

Типы интерфейсов вычислительных устройств. 16
Непосредственно с идеологией канала связан термин интерфейс. Он объединяет в себе аппаратные и логические построения, обеспечивающие правильную передачу информации от источника к приемнику. Как правило, на верхнем понятии каналы и интерфейсы часто совмещают. Общее у них — передача информации, но интерфейс, более конкретный термин, имеющий фиксированные характеристики и часто канал вбирает в себя характеристики интерфейса. Любой канал имеет интерфейс. Различают интерфейсы по многим критериям. Например, по способу передачи данных.Последовательный способ. Сигналы данных передаются в виде низкого и высокого уровней последовательно от источника к приемнику, причем способ передачи может быть как синхронным так и асинхронным. Параллельный способ. Байт данных (два байта) одновременно передается от источника к приемнику. Этот способ также может быть синхронным или асинхронным. По направлению передачи интерфейсы делят на следующие.
1) Цепочечные
2) Радиальные (типа звезда).
3) Магистральные. Источник выставляет информацию на шине (магистрали) и все внешние устройства подключенные к ней могут считать информацию. Для определенности ВУ выбирают, обеспечивая один приемник. По отношению к радиальному способу аппаратные затраты ниже, но надежность и скорость хуже. Магистральный интерфейс позволяет изменять число внешних устройств, при этом их можно менять местами.

Радиальный интерфейс более быстр, надежен, но требует отдельных разъемов для подключения. Радиальные интерфейсы используются в ПЭВМ для подключения периферии. Магистральный интерфейс используют для объединения функциональных модулей в вычислитель. На основе магистрального интерфейса разработан функционально-модульный метод объединения блоков.

По назначению интерфейсы разделяют на следующие типы:
1) Системный интерфейс
2) Интерфейсы внешних устройств.
3) Межпроцессорные интерфейсы
4) Межсистемные интерфейсы
Системные интерфейсы предназначены для организации связи с различными блоками вычислительной системы процессорами, памятью, контроллерами устройств ввода/вывода. Это некая основа, на которой построен вычислитель. Изменение конфигурации ЭВМ в пределах интерфейса приводит лишь к программным изменениям. Стоит поменять интерфейс, сразу же возникают аппаратные дополнения. Тип системного интерфейса формировался при проектировании различных ЭВМ: 8-, 16-, 32-разрядных с раздельной или совмещенной шиной адрес/данные. Таким образом,. первоначально, когда разрабатывался вычислитель, принимались связи между блоками и затем эти связи определялись как тот или иной тип интерфейса. Последующие разработки использовали уже имеющиеся типы связей. При разработке нового вычислителя принят модульный подход: выбирается стандартный системный интерфейс (если он не задан), функциональные блоки, определенные заданием подключаются по правилам этого интерфейса, уточняются их характеристики, определяются параметры — вычислитель «спроектирован». Примерами системных интерфейсов являются: multybus, Q-bus, microbus, ISA, EISA, PCI.
Периферийные интерфейсы связывают устройства ввода/вывода с внешними (периферийными) устройствами. Периферийные интерфейсы имеют большую стабильность, поскольку номенклатура периферии широкая и изменение в способах ее подключения снижает потребительские качества внешних устройств. Самыми распространенными считаются следующие:
Параллельный интерфейс ИРПМ-М (CENTRONIX) — байтовый параллельный интерфейс для обмена байтами (принтер, индикация). Интерфейс асинхронный. Известен также как LPT – порт.
ИРПС (интерфейс радиальный последовательный) — информация передается последовательно, каждый байт стробируется (синхронизируется с приемником), информация передается уровнем тока, поэтому помехоустойчивость наибольшая (токовая петля).
RS-232C (стык С2, com-порт) — информация передается последовательно со стробированием байтов. Интерфейс потенциальный «1»=+(5 - 12)В, «0»=-(5 -12)В. Расстояние 0.7-1.5 метра. Применяют в ПЭВМ для связи со стандартной периферией. Самой известной модификацией этого интерфейса считается RS – 485, используемый для работы с удаленными внешними устройствами.
Межсистемные интерфейсы предназначены для связи, объединения различных систем в единую конфигурацию. Как правило, это информационно-вычислительные системы, поэтому для них используют концепцию открытых систем, позволяющую наращивать вычислители. Примером такой конфигурации является интерфейс VME — трехшинная архитектура, включающая параллельную системную магистраль, последовательную магистраль и параллельную магистраль расширения памяти.
Межпроцессорные интерфейсы ориентируются на системную магистраль (работая порознь).
Последовательный интерфейс RS-232 17
Для последовательных интерфейсов выбор подключаемых устройств значительно шире, поэтому большинство персональных компьютеров одновременно оборудованы двумя интерфейсными разъёмами для последовательной передачи данных ( Рис.2.1)Обычно они различаются по внешнему виду. Разъёмы последовательного интерфейса на РС представляют собой 9 – контактный (вилка) Sub – D и 25 – контактный (вилка) Sub – D, назначение контактов которых приведено в таблице 2.1
В качестве стандартного обозначения для последовательного интерфейса чаще всего используют RS -232С.
Главный элемент последовательного интерфейса – микросхема UART (Universal Asynchron Receiver Transmitter) 16550AF, 16650 или 16750. В старых контроллерах применялись микросхемы: 8250 (А,В), 16450, 16550 (А). Контроллер на базе схемы 8250 обеспечивает максимальную скорость передачи данных 9600 бод, схема 16450 – 115200 бод, а схема 16550AF, и ему подобные – 921600 бод.
В отличии от параллельной передачи данных, последовательная передача осуществляется побитно. Отдельные биты пересылаются (или принимаются) последовательно друг за другом, при этом возможен обмен данными в двух направлениях. Уровень напряжения последовательного интерфейса изменяется в пределах от -12 до +12 В. Благодаря этому относительно высокому значению напряжения повышается помехоустойчивость, и данные могут передаваться без потерь по кабелю длиной до 15 метров. Контроллер интерфейса RS-232С является программируемым устройством; задаются следующие параметры обмена: количество битов данных и стоп-битов, вид четности и скорость обмена в бодах (бит/с).
В асинхронном режиме, который используют персональные ЭВМ, передаваемая команда состоит из стартового бита, 8 бит данных и одного стоп – бита, прием и передача данных осуществляются с одинаковой тактовой частотой.
Для связи через последовательный интерфейс достаточно трёх проводов: приёма, передачи и корпус. Однако на практике это часто не так, что показывает таблица 2.1.
Последовательный интерфейс связывает два устройства. Для того чтобы “собеседники” при обмене данными не перебивали друг друга, они должны иметь единый протокол приёма/передачи которым определяется последовательность обмена данными.
Данные при последовательной передачи разделяются служебными посылками, такими как стартовый бит (Start bit) и стоп – бит (Stop bit). Эти биты указывают на начало и конец последовательности бит данных (Data bits). Данный метод передачи осуществить синхронизацию между приёмной и передающими сторонами, а также выровнять скорость обмена данными.
Для идентификации и распознавания ошибок при последовательной передаче в состав посылки дополнительно включают бит контроля чётности (Parity bit). Существует несколько различных вариантов использования бита контроля чётности:
- бит контроля чётности не посылается (No Parity)
- бит контроля чётности чётный (Even Parity)
- бит контроля чётности нечётный (Odd Parity)
Значение бита контроля чётности определяется «суммой по модулю два» всех передаваемых битов данных.
COM – порты могут быть сконфигурированы различным образом. BIOS персональных компьютеров поддерживает до 4 последовательных интерфейсов. С конфигурацией двух как правило, проблем не возникает, тем более что стандартные установки на плате интерфейса обычно соответствуют оптимальным. Проблемы могут возникнуть при конфигурировании портов COM3 и COM4, поскольку для необходимо указать непересекающиеся с другими устройствами адреса и номера линий прерывания.
Работа с параллельным портом (LPT)
В типовом режиме LPT- порт настроен на вывод информации, поэтому для перевода его в режим ввод, необходимо выбрать режим работы EPP (Enhanced Parallel Port – режим двунаправленной передачи данных). Это делается в BIOS. Во время загрузки компьютера, когда появится надпись Press DEL to enter setup, следует нажать DEL, чтобы попасть в меню BIOS. Затем выбираем раздел INTEGRATED PERIPHERALS и там - строку PARALLEL PORT MODE: для изменения режима работы порта на EPP или SPP/EPP. Если же нет режима EPP, то возможно только передавать данные Параллельный порт для связи с принтером (или другим устройством) имеет базовый адрес &H378 (LPT1), &H278 (LPT2), &H3BC (LPT3).. Адресное пространство порта занимает диапазон &H378-&H37F. Адрес &H378 называется базовым и служит для передачи или чтения данных, через контакты 2-9 разъема LPT-порта. Адрес &H37A служит для передачи управляющих сигналов к устройству, подключенного к этому порту (принтер, сканер и т.д.). И, наконец, адрес &H379 предназначен для приема управляющих сигналов с устройства, подключенного к этому порту (принтер, сканер и т.д.).
ОРГАНИЗАЦИЯ СИСТЕМЫ ПРЕРЫВАНИЙ 18
Система прерываний имеется в любом вычислителе и предназначена для упрощения работы функциональных блоков при изменении внешних условий. Эти изменения называют причинами прерываний:
от схем контроля ошибок;
источников питания;
результатов текущих операций (переполнение, деление на ноль);
от внешних устройств, при их неготовности или необходимости передать информацию от других процессоров;
программные прерывания.
Любая процедура прерывания — подпрограмма, поэтому обработка подпрограммы требует начального адреса подпрограммы, сохранения предыдущих данных и «мягкого» завершения подпрограммы. Такая подпрограмма может быть вызвана электрическими сигналами (запрос на прерывание), либо она может начаться по обращению к адресу как к обычной подпрограмме. Адреса подпрограмм прерываний в конкретных системах команд фиксированы. Программные прерывания упрощают выполнение стандартных процедур (например: обнуление экрана, опрос клавиатуры). Программными требованиями рекомендуют пользоваться при работе на уровне ассемблера. Прерывания от внешних сигналов связаны с обработкой внешних электрических сигналов. У процессора имеется два входа: требование прерывания (вход) и разрешение прерывания (выход). Сигнал на вход поступает от одного или нескольких внешних источников и вызывает обработку нужной подпрограммы. Если источник один, можно напрямую подключить этот сигнал к входу процессора. Если источников сигналов несколько, используют различные методы опознавания, какую подпрограмму начать.
Способ с последовательным опросом
Любое внешнее устройство может послать запрос на прерывание, (например, понизить уровень в линии). Получив такой сигнал, процессор должен завершить текущую команду, для чего его устройство управления отрабатывает все нужные микрокоманды из оставшихся, запоминает адрес следующей команды, запоминает признаки текущей команды и промежуточные результаты. Эти данные переписываются в регистр состояния. При отсутствии такого регистра они помещаются в стековую память. Закончив эти процедуры, процессор должен опознать устройство, пославшее запрос, для чего он перебирает на адресной шине адреса внешних устройств, которые могли бы послать запрос. Если внешнее устройство, пославшее запрос, получило адрес, оно снимает запрос на прерывание и процессор по этому адресу определяет адрес подпрограммы. Недостаток — значительное время опознавания .
Использование системы с одной линией подтверждения.
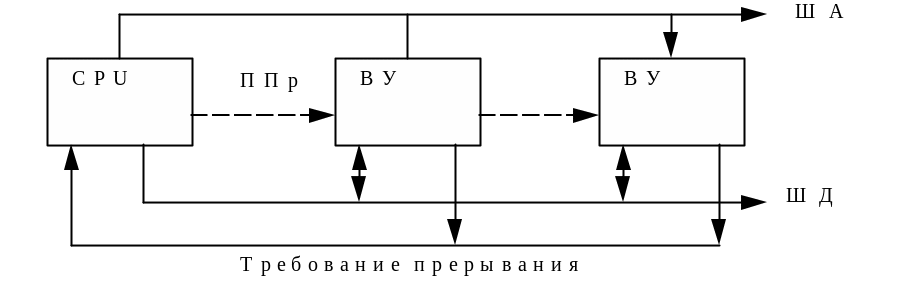 Через
все внешние устройства проходит линия
подтверждения прерывания (Рис.24.)
Процессор, получив сигнал запроса на
прерывание, заканчивает текущую команду
и посылает сигнал подтверждения, который
последовательно проходит через каждое
устройство. Если устройство не посылало
запроса, оно транслирует сигнал дальше.
Если устройства не было, сигнал проходит
через заглушку разъема. Дойдя до
устройства, пославшего запрос, сигнал
вызывает передачу адреса на шину данных
этого устройства. Это не обязательно
адрес устройства. Логичнее посылать
адрес подпрограммы обработки запроса.
Приняв этот код, процессор переходит
по данному адресу. Время обработки
прерывания небольшое, но требуется
следить, чтобы линия была исправна.
Через
все внешние устройства проходит линия
подтверждения прерывания (Рис.24.)
Процессор, получив сигнал запроса на
прерывание, заканчивает текущую команду
и посылает сигнал подтверждения, который
последовательно проходит через каждое
устройство. Если устройство не посылало
запроса, оно транслирует сигнал дальше.
Если устройства не было, сигнал проходит
через заглушку разъема. Дойдя до
устройства, пославшего запрос, сигнал
вызывает передачу адреса на шину данных
этого устройства. Это не обязательно
адрес устройства. Логичнее посылать
адрес подпрограммы обработки запроса.
Приняв этот код, процессор переходит
по данному адресу. Время обработки
прерывания небольшое, но требуется
следить, чтобы линия была исправна.
Рис. 31 Структура системы прерываний с одной линией запроса
Применение системы с использованием контролера прерываний.
В этой структуре адрес устройства, пославшего запрос на прерывание, определяет специальная схема — контролер прерываний (Рис. 25). С появлением на любом входе контролера активного сигнала схема расшифровывает этот сигнал в адрес входа и выставляет на шину данных этот адрес.
Рис.32. Структура системы прерываний с контроллером
 Последовательность
выполнении процедуры прерывания может
быть следующая.
Последовательность
выполнении процедуры прерывания может
быть следующая.
запрос ВУ;
контролер выставляет требование;
получает подтверждение запроса на прерывание;
выставляет на шине данных адрес устройства.
Данная структура имеет минимальное время срабатывания, удобна и в настоящее время применяется в большинстве вычислителей.
Контролер прерываний может выполняться как самостоятельная схема или интегрироваться в схему микропроцессора .
Основные задачи контролера:
корректно изменить последовательность вычислений;
определить приоритеты;
корректно вернуться в прерванную программу.
Получив сигнал запроса от внешнего устройства, контролер анализирует все входы. Если приоритет высший, либо сигнал один, контроллер посылает запрос требования прерывания и ожидает конца предыдущей операции. Для этого часто используют отдельную линию подтверждения прерывания. Время между сигналом запроса и подтверждения в общем случае произвольно. Все это время устройство, пославшее запрос на прерывание поддерживает его на входе контролера. После получения подтверждения контроллер выставляет адрес того входа на котором был активный сигнал. Процессор этот адрес (1 байт) обрабатывает и через шину адреса начинает подпрограмму.
Сигналы прерывания могут появиться одновременно на нескольких входах. Для их упорядочивания используют систему приоритетов и маскирования. Каждый вход контроллера имеет свой приоритет (1…н, 1- самый важный). Входы контроллера подключаются к внешним сигналам согласно приоритетам. Если появляются два сигнала одновременно, обрабатывается сигнал высшего приоритета. Если сигнал высшего приоритета приходит с некоторой задержкой от первого сигнала прерывания, вступает в работу методика маскирования. Предыдущая команда, уже начатая при обработке прерываний, выполняется до конца. Ее результаты запоминаются, и только после запоминания изменяется адрес и процессор переходит на обработку высшего приоритета. Цель такой задержки — сохранить контекст при обращении к подпрограммам: переход возможен только после завершения текущей команды. Если подпрограмма высшего приоритета обработана, процессор возвращается к первой подпрограмме прерываний. При этом анализируется необходимость ее завершения: сохранился ли сигнал первого прерывания. Если он не сохранился, происходит возврат из подпрограммы в основную программу. Результаты прерванной подпрограммы восстанавливаются. Восстановление результата при выходе из подпрограммы считается стандартной процедурой.
Иерархия устройств памяти 19
Принято все элементы памяти, используемые в вычислителях представлять по степени приближения к процессору. (Рис.33.)
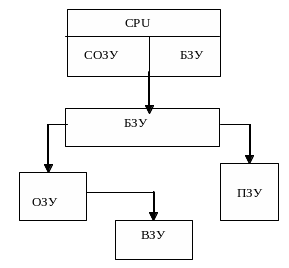 Непосредственно
к АЛУ приближены схемы СОЗУ —внутренние
регистры процессора (РОНы). РОН выполняются
на одном кристалле с АЛУ. Связь
процессор—АЛУ—СОЗУ выполняется по
внутренней шине процессора. Адресация
к внутренним регистрам предусмотрена
в структуре КОП. Здесь же на кристалле
может находиться буферная память (кэш),
причем как данных, так и команд. Буферное
ОЗУ (БЗУ) в этом случае также обменивается
с АЛУ через внутреннюю шину. БОЗУ может
выполняться и вне кристалла, причем
связь процессор – буфер реализуется
через внешнюю шину данных. Такая ситуация
возможна, если цикл работы микропроцессора
и ОЗУ отличаются незначительно.
Непосредственно
к АЛУ приближены схемы СОЗУ —внутренние
регистры процессора (РОНы). РОН выполняются
на одном кристалле с АЛУ. Связь
процессор—АЛУ—СОЗУ выполняется по
внутренней шине процессора. Адресация
к внутренним регистрам предусмотрена
в структуре КОП. Здесь же на кристалле
может находиться буферная память (кэш),
причем как данных, так и команд. Буферное
ОЗУ (БЗУ) в этом случае также обменивается
с АЛУ через внутреннюю шину. БОЗУ может
выполняться и вне кристалла, причем
связь процессор – буфер реализуется
через внешнюю шину данных. Такая ситуация
возможна, если цикл работы микропроцессора
и ОЗУ отличаются незначительно.
Основная память — ОЗУ. Объем ОЗУ может быть значительным, наращиваемым. Условие: в пределах физического адреса формируемого схемой можно наращивать ОЗУ. ПЗУ в вычислителе, как правило, выступает в роли системного. В нем хранятся управляющие коды базовой системы ввода \ вывода, а также коды контроля, тестирования блоков вычислителя. В зависимости от назначения объем ПЗУ может составлять от нескольких килобайт до сотен килобайт. В небольших вычислителях в нем хранятся не только системные программы, но и рабочие.
Внешние ЗУ расширяют возможности вычислителя. При этом они могут хранить как данные, так и командные файлы. Процессор напрямую с ВЗУ не работает, отсюда приходится перегружать содержимое ВЗУ в ОЗУ с тем, чтобы уменьшить время выполнения операций. Внешние ЗУ предназначены для построения внешней памяти (третьего уровня). Основные характеристики: низкое быстродействие, очень большая (практически неограниченная) емкость, малая удельная стоимость. ВЗУ строится на базе различного рода носителей информации в качестве запоминающей среды: магнитных – МЛ, МД (жестких и гибких), оптических (ОД типа СD ROM и др.). При обращениях к такого рода ЗУ их носители информации приводятся в движение (обычно с постоянной скоростью – это их отличительная особенность). Для приведения носителя в движение используют различного рода приводы (электрические по своей природе – на основе электродвигателей). Привод вместе с носителем информации принято называть накопителем: НМЛ, НМД, НОД, Для обозначения запоминающих устройств на схемах используются различного рода УГО (ГОСТ 2.743-97):
Основные характеристики ЗУ: емкость и быстродействие. Емкость ЗУ в ВТ принято измерять в байтах, Кб, Мб, Гб, Тб, … . Быстродействие ЗУ измеряется количеством циклов обращения в единицу времени. Обращение к ЗУ производится либо с целью чтения информации, либо с целью записи информации. За одно обращение читается (записывается) порция данных фиксированной длины. Быстродействие ЗУ определяется временем одного обращения VЗУ=1/tобр. Время обращения складывается из времени доступа к адресуемому элементу и времени его чтения или записи.
Устройства ввода (УВВ) предназначены для чтения информации с носителя информации и ввода ее в память ЭВМ. Устройства вывода (УВыВ) предназначены для записи информации, выводимой из ОП, на носитель информации. В процессе ввода/вывода эти устройства обеспечивают преобразование сигналов из одной физической природы в сигналы другой природы. Примером универсального устройства ввода и вывода является устройство типа НГМД. В качестве носителя информации в этом устройстве используется ГМД (floppy disc) – дискета, которая может использоваться как источник информации при вводе в память ЭВМ и как приемник – при выводе из памяти ЭВМ.
На дискете информация хранится в виде магнитных отпечатков, следов, т.е. используется магнитная природа хранения информации. При вводе (чтении) информации с дискеты происходит ее преобразование в совокупность электрических сигналов, представляющих информацию в двоичном коде (на дискете – двоичный магнитный код, при считывании – двоичный электрический код). При выводе (записи) на дискету – обратное преобразование: совокупность электрических сигналов преобразуется в совокупность магнитных следов (отпечатков) на дискете.
Типичным примером УВВ является клавиатура, которая обеспечивает ввод текстовой (символьной) информации с бумажного носителя информации (или из головы человека) в память ЭВМ путем нажатия соответствующих клавиш. Типичным УВыВ является принтер (печатающее устройство): обеспечивает вывод информации из памяти ЭВМ на бумажный носитель. Или другой пример УВыВ – дисплей – устройство, обеспечивающее отображение информации, выводимой из памяти ЭВМ.
Следует отметить, что при вводе/выводе информации при помощи устройств ввода/вывода происходит не только преобразование сигналов (информации) одной физической природы в сигналы другой физической природы, но и ее (информации) кодирование. Для кодирования информации можно использовать различные кодовые комбинации. Например, при вводе/выводе символьной (текстовой) информации обычно используется стандартный код ASCII (как международный стандарт) – американский стандартный код обмена информацией. В России ему соответствует код обмена информацией семибитный – КОИ-7 (ГОСТ 13052-96).
Основные характеристики УВВ: затраты оборудования и быстродействие.
Затраты оборудования УВВ характеризуют такие параметры как габариты, вес и др.
Быстродействие УВВ характеризуется скоростью ввода/вывода информации, т. е. количеством информации в единицу времени. Например, количеством символов в секунду.
Модули памяти ОЗУ и ПЗУ 20
Структура вычислителя ориентирована на функциональные узлы ОЗУ, ПЗУ с организацией n*8. Обращение к памяти производится побайтно. В связи с эти необходимо комплексирование элементов памяти, имеющих другую организацию. Наиболее типичным примером схем ОЗУ с организацией 2n*1 являются схемы памяти динамического типа К565РУ. Для получения требуемой организации n*8 необходимо комплексировать корпуса — объединять в блоки по 8 корпусов.
Правила объединения:
сигналы адреса всех 8 корпусов объединяются параллельно;
сигналы данных подсоединяются к шине (соответствующим 8 разрядам);
сигналы RD/WR включаются параллельно;
сигналы выборки CS включаются параллельно.
Особенность схем этой серии — адрес записывается за два такта, для чего, применяют управляющие сигналы CAS и RAS (включаются параллельно). Такой модуль может иметь небольшую емкость, тогда для увеличения емкости включают несколько таких модулей. Выбор модулей — по сигналам адресного дешифратора через вход выбора кристалла CS. Регенерация в схемах происходит в выбранном модуле по столбцам.
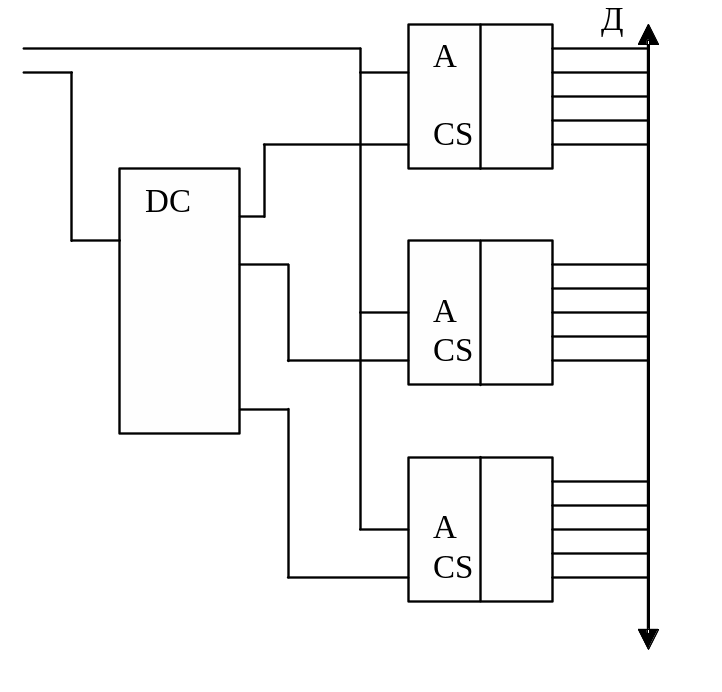 Схемы
К537РУ - статического типа, не требуют
регенерации, поэтому при небольшом
объеме памяти более удобны, но для
увеличения объема их наращивают с
помощью адресного дешифратора(Рис. 27).
Статические ОЗУ более удобны в контролерах,
формирующих временные интервалы.
Динамические схемы требуют регенерации,
поэтому время выполнения отдельных
команд непостоянно.
Схемы
К537РУ - статического типа, не требуют
регенерации, поэтому при небольшом
объеме памяти более удобны, но для
увеличения объема их наращивают с
помощью адресного дешифратора(Рис. 27).
Статические ОЗУ более удобны в контролерах,
формирующих временные интервалы.
Динамические схемы требуют регенерации,
поэтому время выполнения отдельных
команд непостоянно.
 Схемы однократно
программируемые пользователем типа
РЕ используют пережог плавких перемычек,
соединяющих строки и столбцы матрицы
элементов памяти. Перемычки однонаправлены,
следовательно, они должны включать диод
или транзистор. КМОП - транзисторы
достаточно долго не применялись
вследствие малых токов. На сегодня
основной элемент в связях - биполярный
многоэмиттерный транзистор, в эмиттер
которого включена плавкая вставка.
Физически плавкая вставка представляет
из себя слой металла из NiCr,
напыленный на разрыв алюминиевого
проводника. Для создания локального
перегрева вставка имеет утонченный
профиль. По цепи эмиттера транзистор
выбирается и через коллектор-эмиттер
пропускается ток пилообразной формы.
Скорость нарастания импульсов и их
длительность подбираются для каждого
типа схем. При быстром нарастании тока
может произойти термовзрыв — быстрый
перегрев перемычки и закипание металла
(металл разбрызгивается). При медленном
нарастании тока перемычка не расплавляется,
поскольку энергии недостаточно. Основной
недостаток схем типа К556 - возможность
восстановления связей. Со временем
кристалл нагревается, алюминиевые
проводники сближаюься и контакт
восстанавливается. Такое явление
устраняется термотренировкой — схема
программируется, нагревается, повторно
программируется, нагревается. Число
таких циклов порядка 10. Схемы этой серии
не рекомендуют в специзделиях из-за
восстановления. Для таких изделий
разработаны схемы серии К541, в которых
перемычки выполнены из поликремния.
При разогреве перемычек полупроводник
переходит в агрегатное состояние
изолятора. Состояние необратимое,
поэтому такие перемычки не восстанавливаются,
но нагрев производится до большой
температуры, поэтому выход годных схем
ниже, схемы дороже.
Схемы однократно
программируемые пользователем типа
РЕ используют пережог плавких перемычек,
соединяющих строки и столбцы матрицы
элементов памяти. Перемычки однонаправлены,
следовательно, они должны включать диод
или транзистор. КМОП - транзисторы
достаточно долго не применялись
вследствие малых токов. На сегодня
основной элемент в связях - биполярный
многоэмиттерный транзистор, в эмиттер
которого включена плавкая вставка.
Физически плавкая вставка представляет
из себя слой металла из NiCr,
напыленный на разрыв алюминиевого
проводника. Для создания локального
перегрева вставка имеет утонченный
профиль. По цепи эмиттера транзистор
выбирается и через коллектор-эмиттер
пропускается ток пилообразной формы.
Скорость нарастания импульсов и их
длительность подбираются для каждого
типа схем. При быстром нарастании тока
может произойти термовзрыв — быстрый
перегрев перемычки и закипание металла
(металл разбрызгивается). При медленном
нарастании тока перемычка не расплавляется,
поскольку энергии недостаточно. Основной
недостаток схем типа К556 - возможность
восстановления связей. Со временем
кристалл нагревается, алюминиевые
проводники сближаюься и контакт
восстанавливается. Такое явление
устраняется термотренировкой — схема
программируется, нагревается, повторно
программируется, нагревается. Число
таких циклов порядка 10. Схемы этой серии
не рекомендуют в специзделиях из-за
восстановления. Для таких изделий
разработаны схемы серии К541, в которых
перемычки выполнены из поликремния.
При разогреве перемычек полупроводник
переходит в агрегатное состояние
изолятора. Состояние необратимое,
поэтому такие перемычки не восстанавливаются,
но нагрев производится до большой
температуры, поэтому выход годных схем
ниже, схемы дороже.
Репрограммируемые схемы памяти имеют также матрицу с однонаправленными элементами связи. Каждый элемент путем подачи высокого потенциала (26-28В) переводится в непроводящее состояние. Со временем накопленные заряды могут стекать и элементы связи вернутся в исходное состояние. Поэтому стремятся увеличить «время жизни» такого состояния. Искусственное стирание информации производится облучением жесткими лучами схем РФ и подачей обратного потенциала в схемах РР. Стираемые ультрафиолетовыми лучами связи в схемах серии 573РФ обычно стремятся изолировать от света солнца, закрашивая окно в корпусе непрозрачным лаком. Особый интерес представляют разработанные схемы ППЗУ на основе КМОП технологии — с малым энергопотреблением, высокой надежностью.
Безадресные схемы. Стек. 21
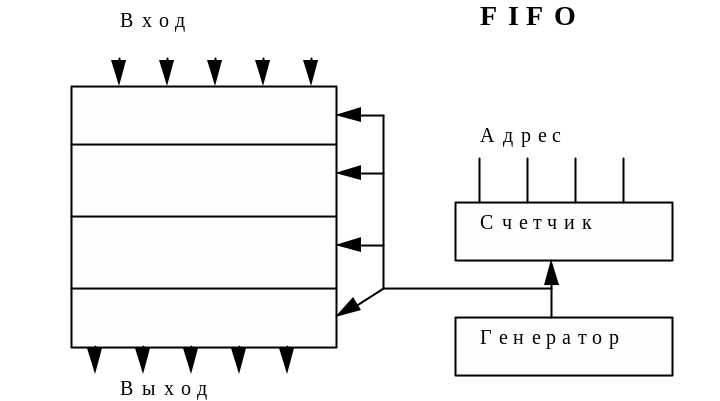 Другим
примером безадресных схем, являются
схемы, построенные по принципу стека —
набор регистров, в которых информация
сохраняется незначительное время.
Фактически адрес в этих структурах все
же присутствует, хотя проявляется
неявно. Стек типа FIFO
( первый вошел, первый вышел) представляет
из себя набор нескольких регистров,
разряды которых параллельно соединены,
так что при каждом тактовом сигнале
содержимое проталкивается вниз. Число
регистров определяет глубину стека.
Эта структура обеспечивает некоторую
задержку хранимой информации и доступ
к ней по внешнему сигналу. При каждом
проталкивании вниз в верхний регистр
записывается новая информация. Стек
FIFO
применяют для хранения потока входной
информации.
Другим
примером безадресных схем, являются
схемы, построенные по принципу стека —
набор регистров, в которых информация
сохраняется незначительное время.
Фактически адрес в этих структурах все
же присутствует, хотя проявляется
неявно. Стек типа FIFO
( первый вошел, первый вышел) представляет
из себя набор нескольких регистров,
разряды которых параллельно соединены,
так что при каждом тактовом сигнале
содержимое проталкивается вниз. Число
регистров определяет глубину стека.
Эта структура обеспечивает некоторую
задержку хранимой информации и доступ
к ней по внешнему сигналу. При каждом
проталкивании вниз в верхний регистр
записывается новая информация. Стек
FIFO
применяют для хранения потока входной
информации.
Стек типа LIFO (последний вошел, первый вышел) предусматривает запись и чтение только с верхнего регистра. В стек заносятся последовательно несколько слов, чтение производится в обратной последовательности. Этот стек разработан для адресации при обращении к подпрограммам. При обращении к подпрограмме в стек заносится адрес возврата. Если в выполняемой подпрограмме имеются вложенные подпрограммы, адрес возврата в основную программу проталкивается вниз до полной глубины стека. При выходе из подпрограммы содержимое поднимается и последним показывается адрес возврата в основную программу. Стек выполняется аппаратно, что дает сокращение времени при работе с подпрограммами. Как таковой адрес в этих схемах и не нужен. Информация об адресе косвенно учитывается программистом при составлении программы.
Архитектурные принципы Фон Неймана 22
Традиционно архитектура Фон Неймана имеет четыре основные характеристики:
Единое вычислительное устройство, включающее процессор, средства передачи информации и память;
Линейную структуру адресации памяти, включающую слова фиксированной длины (формат команд представляется байтами, сложные команды — несколько байт);
Низкий уровень машинного языка (команды процессора выполняют простые операции, т.е. сложные процедуры выполняются последовательно);
Централизованное последовательное управление (последовательно читаются команды, последовательно выполняются операции).
В гарвардской архитектуре память данных и память команд разделены, т.е. процессор читает команды из памяти команд по шине команд и читает данные из памяти данных по шине данных. Между ними (шинами) может быть связь через мультиплексор.
Как в традиционной, так и гарвардской структуре существует принципиальное явление, ограничивающее производительность процессора — канал связи. Если увеличивать быстродействие процессора, то скорость выполнения начинает ограничиваться задержкой в канале. Эта величина конечна, поэтому ее практически не преодолеть. Если увеличить число процессоров работающих параллельно с общей памятью, то при реальных характеристиках увеличение производительности, возможно, не более чем в 3…4 раза с большим числом процессоров. Основная причина падения производительности на один процессор (снижение эффективности) в мультипроцессорных системах — сама архитектура вычислителя, предусматривающая общую память и последовательный к ней доступ. Поэтому разрабатываются варианты увеличения производительности с применением параллельных процессоров.
24
Идея параллельной обработки данных как мощного резерва увеличения производительности вычислительных аппаратов была высказана Чарльзом Бэббиджем примерно за сто лет до появления первого электронного компьютера. Однако уровень развития технологий середины 19-го века не позволил ему реализовать эту идею. С появлением первых электронных компьютеров эти идеи неоднократно становились отправной точкой при разработке самых передовых и производительных вычислительных систем. Без преувеличения можно сказать, что вся история развития высокопроизводительных вычислительных систем - это история реализации идей параллельной обработки на том или ином этапе развития компьютерных технологий, естественно, в сочетании с увеличением частоты работы электронных схем. Очевидно, что такие системы чрезвычайно дороги и изготавливаются в единичных экземплярах. Ну, а что же производится сегодня в промышленных масштабах? Широкое разнообразие производимых в мире компьютеров с большой степенью условности можно разделить на четыре класса:
персональные компьютеры (Personal Computer - PC);
рабочие станции (WorkStation - WS);
суперкомпьютеры (Supercomputer - SC);
кластерные системы.
Условность разделения связана в первую очередь с быстрым прогрессом в развитии микроэлектронных технологий. Производительность компьютеров в каждом из классов удваивается в последние годы примерно за 18 месяцев (закон Мура). В связи с этим, суперкомпьютеры начала 90-х годов зачастую уступают в производительности современным рабочим станциям, а персональные компьютеры начинают успешно конкурировать по производительности с рабочими станциями. Тем не менее, попытаемся каким-то образом классифицировать их.
Персональные компьютеры. Как правило, в этом случае подразумеваются однопроцессорные системы на платформе Intel или AMD, работающие под управлением однопользовательских операционных систем (Microsoft Windows и др.). Используются в основном как персональные рабочие места.
Рабочие станции. Это чаще всего компьютеры с RISC процессорами с многопользовательскими операционными системами, относящимися к семейству ОС UNIX. Содержат от одного до четырех процессоров. Поддерживают удаленный доступ. Могут обслуживать вычислительные потребности небольшой группы пользователей.
Суперкомпьютеры. Отличительной особенностью суперкомпьютеров является то, что это, как правило, большие и, соответственно, чрезвычайно дорогие многопроцессорные системы. В большинстве случаев в суперкомпьютерах используются те же серийно выпускаемые процессоры, что и в рабочих станциях. Поэтому зачастую различие между ними не столько качественное, сколько количественное. Например, можно говорить о 4-х процессорной рабочей станции фирмы SUN и о 64-х процессорном суперкомпьютере фирмы SUN. Скорее всего, в том и другом случае будут использоваться одни и те же микропроцессоры.
Кластерные системы. В последние годы широко используются во всем мире как дешевая альтернатива суперкомпьютерам. Система требуемой производительности собирается из готовых серийно выпускаемых компьютеров, объединенных опять же с помощью некоторого серийно выпускаемого коммуникационного оборудования.
Таким образом, многопроцессорные системы, которые ранее ассоциировались в основном с суперкомпьютерами, в настоящее время прочно утвердились во всем диапазоне производимых вычислительных систем, начиная от персональных компьютеров и заканчивая суперкомпьютерами на базе векторно-конвейерных процессоров. Это обстоятельство, с одной стороны, увеличивает доступность суперкомпьютерных технологий, а, с другой, повышает актуальность их освоения, поскольку для всех типов многопроцессорных систем требуется использование специальных технологий программирования для того, чтобы программа могла в полной мере использовать ресурсы высокопроизводительной вычислительной системы. Обычно это достигается разделением программы с помощью того или иного механизма на параллельные ветви, каждая из которых выполняется на отдельном процессоре.