Вопрос 21. Состояния процесса в ос Unix.
Возможный набор состояний процесса содержится в следующем перечне:
1. Процесс выполняется в режиме задачи.
2. Процесс выполняется в режиме ядра.
3. Процесс не выполняется, но готов к запуску под управлением ядра.
4. Процесс приостановлен и находится в оперативной памяти.
5. Процесс готов к запуску, но программа подкачки (нулевой процесс) должна еще загрузить процесс в оперативную память, прежде чем он будет запущен под управлением ядра.
6. Процесс приостановлен и программа подкачки выгрузила его во внешнюю память, чтобы в оперативной памяти освободить место для других процессов.
7. Процесс возвращен из привилегированного режима (режима ядра) в непривилегированный (режим задачи), ядро резервирует его и переключает контекст на другой процесс.
8. Процесс вновь создан и находится в переходном состоянии; процесс существует, но не готов к выполнению, хотя и не приостановлен. Это состояние является начальным состоянием всех процессов, кроме нулевого.
9. Процесс вызывает системную функцию exit и прекращает существование. Однако, после него осталась запись, содержащая код выхода, и некоторая хронометрическая статистика, собираемая родительским процессом. Это состояние является последним состоянием процесса.
Вопрос 22.Распределение памяти процессов в unix.
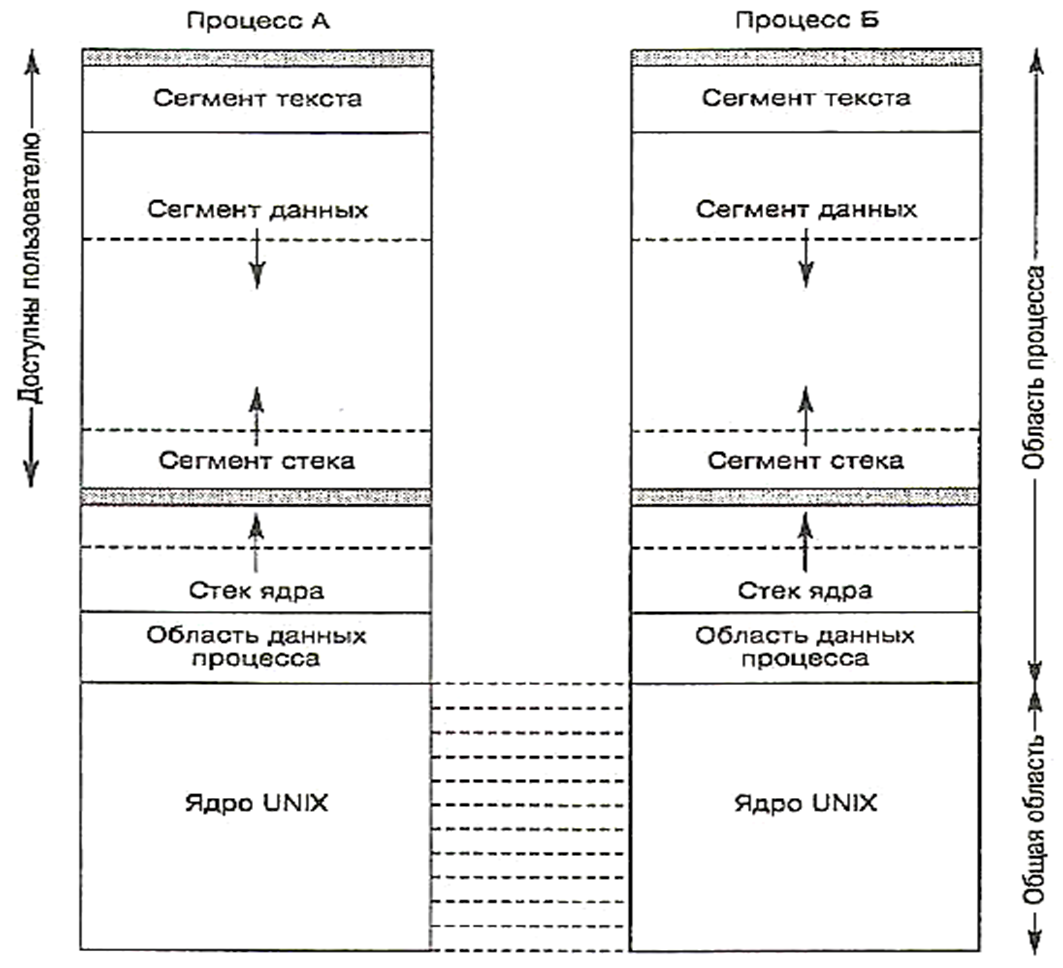
На рис. 14.9 показана схема адресных пространств двух процессов.
У каждого из процессов имеется собственное логическое адресное пространство.
Обычно адресное пространство процесса разделено на две части.
В одной из них резидентно располагается ядро UNIX, которое для каждого процесса находится по одним и тем же логическим адресам. Диспетчер памяти блокирует доступ по этим адресам, когда процесс выполняется в пользовательском режиме.
Другая часть адресного пространства предназначена собственно для процесса. При переключении контекста вся она может откачиваться на диск с целью освобождения памяти для других процессов.
Доступная пользовательскому коду часть адресного пространства делится на три логических сегмента:
текст (программный код),
данные
и стек.
Сегмент текста защищен от записи и может использоваться совместно с другими процессами для выполнения общей программы.
Сегменты стека и данных приватны для процесса.
Эти сегменты называются логическими, поскольку каждый из них занимает непрерывную область логического адресного пространства процесса, однако на практике при использовании страничного управления памятью они нередко располагаются в физической памяти отдельными фрагментами и даже могут быть выгружены на диск.
При компиляции исходного кода программы формируется виртуальное адресное пространство процесса. При этом для каждого из сегментов предусматривается свой диапазон виртуальных адресов. В 32-х разрядных операционных системах, где максимально допустимый размер адресуемой памяти составляет 4 ГБ, виртуальное адресное пространство делится на т.н. квадранты, имеющие размер 1 ГБ каждый. Первый квадрант содержит сегмент кода, второй – сегмент данных, третий и четвертый – разделяемую память, разделяемые библиотеки и файлы, отображаемые на память. Таким образом, начальные виртуальные адреса для каждого из сегментов фиксированы.
В UNIX адресное пространство процесса состоит из регионов. Регион это логическое понятие, обозначающее непрерывный диапазон виртуальных адресов процесса, который может рассматриваться как самостоятельный объект с точки зрения защиты или совместного использования. Обычно сегменты загружаются в отдельные регионы. Так любой процесс состоит из регионов кода, данных и стека, кроме того дополнительно могут быть созданы специальные регионы разделяемой памяти, памяти отображаемой на файл и т.д. Для каждого региона в отдельности можно указать права доступа по чтению, чтению-записи и чтению-исполнению.
Регион может находиться в исключительном пользовании одного процесса или совместно использоваться несколькими. Разделение региона данных происходит только по прямому указанию пользователя и при явном взаимном согласии обоих процессов Регион - понятие логическое, они должны каким-то образом отображаться на физическое адресное пространство. Если бы регионы отображались в непрерывные диапазоны физических адресов памяти, возникала бы проблема фрагментации, поэтому регион отображается на некоторую совокупность страниц памяти. Это означает, что для каждого региона существует свое оглавление - список страниц, образующих его адресное пространство.
Каждый процесс хранит в своем контексте таблицу регионов процесса с указанием виртуальных адресов начала региона, его длины и атрибутов доступа к региону: право чтения, записи и чтения-исполнения. Кроме того для каждого региона хранится ссылка на таблицу размещения региона в памяти
Таким образом, в UNIX применена многоуровневая система отображения адресного пространства процесса сначала на регион, затем на страницы фиксированного размера и лишь последние отображены на физическую память компьютера.