

If (скалярний логічне вираз)
Умовний оператор.
num_threads (скалярний цілий вираз)
Задає кількість ниток. Альтернативний спосіб завдання кількості ниток забезпечує змінну оточення OMP_NUM_THREADS.
schedule (характер_распределения_итераций ([количество_итерацій_цикла])
Даний оператор задає спосіб розподілу ітерацій циклу між нитками: • static - кількість ітерацій циклу, переданих для виконання кожної нитки фіксоване і розподіляється між нитками за принципом кругового планування. Якщо кількість ітерацій не зазначено, воно вважається рівним 1; • dynamic - кількість ітерацій циклу, переданих для виконання кожної нитки фіксовано. Чергова «порція» ітерацій передається звільнилася нитки; • guided - кількість ітерацій циклу, переданих для виконання кожної нитки поступово зменшується. Чергова «порція» ітерацій передається звільнилася нитки; • runtime - тип розподілу роботи визначається під час виконання програми, наприклад, за допомогою змінної оточення OMP_SCHEDULE. copyin (список імен common-блоків). При виконанні цього оператора дані з головної нитки копіюються в локальні екземпляри common-блоку на початку кожної паралельної секції. Імена задаються міжсимволами «/».
Підпрограми OpenMP
Підпрограми, що формують середовище виконання паралельної програми Тут і далі спочатку наводиться інтерфейс підпрограм OpenMP для мови C, потім для мови Fortran.
void omp_set_num_threads (int threads); subroutine omp_set_num_threads (threads) integer threads
Задає кількість потоків (threads) при виконанні паралельних секцій програми.
int omp_get_num_threads (void); integer function omp_get_num_threads ()
Повертає кількість потоків, використовуваних для виконання паралельної секції.
int omp_get_max_threads (void); integer function omp_get_max_threads ()
Повертає максимальну кількість потоків, які можна використовувати для виконання паралельних секцій програми.
int omp_get_thread_num (void); integer function omp_get_thread_num ()
Повертає ідентифікатор нитки, з якої викликається дана функція.
int omp_get_num_procs (void); integer function omp_get_num_procs ()
Повертає кількість процесорів, доступних в даний момент програмі.
int omp_in_parallel (void); logical function omp_in_parallel ()
Повертає значення true при виклику з активної паралельної секції програми.
void omp_set_dynamic (int threads); subroutine omp_set_dynamic (threads) logical threads
Включає або відключає можливість динамічного призначення кількості потоків при виконанні паралельної секції. За замовчуванням ця можливість відключена.
int omp_get_dynamic (void); logical function omp_get_dynamic ()
Повертає значення true, якщо динамічне призначення кількості потоків дозволено.
void omp_set_nested (int nested); subroutine omp_set_nested (nested) integer nested
Дозволяє або забороняє вкладений паралелізм. За замовчуванням вкладений паралелізм заборонений.
int omp_get_nested (void); logical function omp_get_nested ()
Визначає, чи дозволений вкладений паралелізм.
Підпрограми для роботи з блокуваннями
Блокування використовуються для запобігання ефектів, що призводять до непередбачуваного (Недетермінірованного) поведінки програми. Серед таких ефектів, наприклад, гонки за даними, коли більш ніж один потік має доступ до однієї і тієї ж змінної.
void omp_init_lock (omp_lock_t * lock); subroutine omp_init_lock (lock) integer (kind = omp_lock_kind) :: lock
Ініціалізує блокування, пов'язану з ідентифікатором lock, для використання в наступних викликах підпрограм.
void omp_destroy_lock (omp_lock_t * lock); subroutine omp_destroy_lock (lock) integer (kind = omp_lock_kind) :: lock
Перекладає блокування, пов'язану з ідентифікатором lock, в стан невизначеності.
void omp_set_lock (omp_lock_t * lock); subroutine omp_set_lock (lock) integer (kind = omp_lock_kind) :: lock
Перекладає потоки зі стану виконання в стан очікування до тих пір, поки блокування, пов'язана з ідентифікатором lock, не виявиться оступною. Потік стаєвласником доступною блокування.
void omp_unset_lock (omp_lock_t * lock); subroutine omp_unset_lock (lock) integer (kind = omp_lock_kind) :: lock
Після виконання даного виклику потік перестає бути власником блокування, пов'язаної з ідентифікатором lock. Якщо потік не був власником блокування, результат виклику не визначений.
int omp_test_lock (omp_lock_t * lock); logical function omp_test_lock (lock) integer (kind = omp_lock_kind) :: lock
Повертає значення «істина», якщо блокування пов'язана з ідентифікатором lock.
void omp_init_nest_lock (omp_nest_lock_t * lock); subroutine omp_init_nest_lock (lock) integer (kind = omp_nest_lock_kind) :: lock
Ініціалізує вкладену блокування, пов'язану з ідентифікатором lock.
void omp_destroy_nest_lock (omp_nest_lock_t * lock); subroutine omp_destroy_nest_lock (lock) integer (kind = omp_nest_lock_kind) :: lock
Перекладає вкладену блокування, пов'язану з ідентифікатором lock, в стан невизначеності.
void omp_set_nest_lock (omp_nest_lock_t * lock); subroutine omp_set_nest_lock (lock) integer (kind = omp_nest_lock_kind) :: lock
Перекладає виконуються потоки в стан очікування до тих пір, поки вкладена блокування, пов'язана з ідентифікатором lock, не стане доступною. Потік стає власником блокування.
void omp_unset_nest_lock (omp_nest_lock_t * lock); subroutine omp_unset_nest_lock (lock) integer (kind = omp_nest_lock_kind) :: lock
Звільняє виконується потік від володіння вкладеної блокуванням, пов'язаної ідентифікатором lock. Якщо потік не був власником блокування, результат не визначений.
int omp_test_nest_lock (omp_nest_lock_t * lock); integer function omp_test_nest_lock (lock) integer (kind = omp_nest_lock_kind) :: lock
Функція, що дозволяє визначити, чи пов'язана вкладена блокування з ідентифікатором lock. Якщо пов'язана, повертається значення лічильника, в іншому випадку повертається значення 0.
Таймери
Для профілювання OpenMP програми можна використовувати таймери.
double omp_get_wtime (void); double precision function omp_get_wtime ()
Повертає час у секундах, що минув з довільного моменту в минулому. Точка відліку залишається незмінною протягом усього часу виконання програми.
double omp_get_wtick (void); double precision function omp_get_wtick ()
Повертає час у секундах, що минув між послідовними «тиками». Цей час є мірою точності таймера.
Змінні оточення OpenMP
Змінні оточення задаються наступним чином:
• export ЗМІННА = значення (в середовищі UNIX)
• set ЗМІННА = значення (в середовищі Microsoft Windows)
OMP_NUM_THREADS
Задає кількість ниток при виконанні паралельних секцій програми.
OMP_SCHEDULE
Задає спосіб розподілу ітерацій циклів між нитками. Можливі значення:
• static;
• dynamic;
• guided.
Кількість ітерацій (необов'язковий параметр) вказується після одного з цих ключових слів, відділяючись від нього комою, наприклад:
Export OMP_ SCHEDULE = "static, 10"OMP_DYNAMIC
Якщо цієї змінної присвоєно значення false, динамічний розподіл ітерацій циклів між нитками заборонено, якщо true - дозволено.
OMP_NESTED
Якщо цієї змінної присвоєно значення false, вкладений паралелізм заборонений, якщо true – дозволено
1.2 MPI
MPI-програма являє собою набір незалежних процесів,кожен з яких виконує свою власну програму (неnобов'язково одну і ту ж), написану на мові C або FORTRAN. З'явилися реалізації MPI для C + +, проте розробники стандарту MPI за них відповідальності не несуть. Процеси M P I-програми взаємодіють один з одним за допомогою виклику комунікаційних процедур. Як правило, кожен процес виконується у своєму власному адресному просторі, однак допускається і режим поділу пам'яті.
MPI не специфікує модель виконання процесу - це може бути як послідовний процес, так і багатопотокових. MPI ненадає ніяких засобів для розподілу процесів по обчислювальним вузлам і для запуску їх на виконання. Ці функції покладаються або на операційну систему, або на програміста. Зокрема, на n CUBE 2 використовується стандартна команда xnc, а на кластерах - спеціальний командний файл (зкріпт) mpirun, який припускає, що виконані модулі вже якимось чином розподілені по комп'ютерах кластера. MPI не накладає жодних обмежень на те, що процеси будуть розподілені по процесорах, зокрема, можливий запуск MPI-програми з декількома процесами на звичайній однопроцесорній системі.
Для ідентифікації наборів процесів вводиться поняття группи, об'єднує всі або якусь частину процесів. Кожна група утворює область связі, з якою пов'язують спеціальний об'єкт коммунікатор галузі зв'язку. Процеси всередині групи нумеруються цілим числом в діапазоні 0. . groupsize - 1. Всі комунікаційні операції з деяким комунікатором будуть виконуватися тільки всередині галузі зв'язку, описуваної цим комунікатором. При ініціалізації MPI створюється зумовлена область зв'язку, що містить всі процеси MPI-програми, з якою пов'язують зумовлений комунікатор MPI_COMM_WORLD. У більшості випадків на кожному процесорі запускається один окремий процес, і тоді терміни процесі процесор стають синонімами, а величина groupsize стає рівній NPROCS - числу процесорів, виділених завданню. В подальшому обговоренні ми будемо розуміти саме таку ситуацію і не будемо дуже вже строго стежити за термінологією. Отже, якщо сформулювати коротко, MPI - це бібліотека функцій, забезпечує взаємодію паралельних процесів за допомогою механізму передачі повідомлень. Це досить об'ємна і складна бібліотека, що складається приблизно з 130 функцій, у число яких входять:
- функції ініціалізації та закриття MPI-процесів;
- функції, що реалізують комунікаційні операції типу точка- точка;
- функції, що реалізують колективні операції;
- функції для роботи з групами процесів і комунікаторами;
- функції для роботи зі структурами даних;
- функції формування топології процесів.
Набір функцій бібліотеки MPI далеко виходить за рамки набору функцій, мінімально необхідного для підтримки механізму передачі повідомлень, описаного в першій частині. Однак складність цієї бібліотеки не повинна лякати користувачів, оскільки, в кінцевому підсумку, все це безліч функцій призначено для полегшення розробки ефективних паралельних програм. Зрештою, користувачеві належить право самому вирішувати, які кошти з наданого арсеналу використовувати, а які ні. В принципі, будь-яка паралельна програма може бути написана з використанням всього 6 MPI-функцій, а достатньо повну і зручне середовище програмування становить набір з 24 функцій. Кожна з MPI функцій характеризується способом виконання:
1. Локальна функція - виконується всередині викликає процесу. Її завершення не вимагає комунікацій.
2. Нелокальная функція - для її завершення потрібне виконання MPI-процедури іншим процесом.
3. Глобальна функція - процедуру повинні виконувати всі процеси групи. Недотримання цієї умови може призводити до зависання завдання.
4. Блокувальна функція - повернення управління з процедури гарантує можливість повторного використання параметрів,беруть участь у виклику. Ніяких змін в стані процесу, викликав блокуючий запит, до виходу з процедури не може відбуватися.
5. Не блокувальна функція - повернення з процедури відбувається негайно, без очікування закінчення операції і до того, як буде дозволено повторне використання параметрів, що беруть участь в запиті.
Завершення неблокирующих операцій здійснюється спеціальними функціями. Використання бібліотеки MPI має деякі відмінності у мовах C і FORTRAN. У мові C всі процедури є функціями, і більшість з них повертає код помилки. При використанні імен підпрограм і іменованих констант необхідно строго дотримувати регістр символів. Масиви індексуються з 0. Логічні змінні представляються типом int (true відповідає 1, а false - 0). Визначення всіх іменованих констант, прототипів функцій і визначення типів виконується підключенням файлу mpi. h. Введення власних типів у MPI було продиктовано тим обставиною, що стандартні типимов на різних платформах мають різне уявлення. MPI допускає можливість запуску процесів паралельної програми на комп'ютерах різних платформ, забезпечуючи при цьому автоматичне перетворення даних при пересиланнях. У таблиці наведено відповідність зумовлених в MPI типів стандартних типів мови С.
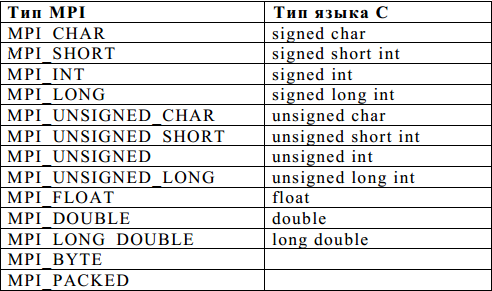
БАЗОВІ ФУНКЦІЇ MPI
Будь яка прикладна MPI-програма (додаток) повинна починатися з виклику функції ініціалізації MPI-функції MPI_Init. В результаті виконання цієї функції створюється група процесів, в яку поміщаються всі процеси додатки, створюється область зв’язку, об’єднує всі процеси-додатки. Процеси у групі впорядковані пронумеровані від 0 до groupsize 1, де groupsize одне число процесів у групі. Крім цього створюється зумовлений комунікатор MPI_COMM_SELF, що описує свою область зв’язку для кожного окремого процесу.
int MPI _ Init (int*argc , char* * * argv )
У програмах на C кожному процесу при ініціалізації передаються аргументи функції main, отримані з командного рядка.
Функція завершення MPI-програм MPI _ Finalize:
int MPI_ Finalize ( void )
Функція закриває все MPI-процеси і ліквідує всі галузі зв'язку.
Функція визначення числа процесів в галузі зв'язку
MPI _ Comm _ size int MPI _ Comm _ size (MPI _ Commcomm, int * size)
Функція повертає кількість процесів у галузі зв'язку комунікатора comm. До створення явно груп і пов'язаних з ними комуністичної катори єдино можливими значеннями параметра COMM є MPI _COMM _W ORLD і MPI _COMM _SELF, які створюються автоматично при ініціалізації MPI.
Підпрограма є локальною.
Функція визначення номера процесу MPI _ C omm _ rank
int MPI _ Comm _ rank (MPI _ Commcomm, int * rank)
Функція повертає номер процесу, що викликав цю функцію. Номери процесів лежать в діапазоні 0. . size - 1 (значення size може бути визначено за допомогою попередньої функції). Підпрограма є локальної.У мінімальний набір слід включити також дві функції передачі і прийому повідомлень.
Функція передачі повідомлення MPI _ S end
int MPI _ Send (void * buf, intcount, MPI _ Datatypedatatype, intdest, inttag, MPI _ Commcomm)
Функція виконує посилку count елементів типу datatype повідомлення з ідентифікатором tag процесу dest в галузі зв'язку комунікатора comm. Мінлива buf - це, як правило, масив або скалярна змінна. В останньому випадку значення count = 1.
Функція прийому повідомлення MPI _ Recv
int MPI _ Recv (void * buf, intcount, MPI _ Datatypedatatype, intsource, inttag, MPI _Cmmcomm, MPI _ Status * status)