

10. Каскадная модель
Каскадная модель жизненного цикла («модель водопада», англ. waterfall model) была предложена в 1970 г. Уинстоном Ройсом. Она предусматривает последовательное выполнение всех этапов проекта в строго фиксированном порядке. Переход на следующий этап означает полное завершение работ на предыдущем этапе. Требования, определенные на стадии формирования требований, строго документируются в виде технического задания и фиксируются на все время разработки проекта. Каждая стадия завершается выпуском полного комплекта документации, достаточной для того, чтобы разработка могла быть продолжена другой командой разработчиков.
Этапы проекта в соответствии с каскадной моделью:
Формирование требований;
Проектирование;
Реализация;
Тестирование;
Внедрение;
Эксплуатация и сопровождение.
[править]Спиральная модель
Спиральная модель (англ. spiral model) была разработана в середине 1980-х годов Барри Боэмом. Она основана на классическом цикле Деминга PDCA (plan-do-check-act). При использовании этой модели ПО создается в несколько итераций (витков спирали) методом прототипирования.
Каждая итерация соответствует созданию фрагмента или версии ПО, на ней уточняются цели и характеристики проекта, оценивается качество полученных результатов и планируются работы следующей итерации.
На каждой итерации оцениваются:
риск превышения сроков и стоимости проекта;
необходимость выполнения ещё одной итерации;
степень полноты и точности понимания требований к системе;
целесообразность прекращения проекта.
Один из примеров реализации спиральной модели — RAD (англ. Rapid Application Development, метод быстрой разработки приложений).
[править]Итерационная модель
Естественное развитие каскадной и спиральной моделей привело к их сближению и появлению современного итерационного подхода, который представляет рациональное сочетание этих моделей. Различные варианты итерационного подхода реализованы в большинстве современных технологий и методов (RUP, MSF, XP).
11.
 12.
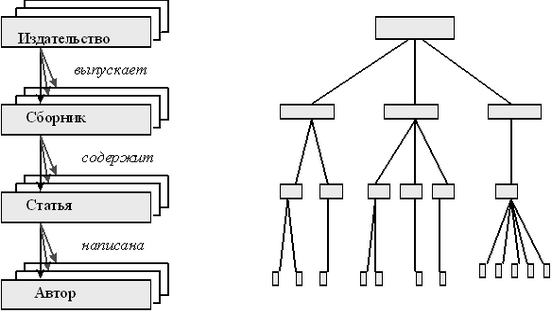
Иерархические базы данных могут быть
представлены как дерево, состоящее из
объектов различных уровней. Верхний
уровень занимает один объект, второй —
объекты второго уровня и т. д.
12.
Иерархические базы данных могут быть
представлены как дерево, состоящее из
объектов различных уровней. Верхний
уровень занимает один объект, второй —
объекты второго уровня и т. д.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами
13.
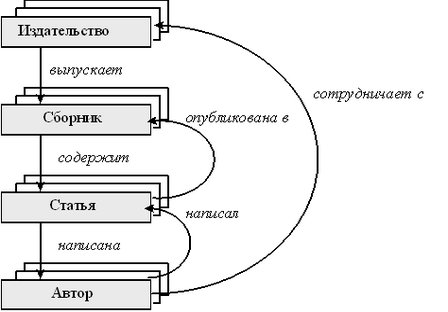
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных.
Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков.
Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями.
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L;
каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L.
14.
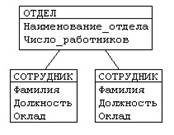
Рис. 1
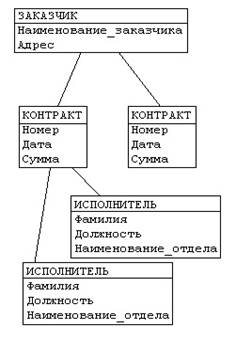
Рис. 2
деревья (рис. 1) и (рис. 2)заменяются одной сетевой структурой, в которой запись СОТРУДНИК входит в два групповых отношения;
для отображения типа M:N вводится запись СОТРУДНИК_КОНТРАКТ, которая не имеет полей и служит только для связи записей КОНТРАКТ и СОТРУДНИК (рис. 4).
В этой записи может храниться и полезная информация, например, доля данного сотрудника в общем вознаграждении по данному контракту.
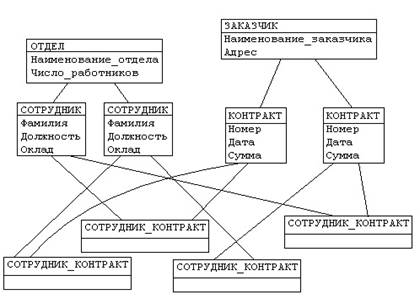
Рис. 4
15.
Реляционная модель данных — логическая модель данных, прикладная теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математики как теории множеств и логика первого порядка.
На реляционной модели данных строятся реляционные базы данных.
Реляционная модель данных включает следующие компоненты:
Структурный аспект (составляющая) — данные в базе данных представляют собой набор отношений.
Аспект (составляющая) целостности — отношения (таблицы) отвечают определенным условиям целостности. РМД поддерживает декларативные ограничения целостности уровня домена (типа данных), уровня отношения и уровня базы данных.
Аспект (составляющая) обработки (манипулирования) — РМД поддерживает операторы манипулирования отношениями (реляционная алгебра, реляционное исчисление).
16.
Реляционные ключи
Ключ отношения — атрибут или набор атрибутов, значения которых могут однозначным образом идентифицировать кортеж данного отношения. Ключ отношения должен удовлетворять следующим условиям:
•Условие уникальности — в отношении не может быть двух кортежей с одинаковым набором значений ключевых атрибутов;
•Условие минимальности — из ключа нельзя исключить ни одного атрибута без потери условия уникальности.
В отношении может быть несколько ключей, из которых складывается множество потенциальных ключей отношения.
Первичный ключ — потенциальный ключ, который выбран для уникальной идентификации кортежей внутри отношения.
Внешний ключ — атрибут или множество атрибутов внутри отношения, которое соответствует потенциальному ключу некоторого (возможно, того же самого) отношения и служит для связи отношений между собой.
Реляционная целостность
Определитель NULL — значение атрибута в данный момент неизвестно или неприемлемо.
Целостность сущностей — в базовом отношении ни один атрибут первичного ключа не может содержать отсутствующих значений, обозначаемых оператором NULL.
Ссылочная целостность — значение внешнего ключа должно соответствовать значению потенциального ключа некоторого кортежа либо задаваться определителем NULL.
Согласно определению, реляционная база данных представляет собой набор нормализованных отношений (таблиц). Под «нормализованными отношениями» понимают соответствие отношений определённому набору правила, а процесс приведения модели БД в нормализованную форму называют нормализацией.
17.
Можно определить два различных типа записи отражающих операции над отношениями:
Реляционная алгебра т.е. алгебраическое изображение, в котором запросы выражаются с помощью специальных операторов отношений.
Реляционное исчисление т.е. логическое изображение, в котором запросы выражаются с помощью формулирования некоторых логических ограничений, которым должны удовлетворять кортежи.
Реляционная алгебра
Реляционная алгебра была представлена E. F. Codd в 1972 году. Она состоит из множества операций над отношениями:
ВЫБОРКА(SELECT) (σ): извлечь кортежи из отношения, которые удовлетворяют заданным условиям. Пусть R - таблица, содержащая атрибут A. σA=a(R) = {t ∈ R ∣ t(A) = a} где t обозначает кортеж R и t(A) обозначает значение атрибута A кортежа t.
ПРОЕКЦИЯ(PROJECT) (π): извлечь заданные атрибуты (колонки) из отношения. Пусть R отношение, содержащее атрибут X. πX(R) = {t(X) ∣ t ∈ R}, где t(X) обозначает значение атрибута X кортежа t.
ПРОИЗВЕДЕНИЕ(PRODUCT) (×): построить декартово произведение двух отношений. Пусть R - таблица, со степенью k1 и пусть S таблица со степенью k2. R × S - это множество всех k1 + k2 - кортежей, где первыми являются k1 элементы кортежа R и где последними являются k2 элементы кортежа S.
ОБЪЕДИНЕНИЕ(UNION) (∪): построить теоретико-множественное объединение двух таблиц. Даны таблицы R и S (обе должны иметь одинаковую степень), объединение R ∪ S - это множество кортежей, принадлежащих R или S или обоим.
ПЕРЕСЕЧЕНИЕ(INTERSECT) (∩): построить теоретико-множественное пересечение двух таблиц. Даны таблицы R и S, R ∪ S - это множество кортежей, принадлежащих R и S. Опять необходимо, чтобы R и S имели одинаковую степень.
ВЫЧИТАНИЕ(DIFFERENCE) (− или ∖): построить множество различий двух таблиц. Пусть R и S опять две таблицы с одинаковой степенью. R - S - это множество кортежей R,не принадлежащих S.
СОЕДИНЕНИЕ(JOIN) (∏): соединить две таблицы по их общим атрибутам. Пусть R будет таблицей с атрибутами A,B и C и пусть S будет таблицей с атрибутами C,D и E. Есть один атрибут, общий для обоих отношений, атрибут C. R ∏ S = πR.A,R.B,R.C,S.D,S.E(σR.C=S.C(R × S)). Что же здесь происходит? Во-первых, вычисляется декартово произведение R × S. Затем, выбираются те кортежи, чьи значения общего атрибута C эквивалентны (σR.C = S.C). Теперь мы имеем таблицу, которая содержит атрибут C дважды и мы исправим это, выбросив повторяющуюся колонку.
18.
Правила Кодда для реляционной СУБД (РСУБД)
1)Явное представление данных (The Information Rule). Информация должна быть представлена в виде данных, хранящихся в ячейках. Данные, храня-щиеся в ячейках, должны быть атомарны. Порядок строк в реляционной таблице не должен влиять на смысл данных.
2)Гарантированный доступ к данным (Guaranteed Access Rule). К каждому элементу данных должен быть гарантирован доступ с помощью комбинации имени таблицы, первичного ключа строки и имени столбца.
3)Обработка неизвестных значений (Systematic Treatment of Null Values). Неизвестные значения NULL, отличные от любого известного значения, должны поддерживаться для всех типов данных при выполнении любых операций. Например, для числовых данных неизвестные значения не должны рассматриваться как нули, а для символьных данных – как пустые строки.
4)Динамический каталог данных, основанный на реляционной модели (Dynamic On-Line Catalog Based on the Relational Model). Каталог (или словарь-справочник) данных должен сохраняться в форме реляционных таблиц, и РСУБД должна поддерживать доступ к нему при помощи стандартных языковых средств, тех же самых, которые используются для работы с реляционными таблицами, содержащими пользовательские данные.
5)Полнота подмножества языка (Comprehensive Data Sublanguage Rule). РСУБД должна поддерживать единственный язык, который позволяет выполнять все операции над данными: определение данных (DDL, Data Definition Language), манипулирование данными (DML, Data Manipulation Language), управление доступом пользователей к данным, управление транзакциями.
6)Поддержка обновляемых представлений (View Updating Rule). Представление (view) – это хранимый запрос к таблицам базы данных. (Подробнее о представлениях рассказано в [3]). Обновляемое представление должно поддерживать все операции манипулирования дан-ными, которые поддерживают реляционные таблицы: операции вставки, модификации и удаления данных.
7)Наличие высокоуровневых операций управления данными (High-Level Insert, Update, and Delete). Операции вставки, модификации и удаления данных должны поддерживаться не только по отношению к одной строке таблицы, но по отношению к любому множеству строк произвольной таблицы.
8)Физическая независимость данных (Physical Data Independence). Приложения не должны зависеть от используемых способов хранения данных на носителях, от аппаратного обеспечения компьютера, на котором находится БД. РСУБД должна предоставлять некоторую свободу модификации способов организации базы данных в среде хранения, не вызывая необходимости внесения изменений в логическое представление данных. Это позволяет оптимизировать среду хранения данных с целью повышения эффективности системы, не затрагивая созданных прикладных программ, работающих с БД.
9)Логическая независимость данных (Logical Data Independence). Это свойство позволяет сконструировать несколько различных логических взглядов (представлений) на одни и те же данные для разных групп пользователей. При этом пользовательское представление данных может сильно отличаться не только от физической структуры их хранения, но и от концептуальной (логической) схемы данных. Оно может синтезироваться динамически на основе хранимых объектов БД в процессе обработки запросов.
10)Независимость контроля целостности (Integrity Independence). Вся информация, необходимая для поддержания целостности, должна находиться в словаре данных. Язык для работы с данными должен выполнять проверку входных данных и автоматически поддерживать целостность данных. Это реализуется с помощью ограничений целостности и механизма транзакций (см. разделы 5.2 и 6.1).
11)Независимость от распределённости (Distribution Independence). База данных может быть распределённой (может находиться на нескольких компьютерах), и это не должно оказывать влияние на приложения. Перенос базы данных на другой компьютер не должен оказывать влияние на приложения.
12)Согласование языковых уровней (Non-Subversion Rule). Не должно быть иного средства доступа к данным, отличного от стандартного языка для работы с данными. Если используется низкоуровневый язык доступа к данным, он не должен игнорировать правила безопасности и целостности, которые поддерживаются языком более высокого уровня.
19.
Трехуровневая архитектура ANSI-SPARC.
В данной архитектуре особое внимание было уделено изоляции программных приложений от особенностей представления общих данных в БД на низком уровне. Для этого были введены три уровня представления данных: внешний (external), концептуальный (conseptual) и внутренний (internal). Цель заключалась в отделении пользовательского представления данных (external) от её физического представления в БД (internal), при ссохранении связи между ними с помощь концептуального уровня. Ниже перечислены причины такого деления:
· Каждый пользователь должен обращаться к одним и тем же данным, используя своё представление о них. Каждый пользователь имеет возможность изменения своего представления о данных без влияния на других пользователей.
· Взаимодействие пользователя с БД не должно зависить от особенностей хранения данных типа индексирования или хеширование.
· АБД должен иметь возможность изменять структуру физического хранения данных, не оказывая влияния на представления данных пользователей.
· Внутренняя структура данных не должна зависить от таких аспектов хранения, как переключение на новое устройство хранения.
· АБД должен иметь возможность изменения глобальной структуры БД без какого-либо влияния на пользователей.
Отметим, что ниже внутреннего уровня находится физический уровень хранения данных (на уровне файлов), который использует операционную систему и контролируется СУБД.
20.
Процесс проектирования бд является достаточно сложной задачей. Он начинается с построения инфологической модели данных , т.е. идентификации сущностей. Затем необходимо выполнить следующие шаги процедуры проектирования даталогической модели.
1. Представить каждый стержень (независимую сущность) таблицей базы данных (базовой таблицей) и специфицировать первичный ключ этой базовой таблицы.
2. Представить каждую ассоциацию (связь вида "многие-ко-многим" или "многие-ко-многим-ко-многим" и т.д. между сущностями) как базовую таблицу. Использовать в этой таблице внешние ключи для идентификации участников ассоциации и специфицировать ограничения, связанные с каждым из этих внешних ключей.
3. Представить каждую характеристику как базовую таблицу с внешним ключом, идентифицирующим сущность, описываемую этой характеристикой. Специфицировать ограничения на внешний ключ этой таблицы и ее первичный ключ – по всей вероятности, комбинации этого внешнего ключа и свойства, которое гарантирует "уникальность в рамках описываемой сущности".
4. Представить каждое обозначение, которое не рассматривалось в предыдущем пункте, как базовую таблицу с внешним ключом, идентифицирующим обозначаемую сущность. Специфицировать связанные с каждым таким внешним ключом ограничения.
5. Представить каждое свойство как поле в базовой таблице, представляющей сущность, которая непосредственно описывается этим свойством.
6. Для того чтобы исключить в проекте непреднамеренные нарушения каких-либо принципов нормализации, выполнить описанную в п. 4.6 процедуру нормализации.
7. Если в процессе нормализации было произведено разделение каких-либо таблиц, то следует модифицировать инфологическую модель базы данных и повторить перечисленные шаги.
8. Указать ограничения целостности проектируемой базы данных и дать (если это необходимо) краткое описание полученных таблиц и их полей.
21. Основные задачи проектирования баз данных
Основные задачи:
Обеспечение хранения в БД всей необходимой информации.
Обеспечение возможности получения данных по всем необходимым запросам.
Сокращение избыточности и дублирования данных.
Обеспечение целостности данных (правильности их содержания): исключение противоречий в содержании данных, исключение их потери и т.д.
Основные этапы проектирования баз данных
Концептуальное (инфологическое) проектирование – построение формализованной модели предметной области. Такая модель строится с использованием стандартных языковых средств, обычно графических, например ER-диаграмм. Такая модель строится без ориентации на какую-либо конкретную СУБД.
Основные элементы данной модели:
Описание объектов предметной области и связей между ними.
Описание информационных потребностей пользователей (описание основных запросов к БД).
Описание алгоритмических зависимостей между данными.
Описание ограничений целостности, т.е. требований к допустимым значениям данных и к связям между ними.
Логическое (даталогическое) проектирование – отображение инфологической модели на модель данных, используемую в конкретной СУБД, например на реляционную модель данных. Для реляционных СУБД даталогическая модель – набор таблиц, обычно с указанием ключевых полей, связей между таблицами. Если инфологическая модель построена в виде ER-диаграмм (или других формализованных средств), то даталогическое проектирование представляет собой построение таблиц по определённым формализованным правилам, а также нормализацию этих таблиц. Этот этап может быть в значительной степени автоматизирован.
Физическое проектирование – реализация даталогической модели средствами конкретной СУБД, а также выбор решений, связанных с физической средой хранения данных: выбор методов управления дисковой памятью, методов доступа к данным, методов сжатия данных и т.д. – эти задачи решаются в основном средствами СУБД и скрыты от разработчика БД.
На этапе инфологического проектирования в ходе сбора информации о предметной области требуется выяснить:
основные объекты предметной области (объекты, о которых должна храниться информация в БД);
атрибуты объектов;
связи между объектами;
основные запросы к БД.
22. Первый этап процесса проектирования базы данных называется концептуальным проектированием. Он заключается в создании концептуальной модели данных для анализируемой части предприятия. Эта модель данных создается на основе информации, записанной в спецификациях требований пользователей. Концептуальное проектирование базы данных абсолютно не зависит от таких подробностей ее реализации, как тип выбранной целевой СУБД, набор создаваемых прикладных программ, используемые языки программирования, тип выбранной вычислительной платформы, а также от любых других особенностей физической реализации. Концептуальная модель данных предприятия является источником информации для этапа логического проектирования базы данных.
23
Второй этап проектирования базы данных называется логическим проектированием базы данных. Его цель состоит в создании логической модели данных для исследуемой части предприятия. Концептуальная модель данных, созданная на предыдущем этапе, уточняется и преобразуется в логическую модель данных. Логическая модель данных учитывает особенности выбранной модели организации данных в целевой СУБД. Если концептуальная модель данных не зависит от любых физических аспектов реализации, то логическая модель данных создается на основе выбранной модели организации данных целевой СУБД. То есть на этом этапе уже должно быть известно, какая СУБД будет использоваться в качестве целевой – реляционная, сетевая, иерархическая или объектно-ориентированная. Но все остальные характеристики выбранной СУБД, например, любые особенности физической организации ее структур хранения данных и построения индексов. В процессе разработки логическая модель данных постоянно тестируется и проверяется на соответствие требованием пользователей. Для проверки правильности логической модели данных используется метод нормализации. Нормализация гарантирует, что отношения, выведенные из существующей модели данных, не будут обладать избыточностью данных, способной вызвать нарушения в процессе обновления данных после их физической реализации. Логическая модель данных должна обеспечивать поддержку всех необходимых пользователям транзакций. Созданная логическая модель данных является источником информации для этапа физического проектирования и обеспечивает разработчика физической базы данных средствами поиска компромиссов, необходимых для достижения поставленных целей, что очень важно для эффективного проектирования. Логическая модель играет важную роль на этапе эксплуатации и сопровождения готовой системы.
24
Физическое проектирование является третьим и последним этапом создания проекта базы данных, при выполнении которого проектировщик принимает решения о способах реализации разрабатываемой БД. Приступая к физическому проектированию БД, необходимость конкретную целевую СУБД. Основной целью физического проектирования Бд является описание способа физической реализации логического проекта БД. В случае реляционной модели БД под этим подразумевается следующее:
1.Создание набора реляционных таблиц и ограничений для них на основе информации, представленной в глобальной логической модели данных;
2.Определение конкретных структур хранения данных и методов доступа к ним, обеспечивающих оптимальную производительность СУБД;
3.Разработка средств защиты создаваемой системы.
25
Элементы модели
Сущность (entity) - это объект, который может быть идентифицирован неким способом, отличающим его от других объектов.
Набор сущностей (entity set) - множество сущностей одного типа (обладающих одинаковыми свойствами).
Сущность фактически представляет собой множество атрибутов, которые описывают свойства всех членов данного набора сущностей.
Обозначение сущности и ее атрибутов
СОТРУДНИК (ТАБЕЛЬНЫЙ_НОМЕР, ИМЯ, ВОЗРАСТ).
Ключ сущности
- это один или более атрибутов уникально определяющих данную сущность.
Связь (relationship)
- это ассоциация, установленная между несколькими сущностями.
Примеры:
поскольку каждый сотрудник работает в каком-либо отделе, между сущностями СОТРУДНИК и ОТДЕЛ существует связь "работает в" или ОТДЕЛ-РАБОТНИК;
так как один из работников отдела является его руководителем, то между сущностями СОТРУДНИК и ОТДЕЛ имеется связь "руководит" или ОТДЕЛ-РУКОВОДИТЕЛЬ;
могут существовать и связи между сущностями одного типа, например связь РОДИТЕЛЬ - ПОТОМОК между двумя сущностями ЧЕЛОВЕК;
Набор связей (relationship set)
- это отношение между n (причем n не меньше 2) сущностями, каждая из которых относится к некоторому набору сущностей.
Пример:
сущности наборы сущностей
---------- ----------------
e1 принадлежит E1
e2 принадлежит E2
. . .
en принадлежит En
тогда [e1,e2,...,en] - набор связей R
В случае n=2, т.е. когда связь объединяет две сущности, она называется бинарной.
Доказано, что n-арный набор связей (n>2) всегда можно заменить множеством бинарных, однако первые лучше отображают семантику предметной области.
26
Нормальная форма — свойство отношения в реляционной модели данных, характеризующее его с точки зрения избыточности, которая потенциально может привести к логически ошибочным результатам выборки или изменения данных. Нормальная форма определяется как совокупность требований, которым должно удовлетворять отношение.
Процесс преобразования базы данных к виду, отвечающему нормальным формам, называется нормализацией. Нормализация предназначена для приведения структуры базы данных к виду, обеспечивающему минимальную избыточность, то есть нормализация не имеет целью уменьшение или увеличение производительности работы или же уменьшение или увеличение объёма БД. Конечной целью нормализации является уменьшение потенциальной противоречивости хранимой в БД информации.
Устранение избыточности производится, как правило, за счёт декомпозиции отношений таким образом, чтобы в каждом отношении хранились только первичные факты (то есть факты, не выводимые из других хранимых фактов).
При использовании универсального отношения возникают две проблемы:
- избыточность данных;
- потенциальная противоречивость (аномалии).
Под избыточностью понимают повторение данных в разных строках одной таблицы или в разных таблицах БД. Так, для каждого сотрудника отдела 128 повторяются данные «128, Отдел проектирования».
Аномалии – это проблемы, возникающие в данных из-за дефектов проектирования БД. Существуют три вида аномалий: вставки, удаления и модификации.
Аномалии вставки проявляются при вводе данных в дефектную таблицу. Добавляя информацию о новом сотруднике, мы должны добавить номер и название отдела. Если ввести данные, не соответствующие имеющимся в таблице (например, 42, отдел проектирования), будет не ясно, какая из строк БД содержит правильную информацию.
Аномалии удаления возникают при удалении данных из дефектной схемы. Предположим, что все сотрудники отдела 128 уволились в один и тот же день. После удаления записей этих сотрудников в БД больше не будет ни одной записи, содержащей информацию об отделе 128.
Аномалии модификации возникают при изменении данных дефектной схемы. Предположим, что отдел 128 решили переименовать в отдел передовых технологий. Необходимо изменить соответствующие данные о каждом сотруднике отдела. Если мы пропустим хотя бы одну запись, возникнет аномалия модификации.
Функциональная зависимость — концепция, лежащая в основе многих вопросов, связанных с реляционными базами данных, включая, в частности, их проектирование. Математически представляет бинарное отношение между множествами атрибутов данного отношения и является, по сути, связью типа «один ко многим». Их использование обусловлено тем, что они позволяют формально и строго решить многие проблемы.
Функциональные зависимости являются ограничениями целостности и определяют семантику хранящихся в БД данных. При каждом обновлении СУБД должна проверять их соблюдение. Следовательно, наличие большого количества функциональных зависимостей нежелательно, иначе происходит замедление работы. Для упрощения задачи необходимо сократить набор функциональных зависимостей до минимально необходимого.
Если I является неприводимым покрытием исходного множества функциональных зависимостей S, то проверка выполнения функциональных зависимостей из I автоматически гарантирует выполнение всех функциональных зависимостей из S. Таким образом, задача поиска минимально необходимого набора сводится к отысканию неприводимого покрытия множества функциональных зависимостей, которое и будет использоваться вместо исходного множества.
27
Нормализация БД, приведение к 1НФ, 2НФ, 3НФ, НФБК.
Нормализация БД - это процесс уменьшения избыточности информации в БД. Метод нормализации основан на достаточно сложной теории реляционных моделей данных.
При разработке структуры БД могут возникнуть проблемы, связанные:
· с избыточностью данных;
· с аномалиями.
Под избыточностью данных понимают дублирование данных, содержащихся в БД. При этом различают простое (неизбыточное) дублирование и избыточное дублирование данных.
Избыточность данных при выполнении операций с ними приводит к различным аномалиям — нарушению целостности БД. Выделим аномалии:
· удаления;
· обновления;
· ввода.
Процесс проектирования БД с использованием метода нормальных форм является итерационным (пошаговым) и заключается в последовательном переводе по определенным правилам отношений из первой нормальной формы в нормальные формы более высокого порядка. Каждая следующая нормальная форма ограничивает определенный тип функциональных зависимостей, устраняет соответствующие аномалии при выполнении операций над отношениями БД и сохраняет свойства предшествующих нормальных форм.
К первой нормальной форме выполняться следующие условия:
· поля содержат неделимую информацию;
· в таблице отсутствуют повторяющиеся группы полей.
Ко второй нормальной форме предъявляются следующие требования:
· таблица должна удовлетворять требованиям первой нормальной формы;
· любое неключевое поле должно однозначно идентифицироваться ключевыми полями.
Требованиями третьей нормальной формы являются следующие:
· таблица должна удовлетворять требованиям второй нормальной формы;
· ни одно из неключевых полей не должно однозначно идентифицироваться значением другого неключевого поля (полей).
Нормальная форма Бойса-Кодда требует, чтобы в таблице был только один потенциальный первичный ключ. Если обнаружился второй столбец (возможно не один), позволяющий однозначно идентифицировать строку, то для приведения к НФБК такие данные надо вывести в отдельную таблицу.
Четвертая нормальная форма
-Отношение находится в четвертой нормальной форме, если оно соответствует нормальной форме Бойса-Кодда, и в ней нет многозначных зависимостей.
28
Шаг 1.
Получение исходного множества функциональных зависимостей.
Рассматриваются все сочетания атрибутов (1,2 ,3, …..n).
Не рассматриваются варианты, которые являются следствием теорем о функциональных зависимостях.
Шаг 2. Поиск минимального покрытия функциональных зависимостей: множество, из которого удалены зависимости, являющиеся следствием оставшихся зависимостей.
F={f1, f2, …. , fn}
Шаг 3. Для каждого fi создать отношение
Шаг 4. Если первичный ключ исходного отношения не вошел ни в одну проекцию, то создать дополнительное отношение, содержащее этот ключ
Примечание:
Для взаимно однозначных зависимостей принято выделять «старший» атрибут, который затем представляет все атрибуты взаимно однозначного соответствия.
Пример:
Предположим, что для учебной части факультета создается БД о преподавателях.
На первом этапе проектирования БД в результате общения с заказчиком (заведующим учебной частью) должны быть определены содержащиеся в базе сведения о том, как она должна использоваться и какую информацию заказчик хочет получать в процессе ее эксплуатации.
В результате устанавливаются атрибуты, которые должны содержаться в отношениях БД, и связи между ними.
29
Получение реляционной схемы из ER-диаграммы.
1. Каждая простая сущность превращается в таблицу (отношение). Имя сущности становится именем таблицы.
2. Каждый атрибут становится возможным столбцом с тем же именем. Столбцы, соответствующие необязательным атрибутам, могут содержать неопределенные значения; столбцы, соответствующие обязательным атрибутам – не могут. Если атрибут является множественным, то для него строится отдельное отношение.
3. Компоненты уникального идентификатора сущности превращаются в первичный ключ. Если имеется несколько возможных уникальных идентификаторов, выбирается наиболее используемый. Если в состав уникального идентификатора входят связи, то к числу столбцов первичного ключа добавляется копия уникального идентификатора сущности, находящейся на дальнем конце связи (этот процесс может продолжаться рекурсивно). Для именования этих столбцов используются имена концов связей и/или имена сущностей.
4. Связи «многие к одному» и «один к одному» становятся внешними ключами. Т.е. создается копия уникального идентификатора с конца связи «один», и соответствующие столбцы составляют внешний ключ.
5. Индексы создаются для первичного ключа (уникальный индекс), а также внешних ключей и тех атрибутов, которые будут часто использоваться в запросах.
6. Если в концептуальной схеме присутствуют подтипы, то возможны два варианта.
Все подтипы хранятся в одной таблице, которая создается для самого внешнего супертипа, а для подтипов создаются представления. В таблицу добавляется по крайней мере один столбец, содержащий код типа, и он становится частью первичного ключа.
Во втором случае для каждого подтипа создается отдельная таблица (для более нижних – представления) и для каждого подтипа первого уровня супертип воссоздается с помощью представления UNION (из всех таблиц подтипов выбираются общие столбцы – столбцы супертипа).
7. Если остающиеся внешние ключи все принадлежат одному домену, т.е. имеют общий формат, то создаются два столбца: идентификатор связи и идентификатор сущности. Столбец идентификатора связи используется для различных связей. Столбец идентификатора сущности используется для хранения значений уникального идентификатора сущности на дальнем конце соответствующей связи.
Если результирующие внешние ключи не относятся к одному домену, то для каждой связи, покрываемой дугой исключения, создаются явные столбцы внешних ключей.
30
Нормализацию можно проводить на уровне инфологической (семантической) модели:
Шаг 1. Проанализировать схему на присутствие сущностей, которые скрыто моделируют несколько классов объектов (это соответствует ненормализованным отношениям). Если такое выявлено, разделить такую сущность на несколько и установить между ними связи.
Шаг 2. Проанализировать сущности, имеющие составные ключи, на наличие неполных функциональных зависимостей. Если такое выявлено, разделить такую сущность на две, определить для каждой первичные ключи и установить между ними связи.
Шаг 3. Проанализировать неключевые атрибуты на наличие транзитивных зависимостей. Если такое выявлено, разделить такую сущность на несколько.
Шаг 4. Проанализировать сущности на наличие детерминантов, которые не являются возможными ключами. Если такое выявлено, разделить такую сущность на две и установить между ними связи.
Шаг 5. Проанализировать сущности на наличие многозначных зависимостей. Если обнаружатся сущности, имеющие более одной многозначной зависимости, разделить такую сущность на две и установить между ними связи.
Шаг 6. Проанализировать сущности на наличие в них зависимости проекции-соединения. При наличии таковых разделить сущности на необходимое число взаимосвязанных сущностей и установить между ними связи.
31
представляют собой программные средства, поддерживающие процессы создания и/или сопровождения информационных систем, такие как: анализ и формулировка требований, проектирование баз данных и приложений, генерация кода, тестирование, обеспечение качества, управление конфигурацией и проектом.
набор СASE-средств, имеющих определенное функциональное предназначение и выполненных в рамках единого программного продукта.
методология проектирования информационных систем плюс инструментальные средства, позволяющие наглядно моделировать предметную область, анализировать ее модель на всех этапах разработки и сопровождения информационной системы и разрабатывать приложения для пользователей.
отделить проектирование программного обеспечения от его кодирования и последующих этапов разработки (тестирование, документирование и пр.), а также автоматизировать весь процесс создания программных систем, или инжиниринг (от англ. engineering - разработка).
В последнее время все чаще разработка программ начинается с некоторого предварительного варианта системы.
В качестве такого варианта может выступать специально для этого разработанный прототип, либо устаревшая и не удовлетворяющая новым требованиям система.
В последнем случае для восстановления знаний о программной системе с целью последующего их использования применяют повторную разработку - реинжиниринг.
Повторная разработка сводится к построению исходной модели программной системы путем исследования ее программных кодов. Имея модель, можно ее усовершенствовать, а затем вновь перейти к разработке. Так часто и поступают при проектировании.
Одним из наиболее известных принципов такого типа является принцип «возвратного проектирования» - Round Trip Engineering (RTE).
32
По ориентации на этапы жизненного цикла.
средства анализа
-предназначенные для построения и анализа моделей предметной области
-Design/IDEF (Meta Software) и Bpwin (Logic Works)
средства анализа и проектирования
-обеспечивающие создание проектных спецификаций
-Vantage Team Builder (Cayenne), Silverrun (Silverrun Technologies), PRO-IV (McDonnell Douglas) и CASE-Аналитик (МакроПроджект)
средства проектирования баз данных
-обеспечивающие моделирование данных и разработку схем баз данных для основных СУБД
-ERwin (Logic Works), S-Designor (SPD), DataBase Designer (ORACLE)
средства разработки приложений
-Uniface (Compuware), JAM (JYACC), PowerBuilder (Sybase), Developer/2000 (ORACLE), New Era (Informix), SQL Windows (Centura) и Delphi (Borland)
По функциональной полноте.
системы, предназначенные для решения частных задач на одном или нескольких этапах жизненного цикла
-ERwin (Logic Works), S-Designor (SPD), CASE.Аналитик (МакроПроджект) и Silverrun (Silverrun Technologies)
интегрированные системы, поддерживающие весь жизненный цикл ИС и связанные с общим репозиторием
-Vantage Team Builder (Cayenne) и система Designer/2000 с системой разработки приложений Developer/2000 (ORACLE)
По типу используемых моделей.
структурные
-основаны на методах структурного и модульного программирования, структурного анализа и синтеза
-Vantage Team Builder (Cayenne)
объектно-ориентированные
-Rational Rose (Rational Software) и Object Team (Cayenne)
комбинированные
-поддерживают одновременно структурные и объектно-ориентированные методы
-Designer/ 2000 (ORACLE)
По степени независимости от СУБД.
независимые системы
-поставляются в виде автономных систем, не входящих в состав конкретной СУБД
-поддерживают несколько форматов баз данных через интерфейс ODBC.
-S-Designor (SDP, Powersoft), ERwin (LogicWorks) и Silverrun (Computer Systems Advisers Inc.)
встроенные в СУБД
-поддерживают формат баз данных СУБД, в состав которой они входят
-возможна поддержка и других форматов баз данных
-Designer/2000, входящая в состав СУБД ORACLE
33
Полнофункциональная объектно-ориентированная система должна решать задачи анализа и моделирования, проектирования, разработки (реализации), а также иметь эффективную инфраструктуру, обеспечивающую сервисом первые три основные задачи.
Для решения задач анализа и моделирования целесообразно иметь интегрированную среду разработчика, которая должна обеспечивать возможности:
-динамического моделирования событий в системе;
-динамической и согласованной коррекции всей совокупности диаграмм;
-добавления пояснительных надписей к диаграммам моделей и в документацию;
-автоматической генерации документации;
-создания различных представлений и скрытия неиспользуемых слоев системы;
-поддержки различных нотаций (это требование ослабевает в связи с переходом к единому языку моделирования).
Осуществление процесса проектирования предполагает наличие возможностей:
-определения основной модели прикладной задачи (бизнес-модели, обычно объектно-ориентированной) и правил ее поведения (бизнес-правил);
-поддержки процесса проектирования с помощью библиотек, оснащенных средствами хранения, поиска и выбора элементов проектирования (объектов и правил);
-создания пользовательского интерфейса и поддержания распространенных программных интерфейсов (поддержка стандартов OLE, OpenDoc, доступ к библиотекам HTML/Java и т. п.);
-создания различных распределенных клиент-серверных приложений.
Средства разработки в составе CASE-системы должны обеспечивать построение приложения по результатам предыдущих этапов разработки приложения.
Максимально высоким требованием к средствам разработки можно считать генерацию готовой к выполнению программы.
Ядром инфраструктуры будущих CASE-систем должен быть репозиторий, отвечающий за генерацию кода, реинжиниринг и обеспечивающий соответствие между моделями и программными кодами.
Основу репозитория составят объектно-ориентированные БД, хотя ранее для этого использовались реляционные БД.
Другими важнейшими функциями инфраструктуры являются функции контроля версий и управления частями системы при коллективной разработке.
34
Общие сведения
Процесс оценки
Процесс выбора
Критерии оценки и выбора
Пример подхода к определению критериев выбора CASE-средств
Общие сведения Модель процесса оценки и выбора, рассматриваемая ниже (рисунок ниже), описывает наиболее общую ситуацию оценки и выбора, а также показывает зависимость между ними. Как можно видеть, оценка и выбор могут выполняться независимо друг от друга или вместе, каждый из этих процессов требует применения определенных критериев. Процесс оценки и выбора может преследовать несколько целей, включая одну или более из следующих:
оценка нескольких CASE-средств и выбор одного или более из них;
оценка одного или более CASE-средств и сохранение результатов для последующего использования;
выбор одного или более CASE-средств с использованием результатов предыдущих оценок.
|

Как видно из рисунка, входной информацией для процесса оценки является:
определение пользовательских потребностей;
цели и ограничения проекта;
данные о доступных CASE-средствах;
список критериев, используемых в процессе оценки.
Результаты оценки могут включать результаты предыдущих оценок. При этом не следует забывать, что набор критериев, использовавшихся при предыдущей оценке, должен быть совместимым с текущим набором. Конкретный вариант реализации процесса (оценка и выбор, оценка для будущего выбора или выбор, основанный на предыдущих оценках) определяется перечисленными выше целями. Элементы процесса включают:
цели, предположения и ограничения, которые могут уточняться в ходе процесса;
потребности пользователей, отражающие количественные и качественные требования пользователей к CASE-средствам;
критерии, определяющие набор параметров, в соответствии с которыми производится оценка и принятие решения о выборе;
формализованные результаты оценок одного или более средств;
рекомендуемое решение (обычно либо решение о выборе, либо дальнейшая оценка).
Процесс оценки и/или выбора может быть начат только тогда, когда лицо, группа или организация полностью определила для себя конкретные потребности и формализовала их в виде количественных и качественных требований в заданной предметной области. Термин "пользовательские требования" далее означает именно такие формализованные требования. Пользователь должен определить конкретный порядок действий и принятия решений с любыми необходимыми итерациями. Например, процесс может быть представлен в виде дерева решений с его последовательным обходом и выбором подмножеств кандидатов для более детальной оценки. Описание последовательности действий должно определять поток данных между ними. Определение списка критериев основано на пользовательских требованиях и включает:
выбор критериев для использования из приведенного далее перечня;
определение дополнительных критериев;
определение области использования каждого критерия (оценка, выбор или оба процесса);
определение одной или более метрик для каждого критерия оценки;
назначение веса каждому критерию при выборе.
Процесс оценки Целью процесса оценки является определение функциональности и качества CASE-средств для последующего выбора. Оценка выполняется в соответствии с конкретными критериями, ее результаты включают как объективные, так и субъективные данные по каждому средству. Процесс оценки включает следующие действия:
формулировка задачи оценки, включая информацию о цели и масштабах оценки;
определение критериев оценки, вытекающее из определения задачи;
определение средств-кандидатов путем просмотра списка кандидатов и анализа информации о конкретных средствах;
оценка средств-кандидатов в контексте выбранных критериев. Необходимые для этого данные могут быть получены путем анализа самих средств и их документации, опроса пользователей, работы с демо-версиями, выполнения тестовых примеров, экспериментального применения средств и анализа результатов предшествующих оценок;
подготовка отчета по результатам оценки.
Одним из важнейших критериев в процессе оценки может быть потенциальная возможность интеграции каждого из средств-кандидатов с другими средствами, уже находящимися в эксплуатации или планируемыми к использованию в данной организации. Масштаб оценки должен устанавливать требуемый уровень детализации, необходимые ресурсы и степень применимости ее результатов. Например, оценка должна выполняться для набора из одного или более конкретных CASE-средств; CASE-средств, поддерживающих один или более конкретных процессов создания и сопровождения ПО или CASE-средств, поддерживающих один или более проектов или типов проектов. Список CASE-средств - возможных кандидатов формируется из различных источников: обзоров рынка ПО, информации поставщиков, обзоров CASE-средств и других подобных публикаций. Следующим шагом является получение информации о CASE-средствах или получение их самих или и то, и другое. Эта информация может состоять из оценок независимых экспертов, сообщений и отчетов поставщиков CASE-средств, результатов демонстрации возможностей CASE-средств со стороны поставщиков и информации, полученной непосредственно от реальных пользователей. Сами CASE-средства могут быть получены путем приобретения, в виде оценочной копии или другими способами. Оценка и накопление соответствующих данных может выполняться следующими способами:
анализ CASE-средств и документации поставщика;
опрос реальных пользователей;
анализ результатов проектов, использовавших данные CASE-средства;
просмотр демонстраций и опрос демонстраторов;
выполнение тестовых примеров;
применение CASE-средств в пилотных проектах;
анализ любых доступных результатов предыдущих оценок.
Существуют как объективные, так и субъективные критерии. Результаты оценки в соответствии с конкретным критерием могут быть двоичными, находиться в некотором числовом диапазоне, представлять собой просто числовое значение или иметь какую-либо другую форму. Для объективных критериев оценка должна выполняться путем воспроизводимой процедуры, чтобы любой другой специалист, выполняющий оценку, мог получить такие же результаты. Если используются тестовые примеры, их набор должен быть заранее определен, унифицирован и документирован. По субъективным критериям CASE-средство должно оцениваться группой специалистов, использующих одни и те же критерии. Необходимый уровень опыта специалистов или групп должен быть заранее определен. Результаты оценки должны быть стандартным образом документированы (для облегчения последующего использования) и, при необходимости, утверждены. Отчет по результатам оценки должен содержать следующую информацию:
введение. Общий обзор процесса и перечень основных результатов;
предпосылки. Цель оценки и желаемые результаты, период времени, в течение которого выполнялась оценка, определение ролей и соответствующего опыта специалистов, выполнявших оценку;
подход к оценке. Описание общего подхода, включая полученные CASE-средства, информацию, определяющую контекст и масштаб оценки, а также любые предположения и ограничения;
информация о CASE-средствах. Она должна включать следующее: 1) наименование CASE-средства; 2) версию CASE-средства; 3) данные о поставщике, включая контактный адрес и телефон; 4) конфигурацию технических средств; 5) стоимостные данные; 6) описание CASE-средства, включающее поддерживаемые данным средством процессы создания и сопровождения ПО, программную среду CASE-средства (в частности, поддерживаемые языки программирования, операционные системы, совместимость с базами данных), функции CASE-средства, входные/выходные данные и область применения; этапы оценки. Конкретные действия, выполняемые в процессе оценки, должны быть описаны со степенью детализации, необходимой как для понимания масштаба и глубины оценки, так и для ее повторения при необходимости;
конкретные результаты. Результаты оценки должны быть представлены в терминах критериев оценки. В тех случаях, когда отчет охватывает целый ряд CASE-средств или результаты данной оценки будут сопоставляться с аналогичными результатами других оценок, необходимо обратить особое внимание на формат представления результатов, способствующий такому сравнению. Субъективные результаты должны быть отделены от объективных и должны сопровождаться необходимыми пояснениями;
выводы и заключения;
приложения. Формулировка задачи оценки и уточненный список критериев.
35
В структурном подходе используются в основном две группы средств, описывающих функциональную структуру системы и отношения между данными. Каждой группе средств соответствуют определенные виды моделей (диаграмм), наиболее распространенными среди которых являются:
DFD (Data Flow Diagrams) – диаграммы потоков данных;
SADT(Structured Analysis and Design Technique) – метод структурного анализа и проектирования) – модели и соответствующие функциональные диаграммы;
ERD (Entity-Relationship Diargrams) – диаграммы сущность – связь.
Диаграммы потоков данных и диаграммы сущность – связь – наиболее часто используемые в САSЕ-средствах виды моделей.
Конкретный вид перечисленных диаграмм и интерпретация их конструкций зависят от стадии жизненного цикла ПО.
На стадии формирования требований к ПО SADT-модели и DFD используются для построения модели АS-IS и модели ТО-ВЕ, отражая, таким образом, существующую и предлагаемую структуру бизнес-процессов организации и взаимодействие между ними (использование SАDT-моделей, как правило, ограничивается только данной стадией, поскольку они изначально не предназначались для проектирования ПО). С помощью ЕRD выполняется описание используемых в организации данных на концептуальном уровне, не зависимом от средств реализации базы данных (СУБД).
На стадии проектирования DFD используются для описания структуры проектируемой системы ПО, при этом они могут уточняться, расширяться и дополняться новыми конструкциями. Аналогично ЕRD уточняются и дополняются новыми конструкциями, описывающими представление данных на логическом уровне, пригодном для последующей генерации схемы базы данных. Данные модели могут дополняться диаграммами, отражающими системную архитектуру ПО, структурные схемы программ, иерархию экранных форм и меню и др. Перечисленные модели в совокупности дают полное описание ПО ЭИС независимо от того, является ли
система существующей или вновь разрабатываемой. Состав диаграмм в каждом конкретном случае
зависит от сложности системы и необходимой полноты ее описания.
36
Предшественники UML.Словарь предметной области
В словарь предметной области включаются термины, используемые специалистами, для которых разрабатывается система.
По мере работы над системой словарь предметной области может дополняться. Составлением словаря занимаются те из проектировщиков и аналитиков, кто имеет непосредственный контакт с конечными пользователями.
Диаграммы сущность-связь
Построение диаграмм сущность-связь основано на выявлении форм взаимосвязи и взаимодействия сущностей.
Метод Аббота
заключается в описании задачи на простом человеческом языке и анализе полученного текста. Существительные в этом случае принимаются как вероятны кандидаты на роль объектов-сущностей, а глаголы – на методы этих сущностей.
Метод Аббота поддается автоматизации, в частности соответствующие системы были построены Токийским технологическим институтом и фирмой Фуджи.
CRC-карточки
Аббревиатура CRC означает Class-Responsibilities-Collaborators (класс-ответственность-участники).
CRC-карточки впервые предложили Кент Бек (Kent Beck) и Уорд Каннингхэм (Ward Cunningham) для обучения объектно-ориентированному программированию.
CRC-карточки представляют собой обычные картонные карточки размером 10 на 15 сантиметров, на которых карандашом сверху пишется название класса, слева – за что он отвечает, справа – с какими классами он взаимодействует.
В ходе анализа появляются новые карточки, в старые вносятся изменения.
Может возникнуть ситуация, когда один из классов (объектов) окажется слишком большим, и на стадии реализации системы это приведет к необходимости его постоянного использования. В этом случае целесообразно разбить его на несколько классов или передать часть его функций другому классу.
Карточки раскладываются в разном порядке, что помогает определить возможные варианты наследования свойств и методов, движения потоков данных.
Метод Буча
стал основой UML.
Предложенная Бучем графическая нотация достаточно распространена и наряду с UML используется в системах автоматизации процесса разработки программного обеспечения, в частности в системе Rational Rose.
Применяемые в методе Буча обозначения несколько отличаются от обозначений, принятых в UML.
Так, класс в нотации UML представляет собой прямоугольник, в нотации Буча – облако, каким его рисуют дети, что по замыслу автора символизирует абстрактность этого понятия.
Кроме того, язык UML более формализован за счет метамодели языка.
Структура UML:
Метамодель:
описание общей структуры языка
основные понятия объектно-ориентированного проектирования:
класс
объект
событие,
ассоциация
автомат
наследование и пр.
методы расширения ядра UML
Правила построения диаграмм:
прецедентов, или вариантов использования (use case diagram);
классов (class diagram);
состояний (statechart diagram);
активности, или деятельности (activity diagram);
взаимодействия (interaction diagrams),
диаграммы последовательности (sequence diagram) и кооперации,
сотрудничества (collaboration diagram);
компонентов (component diagram);
развертывания (deployment diagram).
37
UML (англ. Unified Modeling Language — унифицированный язык моделирования) — язык графического описания для объектного моделирования в области разработки программного обеспечения. UML является языком широкого профиля, это открытый стандарт, использующий графические обозначения для создания абстрактной модели системы, называемой UML-моделью. UML был создан для определения, визуализации, проектирования и документирования в основном программных систем. UML не является языком программирования, но в средствах выполнения UML-моделей как интерпретируемого кода возможна кодогенерация.
Использование
Использование UML не ограничивается моделированием программного обеспечения. Его также используют для моделирования бизнес-процессов, системного проектирования и отображения организационных структур.
UML позволяет также разработчикам программного обеспечения достигнуть соглашения в графических обозначениях для представления общих понятий (таких как класс, компонент, обобщение (generalization), объединение (aggregation) и поведение, и больше сконцентрироваться на проектировании и архитектуре.
Диаграмма классов
Диаграмма классов (Class diagram) — статическая структурная диаграмма, описывающая структуру системы, она демонстрирует классы системы, их атрибуты, методы и зависимости между классами.
Существуют разные точки зрения на построение диаграмм классов в зависимости от целей их применения:
концептуальная точка зрения — диаграмма классов описывает модель предметной области, в ней присутствуют только классы прикладных объектов;
точка зрения спецификации — диаграмма классов применяется при проектировании информационных систем;
точка зрения реализации — диаграмма классов содержит классы, используемые непосредственно в программном коде (при использовании объектно-ориентированных языков программирования).
Диаграмма компонентов
Диаграмма компонентов (Component diagram) — статическая структурная диаграмма, показывает разбиение программной системы на структурные компоненты и связи (зависимости) между компонентами. В качестве физических компонент могут выступать файлы, библиотеки, модули, исполняемые файлы, пакеты и т. п.
Диаграмма композитной/составной структуры
Шаблон проектирования Декоратор на диаграмме кооперации
Диаграмма композитной/составной структуры (Composite structure diagram) — статическая структурная диаграмма, демонстрирует внутреннюю структуру классов и, по возможности, взаимодействие элементов (частей) внутренней структуры класса.
Подвидом диаграмм композитной структуры являются диаграммы кооперации (Collaboration diagram, введены в UML 2.0), которые показывают роли и взаимодействие классов в рамках кооперации. Кооперации удобны при моделировании шаблонов проектирования.
Диаграммы композитной структуры могут использоваться совместно с диаграммами классов.
Диаграмма развёртывания
Диаграмма развёртывания (Deployment diagram) — служит для моделирования работающих узлов (аппаратных средств, англ. node) и артефактов, развёрнутых на них. В UML 2 на узлах разворачиваются артефакты (англ. artifact), в то время как в UML 1 на узлах разворачивались компоненты. Между артефактом и логическим элементом (компонентом), который он реализует, устанавливается зависимость манифестации.
Диаграмма объектов
Диаграмма объектов (Object diagram) — демонстрирует полный или частичный снимок моделируемой системы в заданный момент времени. На диаграмме объектов отображаются экземпляры классов (объекты) системы с указанием текущих значений их атрибутов и связей между объектами.
Диаграмма пакетов
Диаграмма пакетов (Package diagram) — структурная диаграмма, основным содержанием которой являются пакеты и отношения между ними. Жёсткого разделения между разными структурными диаграммами не проводится, поэтому данное название предлагается исключительно для удобства и не имеет семантического значения (пакеты и диаграммы пакетов могут присутствовать на других структурных диаграммах). Диаграммы пакетов служат, в первую очередь, для организации элементов в группы по какому-либо признаку с целью упрощения структуры и организации работы с моделью системы.
Диаграмма деятельности
Диаграмма деятельности (Activity diagram) — диаграмма, на которой показано разложение некоторой деятельности на её составные части. Под деятельностью (англ. activity) понимается спецификация исполняемого поведения в виде координированного последовательного и параллельного выполнения подчинённых элементов — вложенных видов деятельности и отдельных действий (англ. action), соединённых между собой потоками, которые идут от выходов одного узла ко входам другого.
Диаграммы деятельности используются при моделировании бизнес-процессов, технологических процессов, последовательных и параллельных вычислений.
Диаграмма автомата
Диаграмма автомата (State Machine diagram, диаграмма конечного автомата, диаграмма состояний) — диаграмма, на которой представлен конечный автомат с простыми состояниями, переходами и композитными состояниями.
Конечный автомат (англ. State machine) — спецификация последовательности состояний, через которые проходит объект или взаимодействие в ответ на события своей жизни, а также ответные действия объекта на эти события. Конечный автомат прикреплён к исходному элементу (классу, кооперации или методу) и служит для определения поведения его экземпляров.
Диаграмма прецедентов
Диаграмма прецедентов (Use case diagram, диаграмма вариантов использования) — диаграмма, на которой отражены отношения, существующие между акторами и прецедентами.
Основная задача — представлять собой единое средство, дающее возможность заказчику, конечному пользователю и разработчику совместно обсуждать функциональность и поведение системы.
Диаграммы коммуникации и последовательности
Диаграммы коммуникации и последовательности транзитивны, выражают взаимодействие, но показывают его различными способами и с достаточной степенью точности могут быть преобразованы одна в другую.
Диаграмма коммуникации (Communication diagram, в UML 1.x — диаграмма кооперации, collaboration diagram) — диаграмма, на которой изображаются взаимодействия между частями композитной структуры или ролями кооперации. В отличие от диаграммы последовательности, на диаграмме коммуникации явно указываются отношения между элементами (объектами), а время как отдельное измерение не используется (применяются порядковые номера вызовов).
Диаграмма последовательности (Sequence diagram) — диаграмма, на которой изображено упорядоченное во времени взаимодействие объектов. В частности, на ней изображаются участвующие во взаимодействии объекты и последовательность сообщений, которыми они обмениваются.
Диаграмма сотрудничества — Этот тип диаграмм позволяет описать взаимодействия объектов, абстрагируясь от последовательности передачи сообщений. На этом типе диаграмм в компактном виде отражаются все принимаемые и передаваемые сообщения конкретного объекта и типы этих сообщений.
По причине того, что диаграммы Sequence и Collaboration являются разными взглядами на одни и те же процессы, Rational Rose позволяет создавать из Sequence диаграммы диаграмму Collaboration и наоборот, а также производит автоматическую синхронизацию этих диаграмм.
Диаграмма обзора взаимодействия
Диаграмма обзора взаимодействия (Interaction overview diagram) — разновидность диаграммы деятельности, включающая фрагменты диаграммы последовательности и конструкции потока управления.
Этот тип диаграмм включает в себя диаграммы Sequence diagram (диаграммы последовательностей действий) и Collaboration diagram (диаграммы сотрудничества). Эти диаграммы позволяют с разных точек зрения рассмотреть взаимодействие объектов в создаваемой системе.
Диаграмма синхронизации
Диаграмма синхронизации (Timing diagram) — альтернативное представление диаграммы последовательности, явным образом показывающее изменения состояния на линии жизни с заданной шкалой времени. Может быть полезна в приложениях реального времени.