

Архитектурные особенности построения пэвм. 25
О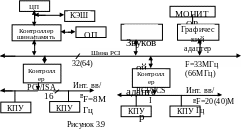 бъединение
устройств в первых персональных
компьютерах (РС) осуществлялось на
основе единого интерфейса – общей шины.
В РС типа АТ на основе процессора i80286
в качестве общей шины использовался
интерфейс ISA
– интерфейс стандартной архитектуры.
Все устройства компьютера. - ЦП, блоки
памяти, контроллеры ПУ, содержащие порты
ввода-вывода, подключаются к ISA
как к системному интерфейсу.
бъединение
устройств в первых персональных
компьютерах (РС) осуществлялось на
основе единого интерфейса – общей шины.
В РС типа АТ на основе процессора i80286
в качестве общей шины использовался
интерфейс ISA
– интерфейс стандартной архитектуры.
Все устройства компьютера. - ЦП, блоки
памяти, контроллеры ПУ, содержащие порты
ввода-вывода, подключаются к ISA
как к системному интерфейсу.
Состав его основных цепей: 16-разрядная шина данных, 24-разрядная шина адреса, 4-разрядная шина управления, состоящая из цепей MR, MW, IOR, IOW, а также цепи запросов прерываний IRQ0, …, IRQ15 и запросов прямого доступа к памяти DACK0, …, DACK7. Тактовая частота 8МГц, пропускная способность 16 МВ/с. Тип обмена – асинхронный, принцип обмена – «ведущий – ведомый». Ведущее устройство, захватив интерфейс, управляет обменом с ведомым устройством, выставляя адрес ячейки памяти или порта ввода-вывода на ША и сигналы управления в цепи MR или WR, IOR или IOW, по которым обеспечивается чтение или запись ячейки или порта.
Тактовая частота процессоров скоро превысила 8 МГц и шина ISA стала «узким» местом компьютера, ограничивающим его производительность. Кроме того, адресное пространство в 16 МВ также стало ограничивающим фактором. Поэтому с целью увеличения адресного пространства и пропускной способности был разработан (также фирмой IBM) расширенный (Extended) интерфейс EISA. В нем ША и ШД увеличены до 32 цепей. В результате адресное пространство выросло до 4 ГВ, а пропускная способность – до 32 МВ/с, тактовая частота осталась прежней. Пропускная способность выросла незначительно и осталась фактором, ограничивающим производительность ЭВМ.
С целью разрешения этой проблемы было принято следующее решение. В состав ЭВМ ввели дополнительный интерфейс – локальную шину - с высокой пропускной способностью, который стали использовать для подключения устройств, требующих высокой скорости обмена. В результате получилась структура с двумя шинами (рисунок 3.9), в которой в качестве локальной шины используется интерфейс PCI.
Современные ПЭВМ типа Pentium, как правило, содержат не менее двух интерфейсов: наряду с интерфейсами ISA (EISA) в состав ВК вводится другой интерфейс с более высокой пропускной способностью – локальная шина типа PCI, например. Структура ВК при этом усложняется, производительность возрастает (рисунок 3.9). Пропускная способность локальной шины PCI больше пропускной способности интерфейса ISA
.
Интерфейс PCI –
Peripheral Component
Interconnect – шина для соединения
периферийных (по отношению к ЦП)
компонентов. Обмен по шине PCI
осуществляется по принципу «ведущий»
(Initiator, Master)
и «ведомый» (Target, Slave).
Тип обмена - асинхронный (с квитированием),
режим обмена – пакетный. Размер пакета
– от одной порции данных и выше. Обмен
задается в виде транзакций. Каждая
транзакция начинается фазой (циклом)
адреса (рисунок 3.10). За ней может следовать
одна или несколько фаз (циклов) данных.
Для передачи адреса и данных используется
мультиплексированная шина адреса данных
AD (32 или 64 разряда). Начало
обмена (транзакции) задается сигналом
FRAME – к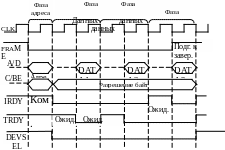 адр
обмена, который вырабатывает ведущее
устройство (Initiator). Оно же
выставляет на шину AD адрес
ведомого устройства, а на шину управления
С/ВЕ (Command/Byte
Enable) команду, несущую
информацию о типе транзакции и направлении
обмена. Адресуемое устройство, опознав
адрес как собственный, отзывается
сигналом DEVSEL (Device
Select) – устройство выбрано.
После этого инициатор может выставить
свой сигнал готовности к обмену IRDY.
Когда к обмену будет готово ведомое
устройство, оно установит свой сигнал
готовности TRDY. Одновременная
готовность ведущего и ведомого запускает
цикл обмена порцией данных по шине АD.
Отсутствие сигнала готовности фактически
вводит такты ожидания. С их помощью
устройства согласуют свои скорости.
Если быстродействие устройств позволяет,
то будет обеспечена максимальная
пропускная способность 32/64 бита за такт
(не считая такта адресации).
адр
обмена, который вырабатывает ведущее
устройство (Initiator). Оно же
выставляет на шину AD адрес
ведомого устройства, а на шину управления
С/ВЕ (Command/Byte
Enable) команду, несущую
информацию о типе транзакции и направлении
обмена. Адресуемое устройство, опознав
адрес как собственный, отзывается
сигналом DEVSEL (Device
Select) – устройство выбрано.
После этого инициатор может выставить
свой сигнал готовности к обмену IRDY.
Когда к обмену будет готово ведомое
устройство, оно установит свой сигнал
готовности TRDY. Одновременная
готовность ведущего и ведомого запускает
цикл обмена порцией данных по шине АD.
Отсутствие сигнала готовности фактически
вводит такты ожидания. С их помощью
устройства согласуют свои скорости.
Если быстродействие устройств позволяет,
то будет обеспечена максимальная
пропускная способность 32/64 бита за такт
(не считая такта адресации).
Рисунок 3.10
Следует отметить, что количество порций данных в пакете заранее не определено. Перед последней порцией инициатор снимает сигнал FRAME, тем самым сообщает ведомому устройству о завершении обмена. Затем, после обмена последней порцией данных, инициатор снимает сигнал готовности IRDY и шина переходит в состояние покоя – оба сигнала FRAME и IRDY находятся в пассивном состоянии.
Завершение транзакции, т.е. процесса передачи пакета данных, может закончиться: 1) нормально (как описано выше), 2) по тайм-ауту (когда закончиться отведенное на транзакцию количество тактов), 3) аварийно (транзакция отвергается, если в течении заданного времени не получен ответ DEVSEL от адресуемого устройства), 4) по сигналу STOP от ведомого устройства.
Транзакции инициируются по запросам от инициаторов. Инициаторы выставляют запросы на захват шины в цепь REQ. Арбитраж запросов выполняет арбитр, который входит в состав чипсета системной платы. В ответ на запрос REQ арбитр выбирает устройство с наивысшим в данный момент времени приоритетом, посылая ответный сигнал GNT (Grant) в цепь GNT.
Направление обмена по шине AD задается в адресной фазе путем передачи по шине C/BE четырехбитовой команды, которая и указывает направление обмена. Типичные команды PCI:
-чтение памяти (MR – Memory Read) – код команды 0110,
-запись памяти (MW – Memory Write) – код команды 0111,
-чтение порта ввода-вывода (I/OR) - код команды 0010,
-запись порта ввода-вывода (I/OW) - код команды 0011.
Обмен информацией между устройствами, подключенными к разным интерфейсам (рисунок 3.9), осуществляется через контроллеры (мосты): PCI/ISA, PCI/SCSI, которые входят в состав чипсет большинства системных плат.
Характеристики PCI: частота 33 МГц, однако версия 2.1 допускает работу и на частоте 66 МГц – при согласии всех абонентов шины. Разрядность шины AD – 32 (64), отсюда пропускная способность от 132 до 528 МВ/с. Кроме того, PCI ориентирован на технологию PnP – подключай и работай, т.е. поддерживает режим автоконфигурирования устройств.
Многопроцессорный вычислительный комплекс «Эльбрус» 27
Класс больших машин характеризовался двумя видами: семейство ЕС и машинами БЭСМ. Как первые, так и вторые с ростом интеграции постепенно устарели, однако необходимость в замене машин серии БЭСМ привела к разработке нового устройства программно совместимого с серией БЭСМ — «Эльбрус». Многопроцессорные вычислительные комплексы семейства «Эльбрус» отличаются числом процессоров, их быстродействием, элементной базой и производительностью. Так «Эльбрус-1»: производительность до 12 млн. коротких операций, «Эльбрус-2» до 200 млн. коротких операций. Система допускает объединение как универсальных, так и специализированных процессоров вместе с модулями памяти и устройствами ввода-вывода. Главной отличительной особенностью систем «Эльбрус» является использование вместо шинной связи специальных коммутаторов — быстродействующих коммутаторов межмодульной связи. Коммутатор имеет матричную двух- или трехмерную организацию. В узлах матрицы быстродействующие ключи. Причем соединение между модулями в системе сохраняется на все время передачи сигнала. Поскольку матрица имеет множество строк/столбцов, то возможна одновременная связь между различными функциональными модулями вычислителя. Сам коммутатор не порождает конфликты в системе (в отличие от шины когда она занята). Конфликт с такой организацией может возникнуть если будет запрос на обслуживание двух устройств одновременно, однако программно его можно исключить. Главное требование к матричному коммутатору — задержка в нем должна быть минимальная, отсюда элементная база ЭСЛ. Коммутатор реализует пространственное разделение сигналов в отличие от временного, как в шине.
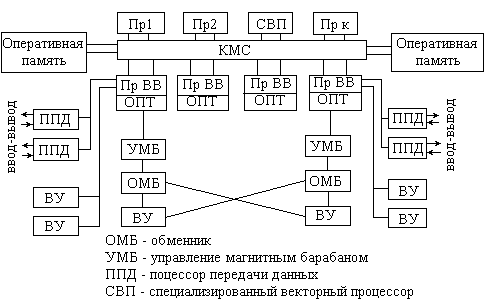 Коммутатор
межмодульных связей (КМС) может
устанавливать линии связи с каждым из
10 центральных процессоров. Память
разбита на 2 страницы каждая по 16 модулей.
Специализированный процессор имеет
систему команд БЭСМ6, поэтому программное
обеспечение с нее может использоваться
в комплексе. Коммутатор связывает также
основные блоки с 4 процессорами
ввода-вывода. Процессор ввода-вывода —
канал, имеющий собственную память,
устройство управления и оптимизатор —
блок в составе устройства управления,
позволяющий выбирать наиболее кратчайший
путь до внешнего устройства. К каждому
процессору ввода-вывода может быть
подключено до 4 процессоров передачи
данных. Это блоки преобразования
сигналов, как правило, в последовательные
коды и передачи их на расстояние. Общее
число линий связи в полной комплектации
системы — до 1000. Стандартное внешнее
устройство серии ЕС подключается к
процессору ввода-вывода через ряд
каналов. Быстрые периферийные устройства
(НГМД) связаны с процессорами ввода-вывода
через коммутирующие блоки — обменники.
В случае занятости одного из внешних
устройств запись данных будет выполняться
в другое. При полной комплектации
обменники существуют как для барабанов,
так и для дисков. Помимо этого особенность
системы «Эльбрус» — приближение уровня
машинного языка в системе команд к
уровню алгоритмического языка. В
результате скорость трансляции и
производительность системы возрастает.
Следующая особенность — в системе
применяются аппаратные стеки для
безадресных команд. Динамическое
перераспределение ресурсов и обработка
прерываний через стек. Безадресные
команды — это неявная адресация, когда
транслятор при расшифровке кода команды
обращается непосредственно к стеку где
лежит код команды, фазы адресации нет.
Каждое слово памяти снабжено специальным
ярлыком (признаком) называемым тегом.
В нем в дополнительных разрядах
указывается тип данных, операнды команд,
формат (плавающая, фиксированная запятая,
целые числа), имя переменной, режим
защиты. Массивы данных описываются
аппаратом дескрипторов. Он задает
адресные границы массива, тип содержимого,
данные команды и некоторые другие
характеристики.
Коммутатор
межмодульных связей (КМС) может
устанавливать линии связи с каждым из
10 центральных процессоров. Память
разбита на 2 страницы каждая по 16 модулей.
Специализированный процессор имеет
систему команд БЭСМ6, поэтому программное
обеспечение с нее может использоваться
в комплексе. Коммутатор связывает также
основные блоки с 4 процессорами
ввода-вывода. Процессор ввода-вывода —
канал, имеющий собственную память,
устройство управления и оптимизатор —
блок в составе устройства управления,
позволяющий выбирать наиболее кратчайший
путь до внешнего устройства. К каждому
процессору ввода-вывода может быть
подключено до 4 процессоров передачи
данных. Это блоки преобразования
сигналов, как правило, в последовательные
коды и передачи их на расстояние. Общее
число линий связи в полной комплектации
системы — до 1000. Стандартное внешнее
устройство серии ЕС подключается к
процессору ввода-вывода через ряд
каналов. Быстрые периферийные устройства
(НГМД) связаны с процессорами ввода-вывода
через коммутирующие блоки — обменники.
В случае занятости одного из внешних
устройств запись данных будет выполняться
в другое. При полной комплектации
обменники существуют как для барабанов,
так и для дисков. Помимо этого особенность
системы «Эльбрус» — приближение уровня
машинного языка в системе команд к
уровню алгоритмического языка. В
результате скорость трансляции и
производительность системы возрастает.
Следующая особенность — в системе
применяются аппаратные стеки для
безадресных команд. Динамическое
перераспределение ресурсов и обработка
прерываний через стек. Безадресные
команды — это неявная адресация, когда
транслятор при расшифровке кода команды
обращается непосредственно к стеку где
лежит код команды, фазы адресации нет.
Каждое слово памяти снабжено специальным
ярлыком (признаком) называемым тегом.
В нем в дополнительных разрядах
указывается тип данных, операнды команд,
формат (плавающая, фиксированная запятая,
целые числа), имя переменной, режим
защиты. Массивы данных описываются
аппаратом дескрипторов. Он задает
адресные границы массива, тип содержимого,
данные команды и некоторые другие
характеристики.
Принципы реализации технических средств сетей Ethernet. 29
Разделяют два
типа сетей: тонкий и толстый Ethernet.
Тонкий Ethernet
в качестве линий связи использует
коаксиальный кабель с волновым
сопротивлением 50 Ом, диаметром 0,2’.
Скорость передачи в обоих вариантах
примерно одинакова, но длина сегмента
различна. Тонкий кабель предусматривает
следующую структуру подключения к сети.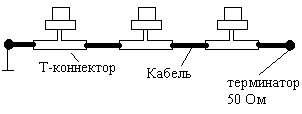
Интерфейсная плата каждой рабочей станции имеет треугольный высокочастотный разъем (Т- коннектор). Центральный штырь подключен к плате, 2 боковых имеют соединение с кабелем. На концах кабеля ставят специальные резисторы - поглотители, уменьшающие отраженную волну в кабеле от его неоднородностей . Один из терминаторов заземляют, второй оставляют свободным. Длина сегмента (расстояние между терминаторами) 330м. Количество подключений к сегменту не более 30. Тонкий кабель достаточно гибкий, поэтому он подводится к каждой рабочей станции непосредственно на рабочее место. Ограничение: расстояние между точками подключения не менее 1м. Каждый фрагмент кабеля должен быть целым без спаек, а кабель в одном сегменте из одной бухты, поскольку электрические параметры кабеля сильно влияют на скорость передачи.
Т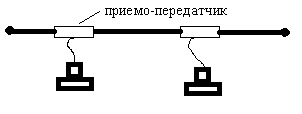 олстые
Ethernet
(0.4’) — волновое сопротивление 50Ом.
Длина одного сегмента до 500м. Число
станций, подключаемых к одному сегменту,
до 100. Минимальное расстояние между
станциями 3м. Структура подключения —
через приемо-передатчики. Максимальное
расстояние от врезки до интерфейсной
карты вычислителя 50 м, т. е. толстый
кабель является действительно магистралью,
к которой уже тонким кабелем подключаются
станции, расположенные вблизи кабеля.
Протокол доступа идентичен. Возможна
врезка с прокалыванием, т. е. непосредственно
гальванический контакт тонкого кабеля
с магистралью. Три иглы: центральная
игла — основная жила, две боковых
замыкаются с оплеткой кабеля.
олстые
Ethernet
(0.4’) — волновое сопротивление 50Ом.
Длина одного сегмента до 500м. Число
станций, подключаемых к одному сегменту,
до 100. Минимальное расстояние между
станциями 3м. Структура подключения —
через приемо-передатчики. Максимальное
расстояние от врезки до интерфейсной
карты вычислителя 50 м, т. е. толстый
кабель является действительно магистралью,
к которой уже тонким кабелем подключаются
станции, расположенные вблизи кабеля.
Протокол доступа идентичен. Возможна
врезка с прокалыванием, т. е. непосредственно
гальванический контакт тонкого кабеля
с магистралью. Три иглы: центральная
игла — основная жила, две боковых
замыкаются с оплеткой кабеля.
Имеются разработки локальной сети с оптоволоконным кабелем. Связь через специальный приемопередатчик. Сегменты между собой могут объединятся с использованием дополнительных приемопередатчиков. При этом приемопередатчик учитывается как рабочая станция.
31
В настоящее время сети рассматривают как средство электронных коммуникаций, при этом выделяют два вида услуг:
компьютеризированная межперсональная коммуникация — это обмен сообщениями, электронные новости, телеконференции и т. д.
Доступ к разделяемым ресурсам, т. е. к базам данных, управляющим программам, передача файлов и удаленный доступ.
Наиболее популярное направление на сегодня — электронная почта. Существует три разновидности электронной почты:
Простая — один абонент посылает сообщение другому.
Почтовые списки — один ко многим.
Телеконференция — многие ко многим.
Самый простой способ организации телеконференций — бюллетени (BBS). Электронная почта развивается как самостоятельная ветвь и существует ряд организаций (систем) обеспечивающих ее работу. Количество почтовых ящиков определяется в несколько сот тысяч. Большинство вычислительных сетей на сегодня развиваются с целью предоставления услуг. При этом возможны 2 подхода: интерактивный и пакетный (файловый) режимы. Сеть используется для доступа с терминалов, удаленного запуска программ, для вызова процедур. Распределенные файловые системы осуществляют доступ к файлам, размещенным в узлах сети. На каждой узловой ЭВМ возможен доступ, как к сетевым файлам, так и к локальным. Возможен режим блокирования доступа. Использование периферийных сетевых устройств также относится к этой группе. Пользователями категории услуг считаются разработчики вычислительных сетей, научные работники, вычислительные центры, административные и производственные службы. Корпоративные сети также относят ко второй группе. Как при разработке сети, так и при ее обслуживании стоит проблема стандартизации.
В основу сети положено оконечное оборудование данных, каналы связи и оборудование абонентов. Чтобы передача состоялась необходимо выполнить ряд условий, требований предъявляемых как к виду и форме представления сигнала, так и к оборудованию (линиям связи, приемникам, передатчикам). Эти требования определяются протоколом. Используют 7 уровней протоколов:
Физический. Канальный. Сетевой. Транспортный. Сеансовый. Представления.
Прикладной.
Каждый уровень отвечает своему стандарту. В основу сетей положен принцип взаимодействия открытых систем, т. е. сеть считается неким вычислительным блоком, к которому можно подключить дополнительные узлы. При этом характеристики сети не изменятся.
Например, протокол Х.25 является главным протоколом сетевого уровня в модели открытых систем. На физическом и канальном уровнях определяются механизмы передачи кадров данных по выделенным каналам связи в синхронном режиме. В рамках протокола имеются различные версии представления. Примеры протоколов: том 1 «Компьютерные версии представления». На физическом уровне определены стандарты на разъемы: типы, количество контактов, распайка, характеристики электрических сигналов, последовательность представления бит (аналогично интерфейсам). Физический уровень несколько шире интерфейсного, т. к. включает АЧХ устройств и требования к подключающим кабелям.
Современная сеть Internet развилась из варианта APRANET — многоуровневая сеть с коммутацией пакетов. В 1983 году из ARPANET выделилась MILNET (сеть Пентагон). В Европе существует своя сеть — Европейская сеть исследовательских организаций EARNET. UUCP — UNIX to UNIX. Основные отличия в рамках сетей — в протоколах связи, соответственно ПО и адресов (формы и содержания).
Кластерные системы 33
Кластерные технологии стали логическим продолжением развития идей, заложенных в архитектуре MPP систем. Если процессорный модуль в MPP системе представляет собой законченную вычислительную систему, то следующий шаг напрашивается сам собой: почему бы в качестве таких вычислительных узлов не использовать обычные серийно выпускаемые компьютеры. Развитие коммуникационных технологий, а именно, появление высокоскоростного сетевого оборудования и специального программного обеспечения, такого как система MPI, реализующего механизм передачи сообщений над стандартными сетевыми протоколами, сделали кластерные технологии общедоступными. Сегодня не составляет большого труда создать небольшую кластерную систему, объединив вычислительные мощности компьютеров отдельной лаборатории или учебного класса.
Привлекательной чертой кластерных технологий является то, что они позволяют для достижения необходимой производительности объединять в единые вычислительные системы компьютеры самого разного типа, начиная от персональных компьютеров и заканчивая мощными суперкомпьютерами. Широкое распространение кластерные технологии получили как средство создания систем суперкомпьютерного класса из составных частей массового производства, что значительно удешевляет стоимость вычислительной системы. В частности, одним из первых был реализован проект COCOA, в котором на базе 25 двухпроцессорных персональных компьютеров общей стоимостью порядка $100000 была создана система с производительностью, эквивалентной 48-процессорному Cray T3D стоимостью несколько миллионов долларов США.
Конечно, о полной эквивалентности этих систем говорить не приходится. Производительность систем с распределенной памятью очень сильно зависит от производительности коммуникационной среды. Коммуникационную среду можно достаточно полно охарактеризовать двумя параметрами: латентностью - временем задержки при посылке сообщения, и пропускной способностью - скоростью передачи информации. Так вот для компьютера Cray T3D эти параметры составляют соответственно 1 мкс и 480 Мб/сек, а для кластера, в котором в качестве коммуникационной среды использована сеть Fast Ethernet, 100 мкс и 10 Мб/сек. Это отчасти объясняет очень высокую стоимость суперкомпьютеров. При таких параметрах, как у рассматриваемого кластера, найдется не так много задач, которые могут эффективно решаться на достаточно большом числе процессоров.
Если говорить кратко, то кластер - это связанный набор полноценных компьютеров, используемый в качестве единого вычислительного ресурса. Преимущества кластерной системы перед набором независимых компьютеров очевидны. Во-первых, разработано множество диспетчерских систем пакетной обработки заданий, позволяющих послать задание на обработку кластеру в целом, а не какому-то отдельному компьютеру. Эти диспетчерские системы автоматически распределяют задания по свободным вычислительным узлам или буферизуют их при отсутствии таковых, что позволяет обеспечить более равномерную и эффективную загрузку компьютеров. Во-вторых, появляется возможность совместного использования вычислительных ресурсов нескольких компьютеров для решения одной задачи.
Для создания кластеров обычно используются либо простые однопроцессорные персональные компьютеры, либо двух- или четырех- процессорные SMP-серверы. При этом не накладывается никаких ограничений на состав и архитектуру узлов. Каждый из узлов может функционировать под управлением своей собственной операционной системы. Чаще всего используются стандартные ОС: Linux, FreeBSD, Solaris, Tru64 Unix, Windows NT. В тех случаях, когда узлы кластера неоднородны, то говорят о гетерогенных кластерах.
При создании кластеров можно выделить два подхода. Первый подход применяется при создании небольших кластерных систем. В кластер объединяются полнофункциональные компьютеры, которые продолжают работать и как самостоятельные единицы, например, компьютеры учебного класса или рабочие станции лаборатории. Второй подход применяется в тех случаях, когда целенаправленно создается мощный вычислительный ресурс. Тогда системные блоки компьютеров компактно размещаются в специальных стойках, а для управления системой и для запуска задач выделяется один или несколько полнофункциональных компьютеров, называемых хост-компьютерами. В этом случае нет необходимости снабжать компьютеры вычислительных узлов графическими картами, мониторами, дисковыми накопителями и другим периферийным оборудованием, что значительно удешевляет стоимость системы.
Разработано множество технологий соединения компьютеров в кластер. Наиболее широко в данное время используется технология Fast Ethernet. Это обусловлено простотой ее использования и низкой стоимостью коммуникационного оборудования. Однако за это приходится расплачиваться заведомо недостаточной скоростью обменов. В самом деле, это оборудование обеспечивает максимальную скорость обмена между узлами 10 Мб/сек, тогда как скорость обмена с оперативной памятью составляет 250 Мб/сек и выше. Разработчики пакета подпрограмм ScaLAPACK, предназначенного для решения задач линейной алгебры на многопроцессорных системах, в которых велика доля коммуникационных операций, формулируют следующим образом требование к многопроцессорной системе: "Скорость межпроцессорных обменов между двумя узлами, измеренная в Мб/сек, должна быть не менее 1/10 пиковой производительности вычислительного узла, измеренной в Mflops" Таким образом, если в качестве вычислительных узлов использовать компьютеры класса Pentium III 500 Мгц (пиковая производительность 500 Mflops), то аппаратура Fast Ethernet обеспечивает только 1/5 от требуемой скорости. Частично это положение может поправить переход на технологии Gigabit Ethernet.
Ряд фирм предлагают специализированные кластерные решения на основе более скоростных сетей, таких как SCI фирмы Scali Computer (~100 Мб/сек) и Mirynet (~120 Мб/сек). Активно включились в поддержку кластерных технологий и фирмы-производители высокопроизводительных рабочих станций (SUN, HP, Silicon Graphics).
10
Способы адресации в ЭВМ. Базовые способы адресации. Модификация адресов. Форматы команд с модификацией.
Базовые способы адресации
Принцип работы любого вычислителя основан на извлечении содержимого памяти: по адресу читаем содержимое соответствующей ячейки , модифицируем его и возвращаем назад в другую ячейку памяти. При этом в вычислителе выделяем два потока информации:
1) Код команды (КОП и следующие байты, например, адрес ячейки памяти) пересылаются из ПЗУ в регистр команд. Адрес формируется счетчиком адреса команд процессора. Последовательная выборка, переходы выполняются только с использованием этого счетчика.
2) Непосредственно данные, пересылаются между процессором и ОЗУ. Объем памяти данных значительно больше памяти команд. К данным процессор обращается по адресу, зачастую зависимому от алгоритма решаемой задачи. Поэтому чтение (запись) возможно с применением нескольких способов формирования адреса данных. Эти способы называют « адресацией». Переход от одного типа адресации к другому объясняется стремлением пользователя упростить процедуру написания программы, сократить объем памяти команд. Базовыми способами адресации данных являются:
1) прямая адресация;
2) косвенная;
3) непосредственная.
Прямая адресация применяется для обмена данными с ОЗУ или устройствами ввода-вывода. Формат команд прямой адресации имеет вид.

