

6.2. Кодирование с минимальной избыточностью
Для практики важно, чтобы коды сообщений имели по возможности наименьшую длину. Алфавитное кодирование пригодно для любых сообщений, то есть S = A*. Если больше про множество S ничего не известно, то точно сформулировать задачу оптимизации затруднительно. Однако на практике часто доступна дополнительная информация. Например, для текстов на естественных языках известно распределение вероятности появления букв в сообщении. Использование такой информации позволяет строго поставить и решить задачу построения оптимального алфавитного кодирования.
6.2.1. Минимизация длины кода сообщения
Если задана разделимая схема алфавитного
кодирования
,
то любая схема
![]() ,
где
,
где
![]() является перестановкой
является перестановкой
![]() ,
также будет разделимой. Если длины
элементарных кодов равны, то перестановка
элементарных кодов в схеме не влияет
на длину кода сообщения. Но если длины
элементарных кодов различны то длина
кода сообщения зависит от состава букв
в сообщении и от того, какие элементарные
коды каким буквам назначены.
,
также будет разделимой. Если длины
элементарных кодов равны, то перестановка
элементарных кодов в схеме не влияет
на длину кода сообщения. Но если длины
элементарных кодов различны то длина
кода сообщения зависит от состава букв
в сообщении и от того, какие элементарные
коды каким буквам назначены.
Если заданы конкретное сообщение и конкретная схема кодирования, то нетрудно подобрать такую перестановку элементарных кодов, при которой длина кода сообщения будет минимальна.
Пусть k1,…,kn
– количества вхождений букв a1,...,an
в сообщение S,а l1,…,ln
– длины элементарных кодов
,
соответственно. Тогда, если
![]() и
и
![]() ,
то
,
то
![]() .
Действительно, пусть kj=k+a,
ki=k
и lj=l,
li=l+b,
где a,b
.
Действительно, пусть kj=k+a,
ki=k
и lj=l,
li=l+b,
где a,b![]() 0.
Тогда
0.
Тогда
![]()
Отсюда вытекает алгоритм назначения элементарных кодов, при котором длина кода конкретного сообщения S будет минимальна: нужно отсортировать буквы в порядке убывания количества вхождений, элементарные коды отсортировать в порядке возрастания длины и назначить коды буквам в этом порядке.
ЗАМЕЧАНИЕ
Этот простой метод решает задачу
минимизации длины кода только для
фиксированного сообщения S
и фиксированной схемы
![]() .
.
6.2.2. Цена кодирвания
Пусть заданы алфавит
![]() и вероятности появления букв в сообщении
и вероятности появления букв в сообщении
![]() (pi –
вероятность появления буквы ai).
Не ограничивая общности, можно считать,
что pi+…+pn=1
и
(pi –
вероятность появления буквы ai).
Не ограничивая общности, можно считать,
что pi+…+pn=1
и
![]() (то есть можно сразу исключить буквы,
которые не могут появиться в сообщении,
и упорядочить буквы по убыванию
вероятности их появления).
(то есть можно сразу исключить буквы,
которые не могут появиться в сообщении,
и упорядочить буквы по убыванию
вероятности их появления).
Для каждой (разделимой) схемы
алфавитного кодирования математическое
ожидание коэффициента увеличения длины
сообщения при кодировании (обозначается
![]() )
определяется следующим образом:
)
определяется следующим образом:
![]() ,
где
,
где
![]()
и называется средней ценой (или длиной) кодирования при распределении вероятностей P.
Пример
Для разделимой схемы А={a,b},
B={0,1},
![]() при распределении вероятностей
при распределении вероятностей
![]() цена кодирования составляет 0.5*1+0.5*2=1.5,
а при распределении вероятностей
цена кодирования составляет 0.5*1+0.5*2=1.5,
а при распределении вероятностей
![]() она равна 0.9*1+0.1*2=1.1.
она равна 0.9*1+0.1*2=1.1.
Обозначим
![]()
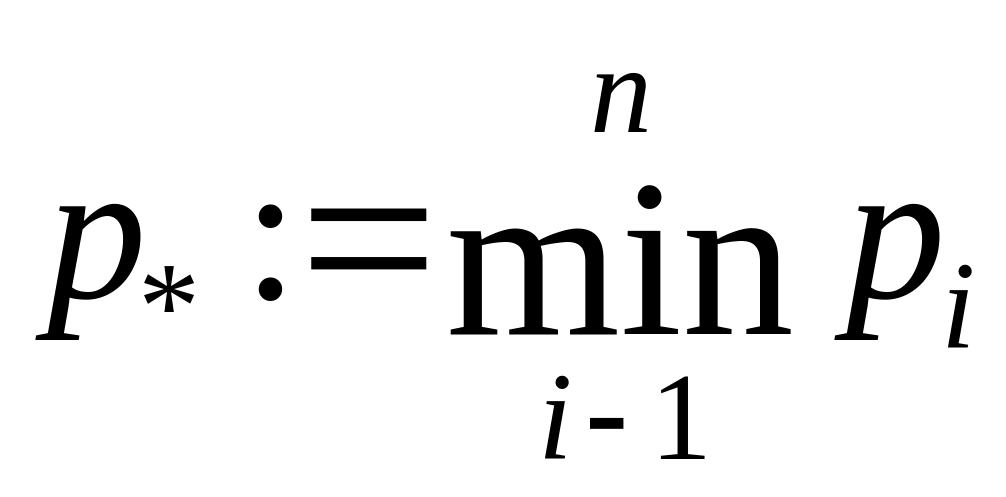
![]()
Очевидно, что всегда существует разделимая
схема
,
такая что
![]() .
Такая схема называется схемой равномерного
кодироваия. Следовательно,
.
Такая схема называется схемой равномерного
кодироваия. Следовательно,
![]() и достаточно учитывать только такие
схемы, для которых
и достаточно учитывать только такие
схемы, для которых
![]() ,
где li
целое и
,
где li
целое и
![]() .
Таким образом, имеется лишь конечное
число схем
,
для которых
.
Таким образом, имеется лишь конечное
число схем
,
для которых
![]() .
Следовательно, существует схема
.
Следовательно, существует схема
![]() ,
на которой инфимум достигается:
,
на которой инфимум достигается:
![]()
Алфавитное (разделимое) кодирование
,
для которого
![]() ,
называется кодированием с минимальной
избыточностью, или оптимальным
кодированием, для распределения
вероятностей P.
,
называется кодированием с минимальной
избыточностью, или оптимальным
кодированием, для распределения
вероятностей P.