

22.5.2. Проект o2
Проект O2 выполнялся французской компанией Altair, образованной специально для целей проектирования и реализации объектно-ориентированной СУБД. Начало проекта датируется сентябрем 1986 г., и он был рассчитан на пять лет: три года на прототипирование и два года на разработку промышленного образца. После успешного завершения проекта для сопровождения системы и ее дальнейшего развития была организована новая чисто коммерческая компания O2.
Прототип системы функционировал в режиме клиент/сервер в локальной сети рабочих станций SUN c соответствующим разделением функций между сервером и клиентами.
Основными компонентами системы (не считая развитого набора интерфейсных средств) являются интерпретатор запросов и подсистемы управления схемой, объектами и дисками. Управление дисками, т.е. поддержание базовой среды постоянного хранения обеспечивает система WiSS, которую разработчики O2 перенесли в окружение ОС UNIX.
Наибольшую функциональную нагрузку несет компонент управления объектами. В число функций этой подсистемы входят:
* управление сложными объектами, включая создание и уничтожение объектов, выборку объектов по именам, поддержку предопределенных методов, поддержку объектов со внутренней структурой-множеством, списком и кортежем;
* управление передачей сообщений между объектами;
* управление транзакциями;
* управление коммуникационной средой (на базе транспортных протоколов TCP/IP в локальной сети Ethernet);
* отслеживание долговременно хранимых объектов (напомним, что в O2 объект хранится во внешней памяти до тех пор, пока достижим из какого-либо долговременно хранимого объекта);
* управление буферами оперативной памяти (аналогично ORION, представление объекта в оперативной памяти отличается от его представления на диске);
* управление кластеризацией объектов во внешней памяти;
* управление индексами.
Несколько слов про управление транзакциями. Различаются режимы, когда допускается параллельное выполнение транзакций, изменяющих схему БД, и когда параллельно выполняются только транзакции, изменяющие внутренность БД. Первый режим обычно используется на стадии разработки БД, второй - на стадии выполнения приложений. Средства восстановления БД после сбоев и откатов транзакций также могут включаться и выключаться. Наконец, поддерживается режим, при котором все постоянно хранимые объекты загружаются в оперативную память при начале транзакции для увеличения скорости работы прикладной системы.
Компонент управления схемой БД реализован над подсистемой управления объектами: в системе поддерживаются несколько невидимых для программистов классов и в том числе классы "Class" и "Method", экземплярами которых являются, соответственно, объекты, определяющие классы, и объекты, определяющие методы. (Как видно, ситуация напоминает реляционные системы, в которых тоже обычно поддерживаются служебные отношения-каталоги, описывающие схему БД.) Удаление класса, который не является листом иерархии классов или используется в другом классе или сигнатуре какого-либо метода, запрещено.
Даже приведенное краткое описание особенностей двух объектно-ориентированных СУБД показывает прагматичность современного подхода к организации таких систем. Их разработчики не стремятся к полному соблюдению чистоты объектно-ориентированного подхода и применяют наиболее простые решения проблем. Пока в сообществе разработчиков объектно-ориентированных систем БД не видно работы, которая могла бы сыграть в этом направлении роль, аналогичную роли System R по отношению к реляционным системам. Правда и проблемы ООБД гораздо более сложны, чем решаемые в реляционных системах.
66
Большинство современных СУБД рассчитаны на многоплатформенную архитектуру, то есть они могут работать на компьютерах с разной архитектурой и под разными операционными системами, при этом для пользователей доступ к данным, управляемым СУБД, на разных платформах практически неразличим.
Многоплатформенные системы позволяют использовать СУБД (Системы Управления Базами Данных) различных разработчиков (Microsoft, Oracle, IBM и др.), что дает дополнительную гибкость предприятиям в части инвестирования в инфраструктуру и персонал при заданной целевой производительности ERP-системы.
Прошедшее десятилетие ознаменовалось решительным поворотом в области баз данных в сторону профессиональных многопользовательских СУБД. Эпоха настольных СУБД на платформе персональных компьютеров, таких как FoxBase, FoxPro, Paradox, Clipper, dBase, Clarion, MSAccess и т.д., не поддерживающих значительное число функций управления базами данных, ушла в прошлое. В настоящее время большинство средних и крупных организаций постепенно переходят к созданию действительно открытых и распределенных информационных систем на мощной компьютерной платформе и с использованием СУБД более высокого класса. Это - многопользовательские многоплатформные профессиональные СУБД, которые изначально были ориентированы на решение сложных технологических проблем. К числу таких многопользовательских СУБД относятся широко известные коммерческие системы управления базами данных:
* Oracle фирмы Oracle Corp.;
* Informix и DB2 фирмы IBM;
* MS SQL Server фирмы Microsoft;
* Sybase фирмы Sybase Inc.,
а также целый ряд некоммерческих свободно распространяемых СУБД.
многплформные СУБД, такие субд, которые можно запускать на рызных системах, что очень удобно, от того что у разных организаций - разные платформы...
67
Определение и характеристики распределенных систем баз данных
"Ядром" системы управления распределенными информационными ресурсами являются распределенная база данных (РаБД) и система управления распределенной базой данных (РаСУБД). Поэтому определим сначала эти понятия.
Распределенная база данных - это совокупность логически взаимосвязанных баз данных, распределенных в компьютерной сети1. Система управления распределенной базой данных - это программная система, которая обеспечивает управление распределенной базой данных и прозрачность ее распределенное™ для пользователей2. Эти определения можно дополнить, если рассмотреть также различные характеристики РаБД и РаСУБД. В 1987 г. К. Дейт опубликовал свои правила для распределенных баз данных3. Ниже приведены эти 12 правил*.
* К сожалению, автор не приводит точной библиографической ссылки на цитируемую работу К. Дейта. Эти правила были сформулированы К. Дейтом в его статье "What IsDistributed Database System?", опубликованной в сборнике C.D.Date, Relational Database Writings 1985-1989. Reading, Mass.: Addison-Wesley (1990). К. Дейт цитирует ключевые моменты этой работы в шестом издании своей знаменитой хрестоматии "An Introduction to Database Systems . — 6th ed. Addison-Wesley Publishing Company, 1995. - P. 596-597. - Прим. ред.
1. Локальная автономность. Локальные данные должны находиться под локальным владением и управлением, включая функции безопасности, целостности, представления данных в памяти. Исключением может быть ситуация, когда ограничения целостности охватывают данные нескольких узлов или когда управление распределенной транзакцией осуществляется некоторым внешним узлом.
2. Никакой конкретный сервис не должен возлагаться на какой-либо специально выделенный центральный узел. Соблюдение этого правила, т.е. принципа децентрализованное™ функций РаСУБД, позволяет избежать узких мест.
3. Непрерывность функционирования. Система не должна останавливаться в случае необходимости добавления нового узла или удаления в распределенной среде некоторых данных, изменения определения метаданных и даже (что довольно сложно) осуществления перехода к новой версии СУБД на отдельном узле.
4. Независимость от местоположения. Пользователи и приложения не обязаны знать о том, где физически располагаются данные.
5. Независимость от фрагментации. Фрагменты (называемые также разделами) данных должны поддерживаться и обрабатываться средствами РаСУБД таким образом, чтобы пользователи или приложения могли бы вообще ничего не знать об этом. Более того, РаСУБД должна уметь обходить при обработке запросов фрагменты, не имеющие к ним отношения (например, РаСУБД должна быть достаточно интеллектуальной, для того чтобы определять, можно ли исключить при обработке запроса тот или иной фрагмент в силу того, что запрос не содержит ссылок на хранящиеся в этом фрагменте столбцы).
6. Независимость от тиражирования. Те же принципы независимости и прозрачности относятся и к механизму тиражирования, который обсуждается ниже.
7. Распределенная обработка запросов. Обработка запросов должна производиться распределенным образом. В следующем разделе мы рассмотрим некоторые архитектурные принципы реализации РаСУБД и различные модели, в рамках которых возможна распределенная обработка запросов.
8. Управление распределенными транзакциями. На распределенные базы данных необходимо распространить механизмы управления транзакциями и управления одновременным доступом. Эта проблема включает выявление и разрешение тупиковых ситуаций, прерывания по истечении временных интервалов, фиксацию и откат распределенных транзакций, а также ряд других вопросов.
9. Независимость от оборудования. Одно и то же программное обеспечение РаСУБД должно выполняться на различных аппаратных платформах и функционировать в системе в качестве равноправного партнера. Как уже обсуждалось выше, на практике достичь этого исключительно сложно, поскольку многие поставщики поддерживают множество платформ. Это ограничение преодолевается с помощью модели многопродуктовых сред.
10. Независимость от операционных систем. Эта проблема тесно связана с предыдущей, и она также решается аналогичным образом.
11. Независимость от сети. Узлы могут быть связаны между собой с помощью множества разнообразных сетевых и коммуникационных средств. Многоуровневая модель, присущая многим современным информационным системам (например, семиуровневая модель OSI, модель TCP/IP, уровни SNA и DECnet), обеспечивает решение этой проблемы не только в среде РаБД, но и для информационных систем вообще.
12. Независимость от СУБД. Локальные СУБД должны иметь возможность участвовать в функционировании РаСУБД.
Очевидно, что, хотя крайне желательно было бы иметь системы, удовлетворяющие всем 12 правилам, нереально ожидать реализации этих требований в рамках хотя бы одного продукта даже в ближайшие годы. И действительно, за время, прошедшее с момента опубликования правил Дейта, эта цель так и не была достигнута.
Отчасти по этой причине поставщики, ориентирующиеся на рынок распределенных баз данных, придерживаются многоэтапного подхода к внедрению средств распределения в свои продукты. Одним из наиболее известных предложений в этой области является выдвинутая в 1989 г. компанией IBM программа, где определены четыре шага, необходимых для перехода к управлению распределенными базами данных и призванных обеспечить следующие возможности4:
1. Удаленный запрос. Эта парадигма эквивалентна базовой модели удаленного доступа. Выполняется подключение к удаленному узлу и производится чтение или изменение данных на этом узле. Результат поступает на исходный узел, после чего транзакция завершается. Практически любая коммерческая СУБД в настоящее время поддерживает удаленные запросы, и такая возможность предоставляется уже в течение некоторого времени.
2. Удаленная единица работы. Это означает, что на удаленном узле можно выполнить группу запросов как атомарную единицу (транзакцию). Приложение, вообще говоря, может получать и модифицировать данные многих узлов, но каждая транзакция затрагивает данные только одного узла. i
3. Распределённая единица работы при этом каждый запрос относится только к одному узлу, но запросы, составляющие распределенную единицу работы (транзакцию), могут выполняться совместно на нескольких узлах. Вся группа запросов при этом фиксируется или откатывается как одно целое.
4. Распределенный запрос. Этот шаг предусматривает возможность выполнения запросов, охватывающих множество баз данных на разных узлах. Несколько таких распределенных запросов может быть далее сгруппировано в качестве транзакции.
Как будет показано в следующем разделе, возможности последнего из четырех шагов - распределенных запросов - могут быть существенно расширены в отношениираспределенности и неоднородности.
Методы построения распределенных баз данных "сверху вниз" и "снизу вверх"
Рассмотрим сначала процесс построения распределенных баз данных методом "сверху вниз", поскольку он концептуально наиболее прост для понимания. Проектирование РаБД"сверху вниз" осуществляется в целом аналогично проектированию централизованных баз данных. В идеале оно проводится с помощью одной из формальных методологий, которые включают создание концептуальной модели базы данных, отображение ее в логическую модель данных и, наконец, создание (и настройку) специфических для конкретной СУБД структур (например, таблиц базы данных системы Rdb/VMS).
Однако при проектировании РаБД методом "сверху вниз" предполагается, что ее объекты не будут сосредоточены в одном месте, а распределятся по нескольким вычислительным системам (рис. 67). Распределение проводится путем фрагментации или тиражирования.
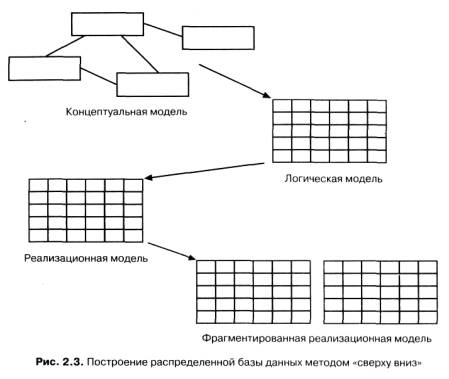
Фрагментация означает декомпозицию объектов базы данных, таких, как реляционные таблицы, на две или более частей, которые размещаются на разных компьютерных системах. Классический пример, который обычно используют для иллюстрации этого понятия, - таблица с данными о сотрудниках или о заказах на продажу, разделенная на фрагменты по географическому или другому характеристическому признаку.
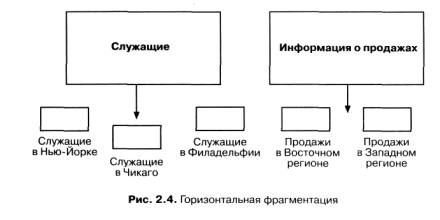
На рис. 67-1 показана горизонтальная фрагментация, когда в таблице делаются горизонтальные "срезы" в соответствии со значением, скажем, какого-либо столбца таблицы. Строки данных о сотрудниках могут разбиваться на подмножества, соответствующие филиалам. Данные о продажах фрагментируются по магазинам, где эти продажи производилисьФрагментация может осуществляться также по принципу "карусели" (round-robin), а не на основе значений данных.
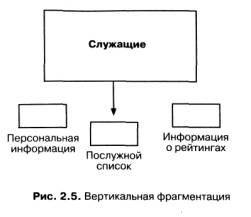
Альтернативная модель фрагментации - вертикальная - означает разбиение таблицы не по строкам, а по столбцам (рис 67-2). В этом случае некоторая часть информации о каждом сотруднике хранится в одном месте, а другая часть (относящаяся к той же таблице) - в другом.
Независимо от того, применяется горизонтальная или вертикальная фрагментация, поддерживается глобальная схема, позволяющая воссоздать из имеющихся фрагментов логически централизованную таблицу или другую структуру базы данных.
Прежде чем перейти к обсуждению тиражирования, обратимся к практическим аспектам применения фрагментации в реальных базах данных.
68
Объектно-реляционная СУБД
Объектно-реляционная СУБД (ОРСУБД) — реляционная СУБД (РСУБД), поддерживающая некоторые технологии, реализующие объектно-ориентированный подход.
Разница между объектно-реляционными и объектными СУБД: первые являют собой надстройку над реляционной схемой, вторые же изначально объектно-ориентированы. Главная особенность и отличие объектно-реляционных, как и объектных, СУБД от реляционных заключается в том, что О(Р)СУБД интегрированы с Объектно-Ориентированным (OO) языком программирования, внутренним или внешним как C++, Java. Характерные свойства OРСУБД - 1) комплексные данные, 2) наследование типа, и 3) объектное поведение.
Комплексные данные могут быть реализованы через постоянно-хранимые объекты (persistent objects). Создание комплексных данных в большинстве существующих ОРСУБД основано на предварительном определении схемы через определяемый пользователем тип (UDT - user-defined type). Используются также встроенные конструкторы составных типов, например массив (ARRAY).
Иерархия структурных комплексных данных предлагает дополнительное свойство, наследование типа. То есть структурный тип может иметь подтипы, которые используют все его атрибуты и содержат дополнительные атрибуты, специфицированные в подтипе.
Объектное поведение закладывается через описание программных объектов. Такие объекты должны быть сохраняемыми и переносимыми для обработки в базе данных, поэтому они называются обычно как постоянные (или долговременные) объекты. Внутри базы данных все отношения с постоянным программным объектом есть отношения с его объектным идентификатором (OID).
Объектно-реляционными СУБД являются, к примеру, широко известные Oracle Database, PostgreSQL, а также Cache, Sav Zigzag, IBM Cloudscape, FirstSQL/J и другие.
69
Подключение систем управления реляционными базами данных к World Wide Web - эта задача, некогда казавшаяся невыполнимой, становится все более и более реальной, хотя и по-прежнему нелегкой.
Многие ведущие производители серверов СУБД стремятся "упаковать" свои продукты в Web-"обертку": разрабатывается программное обеспечение промежуточного уровня (middleware), позволяющее заметно улучшить взаимодействие серверов СУБД с Web. При этом в выигрышном положении оказываются две группы пользователей.
Во-первых, это Web-мастера, которым может прийтись по душе идея использовать СУБД для хранения содержимого Web-узла. Перенос СУБД на Web означает, что пользователь получает возможность отказаться от работы со статическими Web-страницами и начать создавать их в динамическом режиме, "вытаскивая" данные из различных записей в базе данных с помощью промежуточного программного обеспечения.
Во-вторых, это персонал корпоративных информационных систем, который получает возможность отделаться от работы в не слишком удобной и дорогой архитектуре клиент-сервер и перейти к использованию более простых и экономичных решений на основе Web-технологий в среде интрасетей.
Большая выгода от использования Web-технологий при работе с базами данных состоит в том, что при этом исчезает необходимость написания и сопровождения большого числа клиентских приложений, используемых в качестве внешних интерфейсов. Эти приложения отвечают за выполнение целого ряда задач - от выдачи предварительно отформатированной информации на экран до генерации SQL-запросов. Каждый раз, когда во внешний интерфейс вносятся изменения, приходится заботиться о том, чтобы поставить новые версии программы на все клиентские машины.
Web-технологии позволяют создавать HTML-страницы, обеспечивающие выдачу информации на экран, и передать все функции обработки данных Web-браузеру, который, в свою очередь, обращается к СУБД. Это означает, что для изменения формата экрана не надо рассылать всем пользователям новые версии внешнего интерфейса - достаточно просто отредактировать HTML-страницу. Можно централизованно вносить изменения в Web-сценарии доступа к СУБД, ничего не меняя на браузере. Кроме того, применение Web-технологий в качестве внешнего интерфейса СУБД позволяет использовать сетевые компьютеры (часто называемые "тонкими" клиентами), на которых устанавливается только браузер и сетевое ПО для доступа к Web-серверам.
Справедливости ради надо сказать, что все производители пытаются постепенно улучшать свои продукты, однако их попытки меркнут по сравнению с усилиями по переносу Web-технологий на серверы СУБД.
Все крупнейшие производители реляционных СУБД - IBM, Informix, Microsoft, Oracle и Syba-se - аннонсировали промежуточное ПО для обмена данными с СУБД при помощи Web-технологий.
Прочие усовершенствования основных серверов СУБД
Помимо обеспечения поддержки Web-технологий, производители СУБД вносят и другие усовершенствования в свои продукты. Ниже приводится список наиболее важных усовершенствований.
· В SQL Server 11 for Windows NT компании Sybase появилось новое средство Logical Memory Manager, обеспечивающее поддержку онлайновой обработки транзакций и поддержку принятия решений в реальном времени. С помощью этого средства в оперативной памяти можно создавать неограниченное число именованных внутренних буферов; эти буфера связываются с определенными таблицами и обеспечивают ускорение доступа к данным.
· SQL Server 6.5 компании Microsoft предоставляет расширенные средства интеграции с серверами других СУБД; в частности, обеспечивается тиражирование данных на любом ODBC-сервере базы данных, например DB2 (IBM), Oracle7 (Oracle Corp.) и продуктах Sybase.
· Компания Informix Software наконец завершила слияние с Illustra Information Technologies, в результате чего Informix заполучила ряд важных технологий для объектно-ориентированных СУБД. Informix также выпустила новую серию продуктов под названием MetaCube Product Family. Эти продукты предназначены для онлайновой аналитической обработки связей, они обеспечивают быструю выборку данных (slice and dice) в системах принятия решений.
· Windows NT Server быстро набирает очки в соревновании сетевых операционных систем, вытесняя как NetWare компании Novell, так и OS/2 Warp Server корпорации IBM в качестве платформы для СУБД младшего класса. Ряд производителей, известных как поставщики продуктов для Unix - и в их числе Informix, - выпустил новые версии своих продуктов для Windows NT раньше, чем их Unix-аналоги. Если эта тенденция сохранится, то WIndows NT Server еще до конца текущего столетия может вытеснить Unix с занимаемого этой системой места наиболее предпочтительной операционной системы для СУБД. Windows NT вторгается также и на рынки других стран, в частности Японии, где национальные производители аппаратного обеспечения практически не выпускают продукты для Unix
В список рекомендаций Network World входят продукты, которые мы советуем вам рассмотреть при планировании закупки ПО сервера реляционной СУБД. Компании, упомянутые в этом списке, предоставляют существенную поддержку Web-технологий и предлагают широкий набор основных функций СУБД, которые могут удовлетворить запросы пользователей сети предприятия. Однако этот список не является универсальной рекомендацией.
Недавнее приобретение компании Illustra Information Techhologies заметно продвинуло Informix Software к интеграции объектно-ориентированной технологии с СУБД. Партнерство с Netscape Communications усилило позиции Informix на рынке Internet. Впрочем, нельзя не отметить, что продукт этой компании OnLine Dynamic Server 7.0 и раньше обеспечивал поддержку Web-приложений, порождающих интенсивный трафик. Это достигалось использованием серверов с параллельной обработкой, поддерживавших осуществление запросов и выполнение транзакций в параллельном режиме. Поэтому Informix можно также отнести к числу сильных поставщиков приложений для хранилищ данных, требующих больших объемов машинного счета. Большую роль в будущем продукте Informix под названием Universal Server призваны сыграть и DataBlades - объектные модули, в которых инкапсулированы все функции и процедуры индексации, необходимые для работы с новыми типами данных. Объединение продуктов Informix и Illustra в Universal Server позволит обеспечить поддержку приложений на базе Web.
Поддержка Windows NT растет, и это значительно расширяет область применения продукта SQL Server 6.5 компании Microsoft. Семейство продуктов компании Microsoft, в которое теперь входят четвертая версия NT и версия 6.5 SQL Server, достигло, наконец, такого уровня, который необходим для удовлетворения запросов пользователей масштаба предприятия. SQL Server - одна из наиболее простых в использовании СУБД. Этот факт, а также сильная поддержка драйверов и приложений сторонних фирм заметно укрепили положение продуктов, работающих под Windows NT. Цены на продукты держатся на потребительском уровне, и это обеспечивает такое соотношение цены и производительности, которое соответствует запросам пользователей компьютеров на базе Intel. С появлением в недалеком будущем кластеризации в NT SQL сможет составить серьезную конкуренцию Unix-системам.
Oracle остается королем в области серверов СУБД. Его продукт Oracle Server 7.3 немало способствовал тому, что годовой объем продаж компании достиг миллиарда долларов. Компания обеспечивает самый высокий уровень поддержки продуктов сторонних компаний и работы в многоплатформенном режиме. Она предлагает полное решение большинства проблем в области СУБД и интрасетей с использованием полного набора средств в диапазоне от уровня клиент-браузер до уровня приложение-сервер. (Однако тем, кто раньше с Oracle не работал, первое знакомство будет стоить серьезных усилий на обучение и больших денег.) Кроме того, Oracle обеспечивает хорошую поддержку параллельной обработки.
Sybase недавно приобрела компанию PowerSoft, которой принадлежали права на технологию баз данных Watcom. В результате у Sybase сейчас имеется разнообразный набор продуктов - от семейства SQL Anywhere до SQL Server. В результате пользователи получили широкий выбор систем разного масштаба - предназначенных как для индивидуального пользователя, отдела предприятия, так и для очень больших баз данных. Продукты web.sql и NetImpact Dynamo обеспечивают разработчикам приложений под Sybase широкий набор средств для персональной настройки публикаций в интрасетях при минимуме программистских усилий. Для этого используются операторы SQL и Perl, встроенные в страницы HTML.
70
Хранилище данных
Хранилище данных (англ. Data Warehouse) — очень большая предметно-ориентированная информационная корпоративная база данных, специально разработанная и предназначенная для подготовки отчётов, анализа бизнес-процессов с целью поддержки принятия решений в организации. Строится на базе клиент-серверной архитектуры, реляционной СУБД и утилит поддержки принятия решений. Данные, поступающие в хранилище данных, становятся доступны только для чтения. Данные из промышленной OLTP-системы копируются в хранилище данных таким образом, чтобы построение отчётов и OLAP-анализ не использовал ресурсы промышленной системы и не нарушал её стабильность. Данные загружаются в хранилище с определённой периодичностью, поэтому актуальность данных несколько отстает от OLTP-системы.
Принципы организации хранилища
1. Проблемно-предметная ориентация. Данные объединяются в категории и хранятся в соответствии с областями, которые они описывают, а не с приложениями, которые они используют.
2. Интегрированность. Данные объединены так, чтобы они удовлетворяли всем требованиям предприятия в целом, а не единственной функции бизнеса.
3. Некорректируемость. Данные в хранилище данных не создаются: т.е. поступают из внешних источников, не корректируются и не удаляются.
4. Зависимость от времени. Данные в хранилище точны и корректны только в том случае, когда они привязаны к некоторому промежутку или моменту времени
Дизайн хранилищ данных
Существуют два архитектурных направления – нормализованные хранилища данных и размерностные хранилища.
В нормализованных хранилищах, данные находятся в предметно ориентированных таблицах третьей нормальной формы – витрины данных. Нормализованные хранилища характеризуются как простые в создании и управлении, недостатки нормализованных хранилищ – большое количество таблиц как следствие нормализации, из-за чего для получения какой-либо информации нужно делать выборку из многих таблиц одновременно, что приводит к ухудшению производительности системы.
Размерностные хранилища используют схему "звезда" или "снежинка". При этом в центре звезды находятся данные (Таблица фактов), а размерности образуют лучи звезды. Различные таблицы фактов совместно используют таблицы размерностей, что значительно облегчает операции объединения данных из нескольких предметных таблиц фактов (Пример – факты продаж и поставок товара). Таблицы данных и соответствующие размерности образуют архитектуру "ШИНА". Размерности часто создаются в третьей нормальной форме (медленно изменяющиеся размерности), для протоколирования изменения в размерностях. Основным достоинством размерностных хранилищ является простота и понятность для разработчиков и пользователей, также, благодаря более эффективному хранению данных и формализованным размерностям, облегчается и ускоряется доступ к данным, особенно при сложных анализах. Основным недостатком является более сложные процедуры подготовки и загрузки данных, а также управление и изменение размерностей данных.
Процессы работы с данными
Источниками данных могут быть:
1. Традиционные системы регистрации операций (БД)
2. Отдельные документы
3. Наборы данных
Источники данных классифицируются:
1. Территориальное и административное размещение.
2. Степень достоверности.
3. Частота обновляемости.
4. Система хранения и управления данными.
Операции с данными:
1. Извлечение – перемещение информации от источников данных в отдельную БД, приведение их к единому формату.
2. Преобразование – подготовка информации к хранению в оптимальной форме для реализации запроса, необходимого для принятия решений.
3. Загрузка – помещение данных в хранилище, производится атомарно, путем добавления новых фактов или корректировкой существующих.
4. Анализ – OLAP, Data Mining, Reporting и т. д.
5. Представление результатов анализа.
Вся эта информация используется в словаре метаданных. В словарь метаданных автоматически включаются словари источников данных. Здесь же форматы данных для их последующего согласования, периодичность пополнения данных, согласованность во времени.
Задача словаря метаданных состоит в том, чтобы освободить разработчика от необходимости стандартизировать источники данных.
Создание хранилищ данных не должно противоречить действующим системам сбора и обработки информации.
Специальные компоненты словарей должны обеспечивать своевременное извлечение из словарей и обеспечить преобразование к единому формату на основе словаря метаданных.
Логическая структура данных хранилища данных отличается от структуры данных источников данных.
Для разработки эффективного процесса преобразования необходима хорошо проработанная модель корпоративных данных и модель технологии принятия решений.
Данные для пользователя удобно представлять в многоразмерных БД, где в качестве размерности могут выступать время, цена или географический регион.
Кроме извлечения данных из БД, принятия решений важен процесс извлечения знаний, в соответствии с информационными потребностями пользователя.
С точки зрения пользователя в процессе извлечения знаний из БД должны решаться след. преобразования: данные > информация > знания > полученные решения
71
Компоненты для работы с БД
Для работы с базами в Delphi есть несколько наборов компонентов. Каждый набор очень хорошо подходит для решения определенного круга задач. Все они используют разные технологии доступа к данным и отличаются по возможностям. Помимо этого есть группы, которые могут использоваться в любом случае.
На закладке "Data Access" расположены основные компоненты доступа к данным. Эти компоненты общие для всех и могут использоваться совместно с другими группами компонентов:
На закладке "Data Controls" расположены компоненты для отображения и редактирования данных в таблицах. Эти компоненты так же используются в не зависимости от используемой технологии доступа к данным:
Закладка "BDE" содержит компоненты, позволяющие получить доступ к базам данных по технологии, разработанной фирмой Borland под названием Borland Database Engine. Эта технология сильно устарела и поставляется только для совместимости со старыми версиями. Не смотря на это, она хорошо работает со старыми типами данных, такими как Paradox и dBase:
dbExpress - это новая технология доступа к данным фирмы Borland. Она отличается большой гибкостью и хорошо подходит для программирования клиент-серверных приложений, использующих базы данных:
ADO [Active Data Objects] - технология доступа к данным, разработанная корпорацией Microsoft. Рекомендуется использовать для работы с базами данных Microsoft, а именно MS Access или MS SQL Server:
Далее рассмотрены лишь некоторые компоненты, которые предоставляют нам ранее рассмотренные технологии.