

4. Независимость от расположения
Основная идея независимости от расположения, или так называемой прозрачности
расположения, проста. Пользователи не должны знать, где именно данные хранятся физи- чески и должны поступать так (по крайней мере, с логической точки зрения), как если бы все данные хранились на их собственном локальном узле. Благодаря независимости от рас- положения упрощаются пользовательские программы и терминальные операции. В частно- сти, данные могут быть перенесены с одного узла на другой, и это не должно потребовать внесения каких-либо изменений в использующие их программы или действия пользовате- лей. Такая переносимость желательна, поскольку она позволяет перемещать данные в сети в соответствии с изменяющимися требованиями к эффективности работы системы.
Замечание. Нетрудно заметить, что независимость от расположения представляет собой простое расширение для распределенных систем обычной концепции физической независи- мости данных. Забегая несколько вперед, следует сказать, что на самом деле каждую из целей, в названии которой употреблено слово "независимость", можно рассматривать как расшире- ние обычной концепции физической независимости данных, в чем мы скоро убедимся. Мы еще возвратимся к вопросу независимости от расположения в разделе 20.4, в котором будет обсуждаться присвоение имен объектам (подраздел "Управление каталогом").
5. Независимость от фрагментации
Система поддерживает независимость от фрагментации, если данная переменная- отношение может быть разделена на части или фрагменты при организации ее физиче- ского хранения. Фрагментация желательна для повышения производительности системы. В этом случае данные могут храниться в том месте, где они чаще всего используются,
что позволяет достичь локализации большинства операций и уменьшения сетевого тра- фика. Например, рассмотрим переменную-отношение ЕМР с данными о служащих, со- держание которой представлено на рис. 20.2. В системе, которая поддерживает незави- симость от фрагментации, два фрагмента этой переменной-отношения можно опреде- лить следующим образом (см. нижнюю часть рис. 20.2).
FRAGMENT EMP AS N EMP AT SITE
'New York'
WHERE DEPTf * OR DEPTI = L EMP AT SITE 'London' WHERE DEPTI =
'Dl' 'D3' 'D2'
emp
|
emp# |
dept# |
salary |
|
e1 |
d1 |
40k |
|
e2 |
d1 |
42k |
|
e3 |
d2 |
30k |
|
e4 |
d2 |
35k |
|
e5 |
d3 |
48k |
Нью-Йорк
Лондон
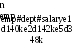
 Рис.
20.2. Пример фрагментации
Рис.
20.2. Пример фрагментации
Замечание. Здесь подразумевается, что кортежи служащих отображаются в физиче- ской памяти каким-то непосредственным способом; что номера служащих и номера от- делов представлены символьными строками, а размер заработной платы — числами; что Dl и D3 — отделы, расположенные в Нью-Йорке, a D2 — отдел, расположенный в Лондо- не. Таким образом, кортежи служащих из Нью-Йорка хранятся на узле в Нью-Йорке, а кортежи служащих из Лондона— на узле в Лондоне. Отметим, что внутрисистемные имена фрагментов — NJSMP и L_EMP.
Существует два основных вида фрагментации: горизонтальная и вертикальная; они соответствуют реляционным операциям выборки и проекции соответственно (на рис. 20.2 показан пример горизонтальной фрагментации). В более общем случае фраг- мент можно представить в виде произвольного сочетания операций выборки и проекции, но со следующими ограничениями.
В случае выборки это должна быть ортогональная декомпозиция в смысле, ука- занном в разделе 12.6 главы 12.
В случае проекции это должна быть декомпозиция без потерь в смысле, указан- ном в главах 11 и 12.
Благодаря этим двум правилам все фрагменты данной переменной-отношения будут независимыми, т.е. ни один из фрагментов не может быть представлен как производный от других фрагментов, а также не может иметь выборку или проекцию, которая была бы производной от других фрагментов. (Если действительно необходимо хранить одну и ту же часть данных в нескольких различных местах, можно воспользоваться системным механизмом репликации; см. следующий подраздел).
Восстановление исходной переменной-отношения из ее фрагментов выполняется с помощью соответствующих операций соединения и объединения (соединения— для вертикальных фрагментов, а объединения— для горизонтальных). Кстати, обратите внимание, что благодаря первому правилу в случае объединения операцию исключения дубликатов выполнять не потребуется.
Замечание. Необходимо сказать еще несколько слов относительно вертикальной фрагментации. Как утверждалось выше, несомненно, что такая фрагментация долж- на выполняться без потерь. Поэтому разбиение переменной-отношения ЕМР на фраг- менты-проекции, например, вида {EMPi,DEPTl} и {SALARY} было бы недопустимым. Однако в некоторых системах хранимые переменные-отношения рассматриваются как имеющие скрытый, предоставляемый системой атрибут "идентификатор корте- жа", или сокращенно — атрибут TID (tuple ID). Для каждого хранимого кортежа ат- рибут TID, грубо говоря, является адресом. Очевидно, что он является потенциаль- ным ключом для соответствующей переменной-отношения. Например, если бы пе- ременная-отношение ЕМР содержала такой атрибут, то она могла бы быть фрагмен- тирована на проекции {TID,EMPi,DEPTt} и {TID,SALARY}, поскольку такая фрагмен- тация уже, конечно, выполняется без потерь. Также обратите внимание, что если, например, атрибут TID является скрытым, то это никак не нарушает информацион- ный принцип, поскольку независимость от фрагментации означает, что пользователь не должен знать чего-либо о фрагментации.
Заметим, между прочим, что простота выполнения фрагментации и восстановле- ния — это две основные причины, по которым распределенные базы данных должны быть именно реляционными. Реляционная модель предоставляет все те операции, кото- рые необходимы для решения этих задач [20.15].
Теперь перейдем к главному вопросу. Система, которая поддерживает фраг- ментацию данных, должна поддерживать и независимость от фрагментации (иногда говорят "прозрачность фрагментации"). Другими словами, пользователи должны иметь возможность работать точно так, по крайней мере с логической точки зрения, как если бы данные в действительности были вовсе не фрагменти- рованы. Независимость от фрагментации (как и независимость от расположе- ния) — это весьма желательное свойство, поскольку она позволяет упростить раз- работку пользовательских программ и выполнение терминальных операций. В ча- стности, это гарантирует, что в любой момент данные могут быть заново восста- новлены (а фрагменты перераспределены) в ответ на изменение требований к эф- фективности работы системы, причем ни пользовательские программы, ни терми- нальные операции при этом не затрагиваются.
Таким образом, если обеспечивается независимость от фрагментации, пользователи получают данные в виде некоторого представления, в котором фрагменты логически скомбинированы с помощью соответствующих операций соединения и объединения. К обязанностям системного оптимизатора относится определение фрагментов, к которым
требуется физический доступ для выполнения любого из поступивших запросов пользо- вателя. В случае варианта фрагментации, показанного на рис. 20.2, пусть, например, пользователь выдает следующий запрос.
EMP WHERE SALARY > 40К AND DEPTt = «D1'
Из определений фрагментов (которые хранятся, конечно же, в каталоге) оптимизато- ру должно быть известно, что весь требуемый результат может быть получен только по данным узла в Нью-Йорке, а значит, нет никакой необходимости устанавливать связь с узлом из Лондона.
Рассмотрим этот пример более детально. Переменная-отношение ЕМР, как ее воспри- нимает пользователь, может рассматриваться (упрощенно) как некоторое представле- ние, построенное на основе базовых фрагментов N_EMP и L_EMP.
VAR EMP VIEW
N_EMP UNION L_EMP ;
Тогда оптимизатор преобразует исходный запрос пользователя в следующее выражение.
(N_EMP UNION L_EMP) WHERE SALARY > 40K AND DEPTt = 'Dl'
В процессе дальнейшей оптимизации это выражение будет преобразовано в сле- дующее выражение (поскольку операция выборки распределяется по объединению).
( N EMP WHERE SALARY > 40К AND DEPTi = 'Dl' ) UNION
( L_EMP WHERE SALARY > 40K AND DEPTi = 'Dl' )
Из определения фрагмента L_EMP в каталоге оптимизатору будет известно, что второй из этих двух операндов объединения в результате вычисления даст пустое отношение (условие DEPTt = 'Dl' AND DEPTt = 'D2' никогда не может быть истинным). Таким образом, все выражение может быть приведено к следующему виду.
N_EMP WHERE SALARY > 40К AND DEPTi = 'Dl'
Теперь оптимизатору станет ясно, что потребуется доступ лишь к данным узла в Нью-Йорке.
Упражнение. Рассмотрите, какие действия должен будет выполнить оптимизатор при обработке следующего запроса.
EMP WHERE SALARY > 4OK
Из предыдущего обсуждения следует, что проблема поддержки операций для фрагментированных переменных-отношений в некоторых вопросах пересекается с про- блемой поддержки операций представлений, определенных с помощью операций соеди- нения и объединения (фактически это одна и та же проблема — она лишь проявляется на разных уровнях общей системной архитектуры). В частности, проблема обновления фрагментированных переменных-отношений совпадает с проблемой обновления пред- ставлений, определенных с помощью операций соединения и объединения (см. главу 9). Отсюда следует, что обновление некоторого кортежа — опять же, если говорить нестро- го — может привести к тому, что кортеж будет перенесен из одного фрагмента в другой, если обновленный кортеж больше не удовлетворяет предикату для того фрагмента, кото- рому он принадлежал ранее.