

Краткое заключение
О TCP/IP можно было бы рассказать много больше, но есть три ключевых момента:
TCP/IP - это набор протоколов, которые позволяют физическим сетям объединяться вместе для образования Internet. TCP/IP соединяет индивидуальные сети для образования виртуальной вычислительной сети, в которой отдельные главные компьютеры идентифицируются не физическими адресами сетей, а IP-адресами.
В TCP/IP используется многоуровневая архитектура, которая четко описывает, за что отвечает каждый протокол. TCP и UDP обеспечивают высокоуровневые служебные функции передачи данных для сетевых программ, и оба опираются на IP при передаче пакетов данных. IP отвечает за маршрутизацию пакетов до их пункта назначения.
Данные, перемещающиеся между двумя прикладными программами, работающими на главных компьютерах Internet, "путешествуют" вверх и вниз по стекам TCP/IP на этих компьютерах. Информация, добавленная модулями TCP/IP на стороне отправителя, "разрезается" соответствующими TCP/IP-модулями на принимающем конце и используется для воссоздания исходных данных.
Структура протоколов TCP/IP приведена на рисунке 1.4. Протоколы TCP/IP делятся на 4 уровня.
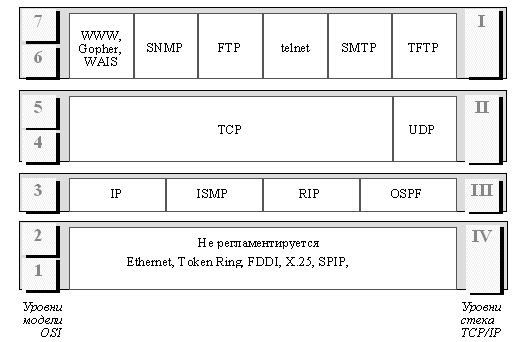
Рис. 1.4. Стек TCP / IP
Самый нижний (уровень IV) - уровень межсетевых интерфейсов - соответствует физическому и канальному уровням модели OSI. Этот уровень в протоколах TCP/IP не регламентируется, но поддерживает все популярные стандарты физического и канального уровня: для локальных каналов это Ethernet, Token Ring, FDDI, для глобальных каналов - собственные протоколы работы на аналоговых коммутируемых и выделенных линиях SLIP/PPP, которые устанавливают соединения типа "точка - точка" через последовательные каналы глобальных сетей, и протоколы территориальных сетей X.25 и ISDN. Разработана также специальная спецификация, определяющая использование технологии ATM в качестве транспорта канального уровня.
Следующий уровень (уровень III) - это уровень межсетевого взаимодействия, который занимается передачей дейтаграмм с использованием различных локальных сетей, территориальных сетей X.25, линий специальной связи и т. п. В качестве основного протокола сетевого уровня (в терминах модели OSI) в стеке используется протокол IP, который изначально проектировался как протокол передачи пакетов в составных сетях, состоящих из большого количества локальных сетей, объединенных как локальными, так и глобальными связями. Поэтому протокол IP хорошо работает в сетях со сложной топологией, рационально используя наличие в них подсистем и экономно расходуя пропускную способность низкоскоростных линий связи. Протокол IP является дейтаграммным протоколом.
К уровню межсетевого взаимодействия относятся и все протоколы, связанные с составлением и модификацией таблиц маршрутизации, такие как протоколы сбора маршрутной информации RIP (Routing Internet Protocol) и OSPF (Open Shortest Path First), а также протокол межсетевых управляющих сообщений ICMP (Internet Control Message Protocol). Последний протокол предназначен для обмена информацией об ошибках между маршрутизатором и шлюзом, системой-источником и системой-приемником, то есть для организации обратной связи. С помощью специальных пакетов ICMP сообщается о невозможности доставки пакета, о превышении времени жизни или продолжительности сборки пакета из фрагментов, об аномальных величинах параметров, об изменении маршрута пересылки и типа обслуживания, о состоянии системы и т.п.
Следующий уровень (уровень II) называется основным. На этом уровне функционируют протокол управления передачей TCP (Transmission Control Protocol) и протокол дейтаграмм пользователя UDP (User Datagram Protocol). Протокол TCP обеспечивает устойчивое виртуальное соединение между удаленными прикладными процессами. Протокол UDP обеспечивает передачу прикладных пакетов дейтаграммным методом, то есть без установления виртуального соединения, и поэтому требует меньших накладных расходов, чем TCP.
Верхний уровень (уровень I) называется прикладным. За долгие годы использования в сетях различных стран и организаций стек TCP/IP накопил большое количество протоколов и сервисов прикладного уровня. К ним относятся такие широко используемые протоколы, как протокол копирования файлов FTP, протокол эмуляции терминала telnet, почтовый протокол SMTP, используемый в электронной почте сети Internet и ее российской ветви РЕЛКОМ, гипертекстовые сервисы доступа к удаленной информации, такие как WWW и многие другие. Остановимся несколько подробнее на некоторых из них, наиболее тесно связанных с тематикой данного курса.
Протокол SNMP (Simple Network Management Protocol) используется для организации сетевого управления. Проблема управления разделяется здесь на две задачи. Первая задача связана с передачей информации. Протоколы передачи управляющей информации определяют процедуру взаимодействия сервера с программой-клиентом, работающей на хосте администратора. Они определяют форматы сообщений, которыми обмениваются клиенты и серверы, а также форматы имен и адресов. Вторая задача связана с контролируемыми данными. Стандарты регламентируют, какие данные должны сохраняться и накапливаться в шлюзах, имена этих данных и синтаксис этих имен. В стандарте SNMP определена спецификация информационной базы данных управления сетью. Эта спецификация, известная как база данных MIB (Management Information Base), определяет те элементы данных, которые хост или шлюз должен сохранять, и допустимые операции над ними.
Протокол пересылки файлов FTP (File Transfer Protocol) реализует удаленный доступ к файлу. Для того, чтобы обеспечить надежную передачу, FTP использует в качестве транспорта протокол с установлением соединений - TCP. Кроме пересылки файлов протокол, FTP предлагает и другие услуги. Так пользователю предоставляется возможность интерактивной работы с удаленной машиной, например, он может распечатать содержимое ее каталогов, FTP позволяет пользователю указывать тип и формат запоминаемых данных. Наконец, FTP выполняет аутентификацию пользователей. Прежде, чем получить доступ к файлу, в соответствии с протоколом пользователи должны сообщить свое имя и пароль.
В стеке TCP/IP протокол FTP предлагает наиболее широкий набор услуг для работы с файлами, однако он является и самым сложным для программирования. Приложения, которым не требуются все возможности FTP, могут использовать другой, более экономичный протокол - простейший протокол пересылки файлов TFTP (Trivial File Transfer Protocol). Этот протокол реализует только передачу файлов, причем в качестве транспорта используется более простой, чем TCP, протокол без установления соединения - UDP.
Протокол telnet обеспечивает передачу потока байтов между процессами, а также между процессом и терминалом. Наиболее часто этот протокол используется для эмуляции терминала удаленной ЭВМ.
Сеть Интернет, являющаяся сетью сетей и объединяющая громадное количество различных локальных, региональных и корпоративных сетей, функционирует и развивается благодаря использованию единого принципа маршрутизации и транспортировки данных. Маршрутизация данных. Маршрутизация данных обеспечивает передачу информации между компьютерами сети. Рассмотрим принцип маршрутизации данных по аналогии с передачей информации с помощью обычной почты. Для того чтобы письмо дошло по назначению, на конверте указывается адрес получателя (кому письмо) и адрес отправителя (от кого письмо). Аналогично, передаваемая по сети информация «упаковывается в конверт», на котором «пишутся» Интернет-адреса компьютеров получателя и отправителя, например «Кому: 198.78.213.185», «От кого: 193.124.5.33». Содержимое конверта на компьютерном языке называется Интернет-пакетом и представляет собой набор байтов. В процессе пересылки обыкновенных писем они сначала доставляются на ближайшее к отправителю почтовое отделение, а затем передаются по цепочке почтовых отделений на ближайшее к получателю почтовое отделение. На промежуточных почтовых отделениях письма сортируются, т.е. определяется, на какое следующее почтовое отделение необходимо отправить то или иное письмо. Интернет пакеты на пути к компьютеру-получателю также проходят через многочисленные промежуточные серверы Интернета, на которых производится операция маршрутизации. В результате маршрутизации Интернет-пакеты направляются от одного сервера Интернета к другому, постепенно приближаясь компьютеру-получателю.
Маршрутизация Интернет-пакетов обеспечивает доставку информации от компьютера-отправителя к компьютеру-получателю.
Транспортировка данных. Теперь представим себе, что нам необходимо переслать по почте многостраничную рукопись, а почта бандероли и посылки не принимает. Идея проста: если рукопись не помещает в обычный конверт, ее надо разобрать на листы и переслать их в нескольких конвертах. При этом листы рукописи необходимо обязательно пронумеровать, чтобы получатель знал, в какой последовательности потом эти листы собрать. В Интернете часто случается аналогичная ситуация, когда компьютеры обмениваются большими по объему файлами. Если послать такой файл целиком, то он может надолго «закупорить» канал связи, сделать его недоступным для пересылки других сообщений Для того чтобы этого не происходило, на компьютере-отправителе необходимо разбить большой файл на мелкие части, пронумеровать их и транспортировать в форме отдельных Интернет-пакетов до компьютера-получателя. На компьютере-получателе необходимо собрать исходный файл из отдельных частей в правильной последовательности, поэтому файл не может быть собран до тех пор, пока не придут все Интернет-пакеты. Трассировка данных — производится путем разбиения файлов на Интернет-пакеты на компьютере-отправителе, индивидуальной маршрутизации каждого пакета и сборки файлов из пакетов в первоначальном порядке на компьютере-получателе.
Время транспортировки отдельных Интернет-пакетов между локальным компьютером и сервером Интернета можно определить с помощью специальных программ.
Маршрутизация и транспортировка данных в Интернете производится на основе протокола TCP/IP, который является основным «законом» Интернета. Термин TCP/IP включает название двух протоколов передачи данных: * TCP (Transmission Contorol Protocol - транспортный протокол); * IP (Internet Protocol - протокол маршрутизации).
В архитектуре TCP/IP сети соединяются друг с другом коммутаторами IP-пакетов, которые называются шлюзами или IP-маршрутизаторами. Основная задача IP-маршрутизатора — определение по специальному алгоритму адреса следующего IP-маршрутизатора. Для решения этой задачи каждый IP-маршрутизатор должен располагать матрицей маршрутов (специальной базой данных, обеспечивающей маршрутизацию), которую необходимо регулярно обновлять.
Алгоритм маршрутизации является тем фундаментом, на котором строится вся работа базовой сети с архитектурой TCP/IP. Обеспечение надёжных сетевых услуг требует определённой динамики маршрутизации. Неожиданные изменения в связности базовой сети должны рассматриваться как обычные явления и соответствующим образом обрабатываться, так же как и перегрузки отдельных направлений и каналов.
Существует ряд требований, которые следует учитывать при выборе приемлемого алгоритма маршрутизации: · алгоритм маршрутизации должен распознавать отказ и восстановление каналов связи или других IP-маршрутизаторов и переключаться на другие, подходящие маршруты. Время переключения маршрутов должно быть меньшим, чем типичный тайм-аут пользователя протокола ТСР (примерно 1 мин); · алгоритм должен исключать образование циклов, петель и эффекта «пинг-понг» в назначаемых маршрутах как между соседними IP-маршрутизаторами, так и для удалённых IP-маршрутизаторов. Существование вышеперечисленных эффектов не должно превышать типичного тайм-аута пользователя протокола TCP (примерно 1 минута); · нагрузка, создаваемая управляющими сообщениями, которые необходимы для работы алгоритма маршрутизации, не должна ощутимо ухудшать или нарушать нормальную работу сети. Изменение состояния сети, которое может прервать нормальную работу в некоторой локальной области сети, не должно оказывать воздействия на удалённые участки; · поскольку размеры сети постоянно увеличиваются, необходимо обеспечить эффективное использование сетевых ресурсов, например, изменение матриц маршрутов выполнять по частям, передавая по глобальным сетям только дополнения к базам данных по маршрутизации; · размер базы данных по маршрутизации не должен превышать некоторой константы, не зависящей от топологии сети, умноженной на количество узлов и на среднюю связность сети. Хорошая реализация не должна требовать хранения полной базы данных по маршрутизации в каждом IP-маршрутизаторе; · если используются метрики, основанные на достижимости узла и задержке в доставке пакета, то они не должны зависеть от прямой связности со всеми другими IP-маршрутизаторами или от использования механизмов широковещательной передачи, специфичных для некоторых сетей. Процедуры опроса не должны вносить существенных дополнительных расходов; · маршруты по умолчанию следует использовать в качестве первоначальных предположений о маршрутизации, чтобы затем выбирать окончательное направление передачи.
Кроме перечисленных выше задач IP-маршрутизатор должен обеспечивать эффективное распределение собственных ресурсов как по пропускной способности каналов, так и по объёму буферных ЗУ, используемых для хранения пакетов, ожидающих передачу. Самая очевидная стратегия «первым пришёл — первым обслужен» (FCFS — First Come First Served) может оказаться неприемлемой в условиях перегрузки сети.
Так, например, нельзя допустить, чтобы высокоскоростной канал захватил весь объём буферных ЗУ, ничего не оставив низкоскоростному каналу. В хороших алгоритмах обязательно должно учитываться поле «Тип сервиса» заголовка IP-пакета; IP-маршрутизатор может назначить больший приоритет IP-пакетам, передающим управляющую или служебную информацию.
Наконец, алгоритм маршрутизации должен обеспечивать надёжный алгоритм определения состояния каждого канала связи и узла в базовой сети и, если требуется, состояние хост-ЭВМ. Для этого нужен, по крайней мере, протокол канального уровня, предполагающий периодический обмен кадрами через каждый канал связи. Однако этого часто оказывается недостаточно, поэтому дополнительно требуется специальный механизм в алгоритмах маршрутизации. По техническим, административным, географическим, а также иногда и политическим соображениям IP-маршрутизаторы группируются в так называемые «автономные системы». IP-маршрутизаторы, входящие в одну автономную систему, контролируются одной организацией, обеспечивающей их сопровождение, и используют общие для данной автономной системы алгоритмы маршрутизации.
Определение. Конкретный вариант протокола маршрутизации, действующий внутри одной автономной системы, называется внутренним протоколом маршрутизации (IGP — Interior Gateway Protocol).
Возможно, что некоторому IP-пакету, чтобы достичь места назначения, придётся пройти через IP - маршрутизаторы двух или более автономных систем. Поэтому автономные системы должны иметь возможность обмениваться информацией о своём состоянии.
Определение. Протокол для обмена служебной информацией между автономными системами называется внешним протоколом маршрутизации (EGP — Exterior Gateway Protocol).
Каждый IP-маршрутизатор должен обеспечить реализацию протоколов физического, канального, межсетевого уровней, а также протоколы доступа к сети. Кроме того, IP-маршрутизатору необходима реализация некоторого алгоритма выбора маршрута по таблице маршрутизации, а также алгоритма её обновления.
Процедура выбора пути заложена в протоколе IP, причём IP-уровень не знает всего пути, а владеет лишь информацией о том, какому IP-маршрутизатору передать IP-пакет с конкретным адресом места назначения.
Просмотр таблицы маршрутизации происходит в три этапа: - ищется соответствие адреса, записанного в IP-пакете, адресу места назначения в маршрутной таблице. В случае успеха пакет посылается соответствующему IP-маршрутизатору или непосредственно хост-ЭВМ. Связи “точка-точка” выявляются именно на этом этапе; - ищется соответствие адреса, записанного в IP-пакете, адресу некоторой региональной сети места назначения (одна запись в таблице маршрутизации соответствует всем хостам, входящим в данную региональную сеть). В случае успеха система действует так же, как и в предыдущем пункте; - ищется маршрут «по умолчанию», если таковой предусмотрен; дейтаграмма посылается в соответствующий маршрутизатор.
Адрес, определяемый протоколом IP (Internetwork Protocol), состоит из четырёх байтов, записываемых традиционно в десятичной системе счисления и разделяемых точкой. Адрес сетевого интерфейса eth0 из примера — 192.168.102.125. Второй сетевой интерфейс из примера, lo, — так называемая заглушка (loopback), которая используется для огранизации сетевых взаимодействий компьютера с самим собой: любой посланный в заглушку пакет немедленно обрабатывается как принятый оттуда. Заглушка обычно имеет адрес 127.0.0.1.
Отдельная среда передачи данных (локальная сеть) также имеет собственный адрес. Если предстивить IP-адрес в виде линейки из 32 битов, она строго разделяется на две части: столько-то битов слева отводится под адрес сети, а оставшиеся — под адрес абонента в этой сети. Для того, чтобы определить размер адреса сети, используется сетевая маска — линейка из 32 битов, в которой на месте адреса сети стоят единицы, а на месте адреса компьютера — нули. При наложении маски на IP-адрес все единицы в нём, которым соответствуют нули в маске, превращаются в нули5.
Когда компьютер с некоторым IP-адресом решает отправить пакет другому компьютеру, он выясняет, принадлежит ли адресат той же локальной сети, что и отправитель (т. е. подключены ли они к одной среде передачи данных). Делается это так: на IP-адрес получателя накладывается сетевая маска, и таким образом вычисляется адрес сети, которой принадлежит получатель. Если этот адрес совпадает с адресом сети отправителя, значит, оба находятся в одной локальной сети. Это, в свою очередь, означает, что аппаратный адрес (MAC) получателя должен быть отправителю известен.
MAC-адреса компьютеров локальной сети хранятся в специальной таблице ядра, называемой «таблица ARP». Более точно, ARP-таблица отражает соответствие между IP- и MAC-адресами. Таблица эта динамическая: устаревшие соответствия из неё удаляются, так как компьютеру может быть назначен другой IP-адрес, интерфейс можно отключить от сети, заменить и т. д. Если вновь понадобится связаться с компьютером, чей MAC-адрес устрел, соответствие IP и MAC придётся устанавливать по новой. В примере была использована команда ping, посылающая на указанный IP-адрес пакеты служебного протокола ICMP, на который адресат обязан ответить. Если ответа нет, значит, связь по каким-то прчинам невозможна.
Устанавливать соответствие между адресами сетевого и интерфейсного уровня — дело протоколя ARP (Address Resolution Protocol, «протокол преобразования адресов»). В случае преобразования IP в MAC он работает так: отправляется широковещательный ethernet-фрейм типа «ARP-запрос», внутри которого — IP-адрес, что означает «Эй! У кого такой IP?». Каждый работающий компьютер обрабатывает этот фрейм и тот, чей IP-адрес совпадает с запрошенным, возвращает отправителю пустой фрейм типа «ARP-ответ», в поле «отправитель» которого указан искомый MAC-адрес. Это означает «У меня. А что?». Тут ARP-таблица заполняется и первый компьютер готов к инкапсуляции IP-пакета.
27. Системы разного назначения предъявляют к ядру системы самые разные и порой противоречивые требования. Для обеспечения сбалансированного распределения ресурсов между пользователями и разными процессами, в ядре Linux используется концепция планировщиков. Планировщики предназначены именно для того, о чем говорит их название - они планируют различные операции внутри ядра системы. Поскольку в данной статье мы рассматриваем только ввод-вывод, то и под термином «планировщик» далее будет пониматься только планировщик ввода-вывода.
Основные идеи, заложенные в планирование ввода-вывода Практически все приложения на Linux используют какие-либо операции ввода-вывода. Даже такое с виду простое занятие как веб-серфинг производит большое количество маленьких файлов, которые записываются на диск. Без планировщик, каждый раз когда происходит запрос на ввод-вывод, происходило бы взаимодействие с ядром и такие операции бы выполнялись немедленно. Более того, может возникнуть такая ситуация, когда вы можете получить огромное количество запросов на ввод-вывод, которое (чтобы удовлетворить все запросы пользователя) заставит головки диска буквально метаться по нему стороны в сторону. Еще важнее то, что со временем разница между производительностью жестких дисков и остальной системы выросла очень быстро, что означает предъявление ещё больших требований к вводу-выводу для обеспечения общей высокой производительности системы. Так, когда ядро должно обслужить прерывание — приостанавливается работа всех остальных приложений. Поэтому, со стороны это может выглядеть как снижение отзывчивости системы или даже как замедление ее работы. В одних случаях было бы здорово производить операции ввода-вывода параллельно с другими. В других случаях, необходимо производить ввод-вывод как можно быстрее. Концепция планирования ввода-вывода (на самом деле это довольно старая концепция) и появилась для того, чтобы найти баланс между этими двумя крайними состояниями таким образом, чтобы одна операция не прерывала другую (по крайней мере, до тех пор пока это явно не будет нужно вам). Планирование событий ввода-вывода несет в себе необходимость решения многих вопросов. К примеру, планировщику необходимо хранить поступившие запросы в специальной очереди. Каким образом он будет хранить эти события, возможно ли будет изменить порядок событий, сколько времени будут хранится эти события, будут ли выполняться все сохранённые события по достижению определенных условий или с какой-то периодичностью - все это очень важные аспекты работы планировщика. От того как именно реализованы перечисленные аспекты работы планировщика зависит общая производительность работы системы ввода-вывода и то, как воспринимается эта система пользователями. Самое главное с чего следует начать при рассмотрении архитектуры планировщика или настройки существующих планировщиков — это определение назначения, функций и роли системы. Например, целевая система — рабочая станция, которая используется в основном для веб-серфинга, иногда для просмотра видео и/или прослушивания музыки, и может быть даже игр. Задача кажется простой, но тем не менее имеет свои подводные камни. Например, если вы смотрите видео, слушаете музыку или играете в игру, вы скорее всего не хотите, чтобы при этом возникали какие-то задержки или пропадали какие-то кадры, видео бы постоянно прерывалось и показывалось бы рывками. Или, как только вы приготовитесь снести голову какому-нибудь зомби-мутанту, система подвиснет как раз в момент вашего выстрела и когда она снова возобновит работу, вдруг окажется, что зомби уже опередил вас и ваш герой убит. И хотя «заикание» во время воспроизведения какой-нибудь музыки вполне может быть частью жанра, в большинстве случаев это сильно раздражает. Поэтому, если ваша целевая система представляет собой рабочую станцию, Вы возможно захотите как можно меньше задержек в ее работе и это имеет огромное влияние на алгоритм работы планировщика. Одним из важных преимуществ, которое планирование ввода-вывода дает системе — является хранение различных событий в очереди и даже возможность ее (очереди) изменения для совершения отдельных операций ввода-вывода быстрее других. Поскольку скорость операций ввода-вывода может оказаться значительно медленнее, чем в других частей системы, перераспределение запросов на обращение к диску таким образом, чтобы минимизировать перемещение головок диска может повысить общую производительность работы системы. Новые файловые системы тоже могут работать с учетом некоторых из этих концепций, поэтому они вполне могут сами оптимизировать операции ввода-вывода с точки зрения скорости работы устройства хранения данных. Вы даже можете путем настройки самого планировщика эффективнее адаптировать систему к необычным свойствам SSD (твердотельные накопители не имеют головок чтения-записи по сравнению с традиционными жесткими дисками — прим. перев.). Есть несколько типичных методов, которые используются планировщиками ввода-вывода:
Слияние запросов: в рамках этой техники, запросы на чтение-запись схожего назначения объединяются для сокращения количества дисковых операций и увеличение длительности системных вызовов ввода-вывода (что, как правило, приводит к повышению производительности самого ввода-вывода).
«Алгоритм лифта»: Запросы ввода-вывода упорядочиваются исходя из физического размещения данных на диске таким образом, чтобы головки диска как можно больше перемещались в одном направлении и как можно более упорядоченно.
Переупорядочение запросов: Эта техника переупорядочивает запросы на основе их приоритета. Алгоритм реализации данной техники зависит от конкретного планировщика.
Кроме того, почти все планировщики ввода-вывода учитывают фактор «ресурсного голодания», поэтому в итоге (рано или поздно) будут обслужены все запросы (имеется ввиду, что планировщик следит за тем, чтобы запрос на ввод-вывод слишком долго не находился в очереди, т.е. не «голодал» бы — прим.перев.).
В настоящее время в ядре Linux существует четыре планировщика ввода-вывода:
NOOP
Anticipatory
Deadline
CFQ (Completely Fair Queuing — алгоритм полностью честной очереди)
Планировщик NOOP (no-operate) является самым простым. Он помещает все входящие запросы ввода-вывода в простой буфер типа FIFO (First-In, First-Out — первый вошел, первый вышел) и затем просто запускает их на исполнение. Заметим, что это происходит для всех процессов, существующих в системе, независимо от типа запросов ввода-вывода (чтение, запись, поиск необходимой дорожки т.д.). выполняет простейшее слияние запросов, что также помогает повышению пропускной способности диска. Поэтому такие устройства хранения как флэш-диски, SSD-диски, USB-накопители и т.п., которые имеют очень малое время поиска данных (seek time) могут получить преимущество, используя планировщик NOOP.
Anticipatory IO Scheduler (Предполагающий планировщик) пытается предположить к каким блокам диска будут выполнены следующие запросы. Он выполняет слияние запросов, простейший однонаправленный алгоритм лифта, объединение (request batching) запросов на чтение и запись. После того как планировщик обслужил запрос на чтение-запись, он предполагает, что следующий запрос будет для последующего блока, приостанавливаясь на небольшое количество времени. Если такой запрос поступает, то он обслуживается очень быстро, поскольку головки диска находятся в нужном месте.
Deadline IO Scheduler (планировщик предельных сроков) Основополагающим принципом его работы является гарантированное время запуска запросов ввода-вывода на обслуживание. Он сочетает в себе такие возможности как слияние запросов, однонаправленный алгоритм лифта и устанавливает предельный срок на обслуживание всех запросов (отсюда и такое название). Он поддерживает две специальные «очереди сроков выполнения» (deadline queues) в дополнение к двум отдельным «отсортированным очередям» на чтение и запись (sorted queues). Задания в очереди сроков выполнения сортируются по времени исполнения запросов по принципу «меньшее время — более раннее обслуживание — ближе к началу очереди». Схема работы планировщика достаточно прямолинейна. Планировщик сначала решает какую очередь использовать первой. Более высокий приоритет установлен для операций чтения, поскольку, как уже упоминалось, приложения обычно блокируются при запросах на чтение. Затем он проверяет истекло ли время исполнения первого запроса. Если так — данный запрос сразу же обслуживается. В противном случае, планировщик обслуживает пакет запросов из отсортированной очереди. В обоих случаях, планировщик также обслуживает пакет запросов следующий за выбранным в отсортированной очереди. Deadline scheduler очень полезен для некоторых приложений. В частности, в системах реального времени используется данный планировщик, поскольку в большинстве случаев, он сохраняет низкое время отклика
CFQ IO Scheduler (планировщик с полностью честной очередью) (по умолчанию) При работе CFQ синхронно размещает запросы на ввод-вывод от процессов в ряд очередей на каждый процесс (per-process queues). Затем он выделяет отрезки времени (timeslices) для каждой очереди на доступ к диску. Длина отрезков времени и количество запросов в очереди, которые будут обслужены, зависит от приоритета ввода-вывода конкретного процесса. Асинхронные запросы от всех процессов объединяются в несколько очередей по одной на каждый приоритет. CFQ предоставляет пользователям (процессам) конкретного устройства хранения данных необходимое количество запросов ввода-вывода для определённого промежутка времени. Это сделано для многопользовательских систем, так как все пользователи в таких системах получат один и тот же уровень отклика.