

Операции над нечеткими подмножествами
Для классических множеств вводятся операции:
пересечение множеств – операция над множествами А и В, результатом которой является множество
C=A∩B,
которое содержит только те элементы, которые принадлежат и множеству A и множеству B;
объединение множеств — операция над множествами А и В, результатом которой является множество
C=A∪B,
которое содержит те элементы, которые принадлежат множеству A или множеству B или обоим множествам;
отрицание множеств — операция над множеством А, результатом которой является множество
C=¬A, которое содержит все элементы, которые принадлежат универсальному множеству, но не принадлежат множеству A.
 Заде
предложил набор аналогичных операций
над нечеткими множествами через операции
с функциями принадлежности этих множеств.
Так, если множество А задано функцией
Заде
предложил набор аналогичных операций
над нечеткими множествами через операции
с функциями принадлежности этих множеств.
Так, если множество А задано функцией
μA(u),
а множество В задано функцией
μB(u),
то результатом операций является множество С с функцией принадлежности
μC(u)
причем:
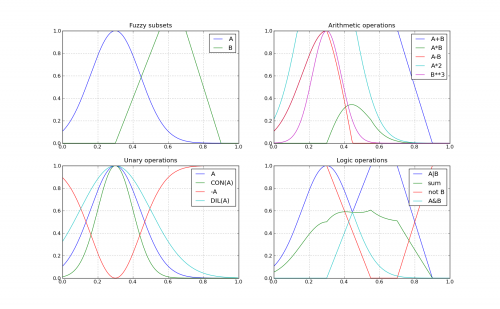
C=A∩B, → μC(u)=min(μA(u),μB(u));
C=A∪B, → μC(u)=max(μA(u),μB(u));
C=¬A, → μC(u)=1−μA(u).
Лингвистическая переменная
Лингвистическая переменная — в теории нечетких множеств, переменная, которая может принимать значения фраз из естественного или искусственного языка. Например, лингвистическая переменная «скорость» может иметь значения «высокая», «средняя», «очень низкая» и т. д. Фразы, значение которых принимает переменная, в свою очередь являются именами нечетких переменных и описываются нечетким множеством.
Лингвистическая переменная отличается от числовой переменной тем, что ее значениями являются не числа, а слова или предложения в естественном или формальном языке. Поскольку слова в общем менее точны, чем числа, понятие лингвистической переменной дает возможность приближенно описывать явления, которые настолько сложны, что не поддаются описанию в общепринятых количественных терминах. В частности, нечеткое множество, которое представляет собой ограничение, связанное со значениями лингвистической переменной, можно рассматривать как совокупную характеристику различных подклассов элементов универсального множества. В этом смысле роль нечетких множеств аналогична той роли, которую играют слова и предложения в естественном языке. Заде определяет лингвистическую переменную так:
Ω=⟨ω,T(ω),U,G,M⟩
где Ω — название переменной, Т – терм-множество значений, т.е. совокупность ее лингвистических значений, U – носитель, G – синтаксическое правило, порождающее термы множества Т, М – семантическое правило, которое каждому лингвистическому значению ω ставит в соответствие его смысл М(ω), причем М(ω) обозначает нечеткое подмножество носителя U.
Алгоритм нечеткого выбора
1 Этап. Фазификация входных данных.
Здесь лингвистическая переменная вх. И вых., которые описаны термами, ф-ми принадлежности.
Для каждого входа вычисляется значения, ф-ии принадлежности.
Вход – х, ф-ия принадлежности.
2. Активизация правил логического вывода.
Для каждого правила нужно вычислять степень истинности.
3. Аккумуляция правил.
Для каждого терма решения вычисляется уровень истинности из соответствующих уровней «-го Этапа.
4. Дефазификация входных данных.
Для каждого нечеткого множества решений указывается точечное значение (оно совпадает с центром тяжести)
Пример:
Ч Ч исло 2 Ч исло 3 |
Т ерм 1 Т ерм 2 Терм 3 |
Правило 1 Правило 2 Правило 3 |
Т У ровень истинности |
Число решений |
|
1 этап |
2 этап |
3 этап |
4 этап |
 исло
1
исло
1 ерм
решения
ерм
решения