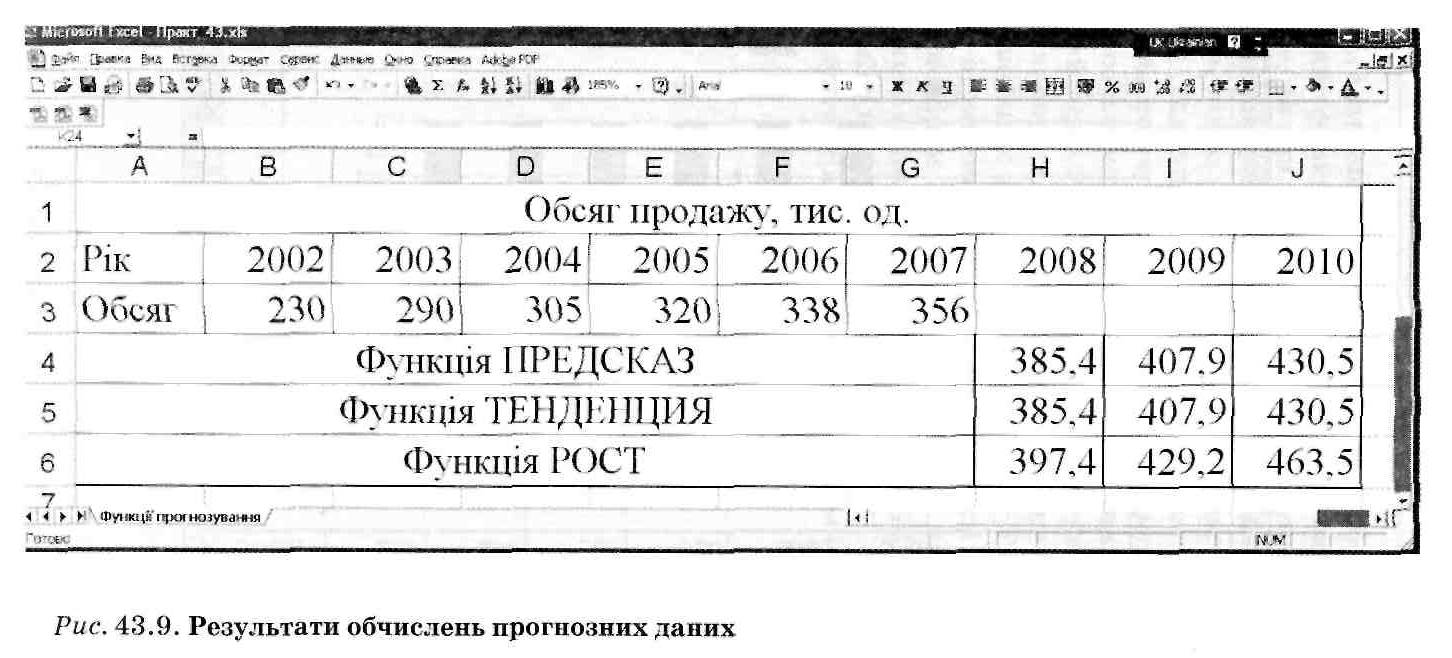
У комірку, введіть формулу =ПРЕДСКАЗ (Н2; $B$3:$G$3; $В$2:$О$2),використовуючи Майстер функцій, задайте аргументи в діалоговому вікні Аргументи функции шляхом натискання на кнопку ОК. Скопіюйте формули у комірки 14 та J4.
Порівняйте обчислені значення з тими, що зняті з лінії тренда, зробіть висновки.
Виділіть діапазон комірок Н5:І5 і введіть шляхом використання Майстра функцій формулу =ТЕНДЕНЦИЯ(Н5:І5; ВЗ: G3; B2:G2), клацніть на клавішу Ctrl + Shift +Enter.
Порівняйте отримані значення з тими, що обчислені шляхом використання функції ПРЕДСКАЗ. Зробіть висновки.Перевірте, чи є підстави застосовувати функцію прогнозування експоненціального тренда РОСТ. Для цього на гістограмі побудуйте лінію тренда на зразок Експоненциальная з відображенням величини достовірності апроксимації R^2 . Зробимо висновок: цей тип лінії тренда не підходить для прогнозування у цьому разі статистичних даних.
Переконайтеся в тому, що прогнозні значення, обчислені за допомогою використання функції РОСТ, значно відрізняються від обчислених за допомогою функцій ТЕНДЕНЦІЯ, ПРЕДСКАЗ та отриманих на основі лінії регресії логарифмічного типу. В комірки Н6:І6 уведіть шляхом використання Майстра функцій формулу = РОСТ(Н6:І6; B3:G3; B2:G2) і натисніть на клавіші Ctrl + Shift +Enter (рис. 5.1).
10. Проаналізуйте отримані прогнозні дані, зробіть висновки.