

Анализ производительности программы в целом. Усложняющие факторы. Пример.
Анализ производительности.
При компиляции комплектов, составляющих программу, следует рассмотреть, как соединены их модели производительности.
В случае последовательной композиции перераспределение данных не требуется, и общее время получается простым суммированием.
На практике анализ производительности программ, полученных в результате объединения нескольких комплектов, усложняется следующими факторами:
Увеличение объема вычислений. Передача данных между модулями требует дополнительных вычислений, повышая таким образом затраты времени на вычисления.
Снижение времени простоя. Поскольку время простоя – это время, когда процессоры не выполняют ни вычислений, ни коммуникаций, объем этого времени можно снизить, используя конкурентную композицию, за счет перекрытия вычислений и коммуникаций.
Увеличение объема коммуникаций. Комплекты часто требуют дополнительных коммуникаций. В последовательной композиции – для перераспределения данных; в параллельной – для перемещения данных между процессорами.
Увеличение степени дробления.
Дисбаланс нагрузки. Параллельный комплект может увеличить время простоя, если вычислительные ресурсы, назначенные различным комплектам, не позволяют выполнить их одновременно. В этом случае один из модулей выполняет задание раньше других и вынужден ждать завершения работы остальных.
В качестве примера разработаем библиотечный модуль, независимый от распределения данных, рассмотрим умножение матрицы на матрицу.
![]()
Библиотека должна обеспечивать умножение при распределении массивов А, B и C одним из трех способов – по колонкам, по строкам и двухмерное. Интерфейс должен обеспечивать работу в SPMD. Основной вопрос – должна ли библиотека обеспечивать различные алгоритмы для трех случаев или она должна выполнять явное перераспределение данных?
1 – распределение по колонкам (одномерное) – задача получает данные по одной колонке из А, В и рассчитывает одну колонку С
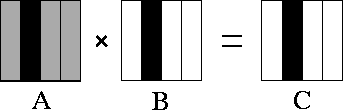
Каждой задаче требуется вся матрица А. N2/P данных требуется от каждой из P-1 других задач , требуемые затраты на коммуникацию:
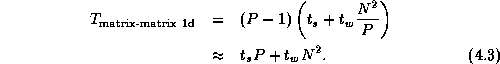
Всего вычислений О( N3), пойдет на каждую задачу - N3/P
2 – двухмерная декомпозиция.
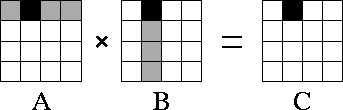
Для расчета одного элемента С требуется одна строка А и одна колонка В
Всего получается N2/ÖP данных (обмен)
Нужно опр стратегию коммуникаций.
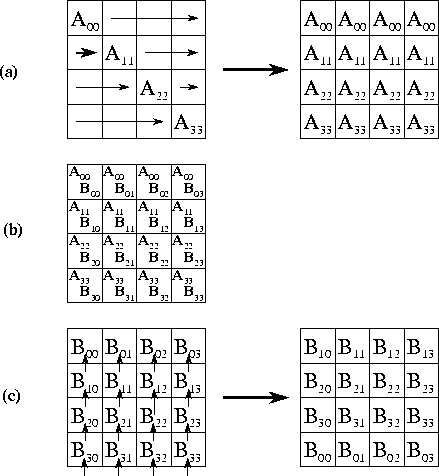
Каждый из ÖP – 1 шагов этого алгоритма включает раздачу данных ÖP – 1 задачам (для А’) и коммуникацию с ближайшими соседями для В’. Каждый обмен включает N2/P данных.
Средства разработки параллельных программ. Классификация. Pvm – характеристика и идеология. Основные функции.
Параллельную виртуальную машину можно определить как часть средств реального вычислительного комплекса, предназначенную для выполнения множества задач, участвующих в получении общего результата вычислений. В общем случае число задач может превосходить число процессоров, включенных в PVM. Кроме того, в состав PVM можно включать довольно разнородные вычислительные машины, несовместимые по системам команд и форматам данных. Параллельной Виртуальной Машиной может стать как отдельно взятый ПК, так и локальная сеть. Важно лишь, чтобы о включаемых в PVM вычислительных средствах имелась информация в ПО PVM. Благодаря этому программному обеспечению пользователь может считать, что он общается с одной вычислительной машиной, в которой возможно параллельное выполнение множества задач.
Функционирование PVM существенно опирается на возможность обмена информацией между задачами, выполняемыми в ней. Кроме задачи распараллеливания вычислений с необходимостью возникает и задача управления вычислительным процессом, координации действий задач - участников этого процесса. Иногда для управления приходится создавать специальную задачу, которая сама не участвуя в вычислениях, обеспечивает согласованную работу остальных задач - вычислителей.
Главным критерием качества распараллеливания вычислений является сокращение общего времени решения задачи.
Один вариант организации параллельных вычислений - все задачи запускаются одной командой PVM, в которой указывается имя запускаемого исполняемого файла, число запускаемых задач, а также число и тип используемых процессоров. По этой команде запускаются на указанных процессорах требуемое число копий указанного исполняемого файла.
Другой вариант - сначала запускается одна задача (master), которая в коллективе задач будет играть функции координатора работ. Эта задача производит некоторые подготовительные действия, после чего запускает остальные задачи (slaves), которым может соответствовать либо тот же исполняемый файл, либо разные исполняемые файлы.
В системе PVM_3 каждая задача, запущенная на некотором процессоре, идентифицируется целым числом TID. Отметим, что копии одного исполняемого файла, запущенные параллельно на N процессорах PVM, создают N задач с разными TID.
Для принятой модели взаимодействия задач в PVM считается, что в пределах одной PVM любая задача может передавать сообщения любой другой задаче, причем, размеры и число таких сообщений в принципе не ограничены.
Кроме обмена сообщениями между двумя задачами в PVM предусмотрены возможность широковещательной передачи сообщений от одной задачи к нескольким другим задачам, а также возможности синхронизации действий в группе задач и совместное выполнение задачами группы некоторых операций над распределенными данными.
Групповые функции являются эффективным средством для координации действий множества задач в PVM. Они позволяют любому подмножеству выполняемых задач объединиться в группу, которая идентифицируется по имени, заранее известному ее членам, и организовать внутри группы такие виды взаимодействия задач как синхронизация действий, обмен сообщениями и совместное выполнение глобальных операций.
Функции:
Управление задачами
int tid = pvm_mytid( void )
получить идентификатор процесса
int info = pvm_exit( void )
завершить работу c PVM
int numt
запускает в PVM n копий исполняемого файла с одинаковыми аргументами командной строки и возвращает число запущенных задач.
int info = pvm_kill( int tid )
завершает выполнение задачи по идентификатору.
Функции для работы с буферами
int bufid = pvm_mkbuf( int encoding )
создает новый пустой передающий буфер.
int info = pvm_freebuf( int bufid )
уничтожает буфер.
int bufid = pvm_getsbuf( void )
возвращает идентификатор активного передающего буфера.
int bufid = pvm_getrbuf( void )
возвращает идентификатор активного приемного буфера.
int oldbuf = pvm_setsbuf( int bufid )
переключает активный передающий буфер.
Функции для упаковки сообщений
Функции для передачи и приема сообщений
int info = pvm_send( int tid, int msgtag )
посылает сообщение задаче по идентификатору
int info = pvm_mcast( int *tids, int ntask, int msgtag )
посылает сообщение множеству задач по идентификаторам.
int info = pvm_psend( int tid, int msgtag, void *vp, int cnt, int type )
упаковывает и посылает сообщение.
int bufid = pvm_recv( int tid, int msgtag)
осуществляет блокирующий прием.
int bufid = pvm_nrecv( int tid, int msgtag )
осуществляет неблокирующий прием.
int bufid = pvm_probe( int tid, int msgtag )
проверяет, поступило ли ожидаемое сообщение.
Распаковка данных из принятого сообщения
int info
Групповые функции
int inum = pvm_joingroup( char *group )
присоединяет задачу к группе.
int info = pvm_bcast( char *group, int msgtag )
посылает всем членам группы сообщение
int info = pvm_lvgroup( char *group )
покинуть группу
int size = pvm_gsize( char *group )
размер группы
Информационные функции
int tid = pvm_parent( void )
возвращает tid родительского процесса
MPI – характеристика. Основные понятия. Отличия от PVM. Основные функции.
MPI - интерфейс передачи сообщений. Модель программирования MPI предполагает наличие 1 или более процессов, которые обмениваются информацией между собой, вызывая функции библиотеки MPI. В большинстве реализаций MPI при инициализации создается фиксированный набор процессов, по 1 на проц-р. В отличие от PVM, динамическое создание и уничтожение процессов не предусмотрено. Процессы MPI могут выполнять различные программы. Т.о. это соответствует модели MPMD, а не SPMD. Поэтому основной упор делается на механизмы коммуникации между процессами. Предусмотрены 2-точечный и групповой обмен сообщениями, синхронный и асинхронный прием и передача, пакетные прием и передача, а также совмещение приема и передачи. Понятие коммуникатора обеспечивает возможности модульного программирования, т.е. дает возможность инкапсулировать структуру коммуникаций внутри модуля. Написанные таким образом модули могут быть объединены последовательным и параллельным способами.
- Номер процесса - целое неотрицательное число, являющееся уникальным атрибутом каждого процесса;
- Атрибуты сообщения - это номер процесса-отправителя, номер процесса-получателя и идентификатор сообщения. Для них заведена структура MPI_Status, содержащая три поля: MPI_Source (номер процесса отправителя), MPI_Tag (идентификатор сообщения), MPI_Error (код ошибки); могут быть и добавочные поля
- Идентификатор сообщения (msgtag) - атрибут сообщения, являющийся целым неотрицательным числом, лежащим в диапазоне от 0 до 32767
- Группа процессов в отличие от PVM, где группы конструируются "снизу вверх", путем объединения нескольких процессов, выполнивших вызов pvm_joingroup(имя), в MPI группы создаются "сверху вниз", путем перечисления нескольких членов уже существующей группы. Для этого должна существовать некая "всеобщая" группа.
Функции:
MPI_Init - инициализация параллельной части приложения. Реальная инициализация для каждого приложения выполняется не более одного раза, а если MPI уже был инициализирован, то никакие действия не выполняются и происходит немедленный возврат из подпрограммы. Все оставшиеся MPI-процедуры могут быть вызваны только после вызова MPI_Init.
MPI_Finalize - завершение параллельной части приложения. Все последующие обращения к любым MPI-процедурам, в том числе к MPI_Init, запрещены. К моменту вызова MPI_Finalize некоторым процессом все действия, требующие его участия в обмене сообщениями, должны быть завершены.
int MPI_Comm_size
Определение общего числа параллельных процессов в группе comm.
int MPI_Comm_rank
Определение номера процесса в группе comm.
Прием/передача сообщений с блокировкой
Прием/передача сообщений без блокировки
Объединение запросов на взаимодействие
Процедуры данной группы позволяют снизить накладные расходы, возникающие в рамках одного процессора при обработке приема/передачи и перемещении необходимой информации между процессом и сетевым контроллером. Несколько запросов на прием и/или передачу могут объединяться вместе для того, чтобы далее их можно было бы запустить одной командой. Способ приема сообщения никак не зависит от способа его посылки: сообщение, отправленное с помощью объединения запросов либо обычным способом, может быть принято как обычным способом, так и с помощью объединения запросов.
Коллективные взаимодействия процессов
В операциях коллективного взаимодействия процессов участвуют все процессы коммуникатора. Соответствующая процедура должна быть вызвана каждым процессом, быть может, со своим набором параметров. Возврат из процедуры коллективного взаимодействия может произойти в тот момент, когда участие процесса в данной операции уже закончено.
int MPI_Bcast
Рассылка сообщения от процесса source всем процессам, включая рассылающий процесс.
int MPI_Gather
Сборка данных со всех процессов в буфере rbuf процесса dest.
Синхронизация процессов
int MPI_Barrier
Блокирует работу процессов, вызвавших данную процедуру, до тех пор, пока все оставшиеся процессы группы comm также не выполнят эту процедуру.
Работа с группами процессов
int MPI_Comm_split. Данная процедура разбивает все множество процессов, входящих в группу comm, на непересекающиеся подгруппы - одну подгруппу на каждое значение параметра color (неотрицательное число).
int MPI_Comm_free
Уничтожает группу, ассоциированную с идентификатором comm, который после возвращения устанавливается в MPI_COMM_NULL.