

Классификация Флинна. Примеры.
Классификация Флинна предполагает в своей основе следующие два вида параллелизма: независимость потоков заданий (команд), существующих в системе, и независимость (несвязанность) данных, обрабатываемых в каждом потоке. Классификация до настоящего времени еще не потеряла своего значения. Однако, как и любая классификация, она носит временный и условный характер. Своим долголетием она обязана тому, что оказалась справедливой для ВС, в которых ЭВМ и процессоры реализуют программные последовательные методы вычислений. С появлением систем, ориентированных на потоки данных и использующих ассоциативную обработку, классификация может быть некорректной.
Согласно данной классификации существуют четыре основные архитектуры ВС, представленные на Рис. 2:
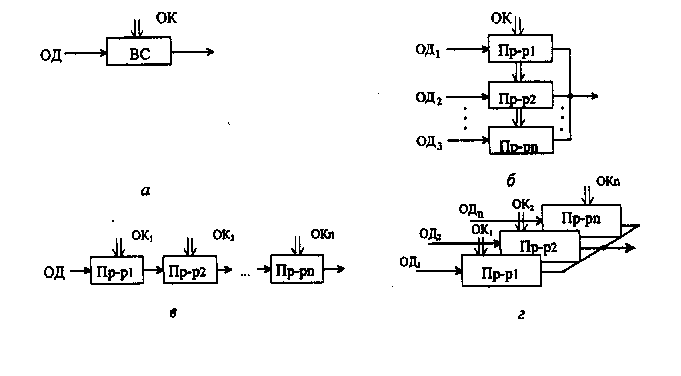
1) одиночный поток команд - одиночный поток данных (ОКОД), в английской аббревиатуре Single Instruction Single Data (SISD), - одиночный поток инструкций - одиночный поток данных;
2) одиночный поток команд - множественный поток данных (ОКМД), или Single Instruction Multiple Data (SIMD), - одиночный поток инструкций -множественный поток данных;
3) множественный поток команд - одиночный поток данных (МКОД), или Multiple Instruction Single Data (MISD), - множественный поток инструкций - одиночный поток данных;
4) множественный поток команд - множественный поток данных (МКМД), или Multiple Instruction Multiple Data (MIMD), - множественный поток инструкций - множественный поток данных.
Процессоры для ММПС – серийные и специализированные. Векторная обработка – принцип, 2 вида процессоров. Конвейер – основные понятия. Факторы снижения производительности. Строение векторных команд. Организация данных в памяти. Команды реорганизации и редукции.
Во многих случаях – серийные (Power PC, Intel). Чаще – векторные. Принцип векторных - одна операция над многими элементами данных (SIMD).
Реализация на скалярных – трудности:
- перед каждой операцией – вызов и декодирование команды;
- для каждой команды – вычислить адреса данных;
- обмен с памятью – возможна конкуренция;
- команды построения цикла затрудняют опережающий просмотр.
Устраняется путем введения векторных команд. 2 типа систем: Матричные состоят из множества ПЭ, организованных так, что они исполняют векторные команды, задаваемые одним устройством управления, каждый ПЭ работает с одним элементом данных.
Конвейерные системы - один или несколько конвейерных процессоров, выполняют векторные команды путем засылки в конвейер элементов вектора с интервалом = длительности стадии. Скорость вычислений зависит только от длительности стадии.
Типичная организация векторной системы:
- блок обработки команд - выбор и декодирование команд;
- векторный процессор - исполняет векторные команды;
- скалярный процессор - скалярные команды
- память.
Скалярные вычисления – чтение, сложение, запись, приращение-проверка, условный переход.
В общем случае время прохождения разных ступеней разное. Это снижает производительность. Для выравнивания нагрузки - 2 основных метода:
- межстадийная буферизация;
- дублирование медленных ФУ.
Существует ряд факторов, снижающих производительность системы, в частности:
- закон Амдаля;
- накладные расходы на старт конвейера;
- зависимости по данным и особенно по управлению.
- размер буфера команд. Его объем должен быть достаточен для постоянной подпитки управляющих устройств.
- размер буфера данных. Для сокращения времени доступа к памяти – расслоение на несколько банков и обеспечение параллельного доступа к ним.