

ВВЕДЕНИЕ
Лингвистическое обеспечение САПР (ЛО САПР) развивается, как правило, с опережением относительно других видов обеспечения САПР. Его основная задача – выполнение преобразования задания на проектирование на языке характеристик объекта проектирования в конструкторскую и технологическую производственную документацию на языках исполнительных устройств. К ЛО САПР относят языки программирования, проектирования и управления. Все эти языки должны обеспечивать:
описание, управление и контроль объекта и процесса проектирования в компактной форме, т. е. быть лаконичными без потери детализации;
однозначное представление информации;
иметь развитую систему диагностирования и выдачи сообщений об ошибках.
Реализуется лингвистическое обеспечение в виде программных изделий программного обеспечения и документов организационного обеспечения САПР.
Языки программирования служат для разработки и редактирования системного и прикладного программного обеспечения САПР.
Языки проектирования служат для представления необходимых исходных данных, формирования заданий и оформления полученных проектных решений на каждом этапе технологического маршрута в САПР.
Языки управления служат для формирования последовательностей команд, описания их параметров и условий выполнения.
Четкой границы между этими тремя типами языков провести нельзя. В ряде случаев возможно использование одного и того же языка как для программирования, так и для описания проектных исходных данных.
В настоящее время существуют десятки тысяч различных формальных языков и трансляторов. Нужно ли разрабатывать большое количество языков и трансляторов к ним? Почему недостаточно существующих языков? Нельзя ли изобрести универсальный язык? Необходимость разработки новых языков и трансляторов определяется следующими причинами:
универсальный язык неудобен для использования в каждой узкой предметной области; трансляторы с универсального языка – громоздкие;
автоматизированные системы создаются для пользователей – специалистов в некоторой предметной области и, следовательно, взаимодействие с автоматизированной системой должно вестись на удобном для этих пользователей языке.
В науке постоянно изобретаются новые языки, позволяющие в компактной, наглядной и удобной форме выразить постановку задачи, результаты исследований и т. д. Математика – пример богатейшего собрания таких языков. Специальные языки используются в химии, в машиностроении (графические языки), в проектировании логических схем, в информационных системах. В каждой такой предметной области существуют и развиваются свои языки. Особо следует выделить алгоритмические языки программирования. Как известно, алгоритмические языки становятся доступными программисту только после создания трансляторов с этих языков.
Проблему трансляции в самом общем виде можно сформулировать как проблему построений отображения одного представления алгоритма в другое представление, и одного представления данных в другое представление данных. Примерами таких отображений являются:
алгоритм на одном языке программирования —› алгоритм на другом языке программирования;
алгоритм на языке программирования —› алгоритм в машинных кодах;
алгоритм на языке программирования —› действия по алгоритму;
описание данных —› другое описание данных (машинное представление данных, другой формат данных, данные на экран и т. д.).
Задача трансляции формулируется следующим образом: построить алгоритм, осуществляющий перевод программ, написанных на языке Li в некоторый требуемый выход (в частности программу на другом языке Lg). Например. L1 – язык для записи алгоритмов решения класса задач, L2 – язык машинных команд.
Если L2 – язык машинных команд, то транслятор называют компилятором.
Если L2 – язык высокого уровня, то транслятор называют препроцессором.
Если транслятор не выдает результата на языке L2, а сразу выполняет действия на языке L1, то такой транслятор называется интерпретатором.
Пример, х := а + b + с. Компилятор выдаст последовательность машинных команд. Интерпретатор после распознавания оператора выполнит действия.
Синтаксис языка – это совокупность правил построения предложений и отдельных конструкций языка.
Семантика языка – это совокупность правил интерпретации предложений и отдельны: конструкций языка (смысл и значение).
Основная сложность построения транслятора состоит в том, что число возможных программ на входе бесконечно, и транслятор должен обрабатывать программы любой сложности.
Рабочая программа курса
“Лингвистическое обеспечение САПР”
(для студентов факультета безотрывных форм обучения – специальность 2203)
Целью курса является изучение основных элементов ЛО САПР и теоретических основ проектирования лингвистического обеспечения.
Для изучения курса достаточно знакомства с одним из современных языков программирования (СИ, Паскаль, АДА и т. п.) и знание основ построения и проектирования цифровых систем переработки информации.
Содержание курса:
Лекция 1.
Разновидности языков САПР, назначение и особенности применения языков программирования, проектирования и управления в ЛО САПР.
Лекция 2.
Понятие языка, структура компилятора, синтаксис и семантика формальных языков, форма Бэкуса-Наура, синтаксическое дерево, рекурсия, классификация языков и порождающие грамматики Хомского.
Лекция 3.
Лексический анализ, однородные символы, диаграмма состояний, матрица переходов состояний.
Лекция 4.
Грамматический разбор, разбор сверху вниз и его проблемы, грамматики с предшествованием, грамматика с операторным предшествованием, разбор арифметических выражений, матричное представление синтаксического дерева.
Лекция 5.
Генерация кода и оптимизация, машинно-независимая оптимизация, машинно-зависимая оптимизация. Распределение памяти.
Лекция 6.
Фаза сборки. Потоки информации компилятора, форматы записей таблиц компилятора. Просмотры компилятора.
Литература
Дворянкин А. М. Основы трансляции: Учеб. пос. Волгоград: Волгоград. гос. техн. ун-т, 1997.– 80 с.
Грис Д. Конструирование компиляторов для цифровых вычислительных машин.– М.: Мир, 1975.– 544 с.
Ахо А., Ульман Дж. Теория синтаксического анализа, перевода и компиляции: в 2-х томах.– М.:, Мир, 1978.– 1019 с.
Системы автоматизированного проектирования в радиоэлектронике: Справочник/Е. В. Авдеев, А. Т. Еремин, И. П. Норенков, М. И. Песков; Под ред. И. П. Норенкова.– М.: Радио и связь, 1986.– 368 с.
Лабораторные занятия по курсу
“ЛИНГВИСТИЧЕСКОЕ ОБЕСПЕЧЕНИЕ САПР
№ |
Тема занятия |
Часы |
1. |
Задачи грамматического разбора арифметических выражений и символьных строк (сентенциальных форм). |
8 |
|
ВСЕГО: |
8 |
СВОДНАЯ ТАБЛИЦА РАСПРЕДЕЛЕНИЯ ЧАСОВ ПО ВИДАМ ЗАНЯТИЙ |
|
Виды занятий |
Часы |
Лекции |
14 (2 + 12) |
Лабораторные работы |
8 |
Консультации |
17 |
Контрольная работа |
10 |
ВСЕГО |
49 |
Лингвистическое обеспечение сапр
Для разработки и редактирования программного обеспечения САПР используются три вида языков программирования: машинные, автокоды и алгоритмические (т. е. языки программирования высокого уровня).
Программное обеспечение на машинном языке экономично в эксплуатации, но весьма трудоемко при разработке и модификации программ и, кроме того, оно не обладает инвариантностью относительно вычислительных машин с различными системами команд.
Использование автокодов повышает лаконичность, обозримость, перемещаемость и надежность программ при сравнительно высокой трудоемкости и длительности разработки программного обеспечения. При разработке прикладного программного обеспечения в САПР иногда применяют автокоды в узловых, наиболее часто выполняемых блоках, от которых существенно зависит производительность или возможность использования технических особенностей вычислительного или исполнительного оборудования. Программы в автокодах не обладают инвариантностью относительно вычислительных машин с различными системами команд.
Алгоритмические языки общего назначения являются машинно-независимыми, позволяют создавать компактные, обозримые программы при относительно небольших трудозатратах. Основными требованиями являются четко выраженная модульность, использование современных конструктивных особенностей вычислительных средств и возможность организации связей между программными модулями вплоть до их параллельной работы в режиме реального времени.
Языки проектирования классифицируются по ряду признаков. По характеру использования среди языков проектирования выделяют языки, связывающие пользователя с ЭВМ, и языки представления информации внутри ЭВМ. Первые из них делятся на входные, выходные и сопровождения, а вторые — на внутренние и промежуточные. Входные языки используют для описания исходных данных и заданий, выходные – для представления результатов в удобном для разработчика виде, а языки сопровождения – для редактирования данных и заданий в процессе решения задач проектирования. Внутренние языки устанавливают единую форму представления текстовой и графической информации в памяти ЭВМ по подсистемам САПР. Промежуточные языки используются в системах поэтапной трансляции для представления информации после этапов лексического и синтаксического анализа.
Языки пользователя могут быть универсальными (инвариантными) и проблемными (специализированными). Универсальность можно рассматривать как инвариантность по отношению к различным уровням и подсистемам внутри конкретной комплексной САПР или по отношению к некоторому иерархическому уровню различных предметных областей (различных САПР). В последнем случае язык обычно называют общецелевым. Такие языки обычно занимают промежуточное положение между языками программирования общего назначения и специализированными языками моделирования.
Универсальные по отношению к уровням САПР языки опираются на использование систем управления базой данных или информационно-поисковых систем общего назначения, тогда как проблемные языки предполагают наличие специализированных компиляторов. Универсальные входные языки в САПР облегчают подготовку, контроль и ввод данных, описание их логической структуры и манипулирование данными.
Применение универсальных языков и баз данных позволяет обеспечить:
информационную полноту проектирования;
возможность использования записей произвольной структуры;
независимость языка и транслятора от имен, синтаксиса и семантики обрабатываемых данных;
легкость изменений структуры и содержания входных данных;
высокую диагностическую способность с синтаксическим и частично семантическим контролем вводимых данных;
простоту и легкость в изучении и использовании.
Специфические особенности представления объектов на различных уровнях проектирования приводят к делению специализированных языков на языки, например, системного, функционально-логического, схемотехнического, приборно-технологического, топологического, коммутационно-монтажного проектирования.
Специализированные входные языки весьма многочисленны, взаимоувязаны с пакетами прикладных программ САПР, ориентированы на фиксированные наборы данных определенной структуры, имеют достаточно строгий и полный синтаксис, достаточный синтаксический контроль. В то же время в противоположность универсальным языкам проблемные входные языки могут обеспечить достаточный семантический контроль. Проблемные входные языки находятся в постоянном развитии и быстро обрастают всевозможными модификациями и версиями.
Назначение языка сопровождения состоит в том, чтобы сформулировать и передать в программу результат выполнения проектировщиком неавтоматизированной проектной операции по полученному только что от программы промежуточному результату, сформировать директивы изменения некоторых входных данных или состава задания, передать в программу указания о возобновлении или прекращении многовариантного анализа, сформировать управляющее воздействие после анализа причин и последствий незапланированного прерывания задачи.
Подобно входным языкам в языках сопровождения могут использоваться режимы обучения и распознавания графических и речевых образов. Особым, наиболее простым видом языка сопровождения характеризуется такой режим работы, когда задача проектирования в определенные моменты требует от разработчика указать один из заданного фиксированного множества вариантов символьных или графических данных или команд. Возможные варианты ответов в таком режиме называют «меню», а язык сопровождения состоит из команд указания номера, места расположения или образа команды или элемента данных.
Внутренние и промежуточные языки проектирования обычно ориентированы на конкретную ЭВМ, операционную систему и базу данных. Именно наличие языков внутреннего представления позволяет в качестве входных применять высокоуровневые языки, инвариантные относительно вычислительных средств. Другое назначение внутреннего языка – обеспечение межмашинных связей и взаимозаменяемости вычислительных и исполнительных устройств.
Выходные языки САПР (или языковые средства формирования выходных документов) призваны обеспечить эффективность представления проектных результатов, а также соблюдение требований стандартов и требований к машинным носителям информации при формировании конструкторской и технологической документации.
В зависимости от ориентации языка на пакетный или диалоговый режим работы различают языки пассивные и диалоговые. В диалоговых языках объединяются элементы языков входных, выходных и сопровождения.
Диалог может быть пассивным и активным. Характерные черты пассивного диалога:
инициатор диалога — система, она осуществляет прерывание вычислений и обращение к пользователю;
от пользователя требуются простые ответы.
В языках альтернативного типа пользователь выбирает нужный ответ из заданного меню. В языках сценарного типа – указывает исходные данные по заданным вопросу и формату ответа. Для активного диалога характерно:
инициатива диалога — двусторонняя;
диалоговый язык состоит из директив.
Диалоговый язык составляют сообщения системы и сообщения пользователя. Сообщения системы могут быть следующих типов:
информационные — они не требуют ответных действий пользователя и содержат информацию о ходе вычислений, результатах расчетов и т. п.;
запросы — обращения к пользователю, требующие от него тех или иных действий, например выбора варианта из заданного меню, задания численных значений параметров;
подсказки — сообщения о возможных вариантах продолжения решения, указания на допущенные пользователем ошибки с их локализацией и вариантами исправлений.
Сообщения пользователя при пассивном диалоге — фразы из меню, при активном диалоге — рабочие или служебные директивы. Рабочие директивы служат для указания необходимых проектных процедур, а служебные — для управления системой.
В соответствии с делением входной информация на описательную и директивную части во входных языках выделяют части, называемые языками описания объекта (ЯОО) и описания заданий (ЯОЗ).
Языки описания объекта могут быть процедурного и непроцедурного типов. Процедурные ЯОО предназначены для описания процессов, развивающихся в проектируемых объектах, такое описание обычно имеет форму описания алгоритма. Непроцедурные ЯОО ориентированы на описание структуры объектов. ЯОЗ обычно являются процедурными.
В зависимости от характера описания информации языки делятся на символьные и графические. К символьным языкам относятся, например, языки схемные и имитационного моделирования. Схемные языки предназначены для описания структуры схем без отображения условных графических обозначений их элементов и относятся к непроцедурным языкам. Языки имитационного моделирования предназначены для описания процессов функционирования систем и обычно относятся к процедурным языкам. Графические языки служат для описания графической информации; в отличие от схемных языков графические языки позволяют отображать чертежи и схемы с сохранением информации о геометрической форме и размерах элементов изображения.
Языки графического программирования или графические расширения языков программирования общего назначения представляют собой средства для описания и построения изображений и манипулирования ими. В языках графического программирования имеются также средства для анализа изображений и взаимосвязей составляющих их подэлементов и распознавания графических образов.
В графических языках используются графические элементы — «примитивы» или их структурированные обобщения, их внутренние характеристики и внешние атрибуты, определяющие свойства графических примитивов в момент визуализации. Операции представляют собой геометрические преобразования: кадрирование, перекомпоновку элементов и подэлементов, их слияние и удаление. При анализе изображений сложный графический объект представляется в виде композиции простейших элементов для заданного набора связывающих элементы графических операций. Распознавание графических образов позволяет отождествить простой графический объект с одним из заданных; множество заданных объектов, с которыми сравнивается распознаваемый, как правило, не велико.
Мониторная система, СУБД, информационно-поисковая система, информационно-справочная система и другие вспомогательные программные подсистемы САПР, мониторы отдельных ЭВМ, управляющие программы контроллеров, концентраторов, процессоров ввода-вывода и исполнительные программно-управляемые автоматы также имеют свои входные языки, которые называются языками управления.
Элементами языков управления являются команды, информационную часть которых составляют параметры. Предложения в языках управления называются шагами или кадрами. В информационных языках предложения объединяются в запросы и поисковые предписания.
Языки управления подсистем САПР имеют высокий уровень и часто инвариантны относительно используемых технических средств. Языки управления распределением ресурсов баз данных и обработки данных имеют более низкий уровень и зависят от реализации.
Делаются попытки создания единого по синтаксису и семантике языка взаимодействия пользователей различных САПР с различными техническими средствами графического взаимодействия (графический дисплей, координатосъемщик, световое перо, функциональная клавиатура и т. д.).
Для программно-управляемого оборудования характерны языки управления низкого уровня, специфичные для каждого типа устройства. Языки управления даже самого высокого уровня ориентированы на пользователей высокой квалификации и по этой причине характеризуются краткостью, отрывистостью, отсутствием даже попыток соблюдения каких-либо норм естественного языка.
Следует отметить, что эффективность работы пользователя с комплексной САПР в значительной степени зависит от качества разработки компонентов лингвистического обеспечения, т. е. языков САПР и соответствующих трансляторов.
Для конструирования трансляторов необходимо иметь некоторую ведущую идею, которая позволит “вычислять значение” любой входной программы, выражая это значение на выходном языке или последовательностью действий. Одна из таких идей – идея синтаксически ориентированной трансляции. Синтаксически-ориентированный метод трансляции предназначен для получения программы на выходном языке. Транслятор должен использовать структуру входного текста, т. е. анализ сложного объекта явно или неявно проводится на основе структуры этого объекта.
Метод синтаксически ориентированной трансляции основан на работах американского ученого Н. Хомского. Он исследовал механизм понимания человеком смысла предложений естественного языка. Основной вывод Хомского:
“Существенную роль в процессе распознавания смысла предложения играет этап построения структуры предложения. Эта структура затем используется для вычисления смысла”.
Рассмотрим пример выражения: “Порядок сменит хаос”. Грамматический разбор этого предложения можно сделать двумя способами (рис. 1.). При этом в первом случае смысл выражения будет: “Вместо хаоса будет порядок”, а во втором случае – “Вместо порядка будет хаос”.
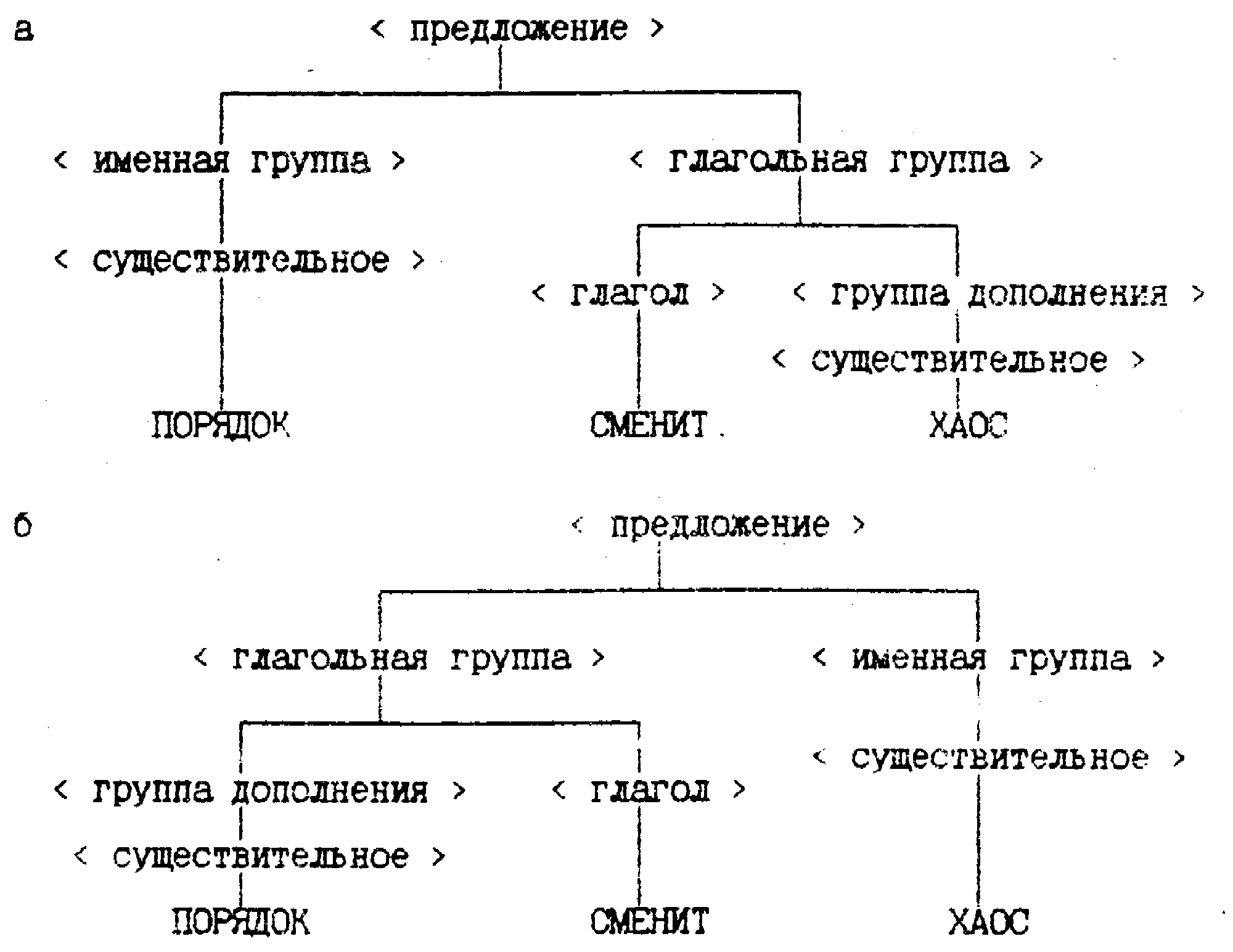
Рис. 1. Примеры грамматического разбора
В этом примере предложение может иметь два различных смысла в зависимости от структуры предложения, которая получена с помощью грамматического разбора.
Другие примеры предложений с неоднозначным смыслом: “Он встретил ее на поляне с цветами”, “Half boiled chicken”.
Основная гипотеза Хомского состоит в следующем: человек “вычисляет” смысл предложения на основе его структуры. Принимая эту гипотезу, процесс трансляции можно представить в виде двух шагов:
1) распознавание структуры входного предложения;
2) построение выходного текста (действий) на основе этой структуры (рис. 2.).
 Т
Р А Н С Л Я Т О Р
Т
Р А Н С Л Я Т О Р

 Вход
структура
Выход
Вход
структура
Выход


 Распознаватель
Генератор
Распознаватель
Генератор
L 1
L2
1
L2

другая информация

Рис. 2. Укрупненная схема трансляции
Распознавание структуры входного предложения осуществляет блок распознавания – “распознаватель”. Этот блок, анализируя входное предложение, строит его структуру. Распознаватель также может формировать другую вспомогательную информацию, необходимую блоку генерации, например, таблицы идентификаторов и констант.
Блок генерации по структуре входного предложения строит выходной текст на языке L2.
Процесс трансляция должен выполняться автоматически. Поэтому все понятия (язык, программа, структура и т. д.) должны быть точно определены.
Основные понятия языка.
Словарь – конечное множество элементов. Элементы словаря называются символами.
Цепочка над словарем V – произвольная конечная упорядоченная последовательность символов из V. Цепочки обычно обозначаются малыми греческими буквами. Пример:
V = {а, Ь, с}, α = abbca, β = ааас, ν = b
Пустая цепочка – это цепочка, не содержащая символов. Пустую цепочку обозначают буквой ε.
Пусть V – некоторый словарь. Обозначим V* – множество всех возможных цепочек, составленных из символов из V, включая пустую цепочку.
Если символ а принадлежит словарю V, то цепочки из этого символа будем обозначать следующим образом:
а °
= ε, аn
= аа … а
°
= ε, аn
= аа … а

 (n
раз)
(n
раз)
Конкатенация (склеивание) – бинарная операция на V*. Если α и β некоторые цепочки из V*, αβ – результат конкатенации и αβ принадлежит V*. Пример:
α = abbca, β = аac, αβ = abbcaaac.
Пустая цепочка для операции конкатенации играет роль единицы: если α из V*, то αε = εα = α.
Любую цепочку можно представить в виде конкатенации ее подцепочек, например, bcaba = μτν, где μ = bc, τ = aba, ν = ε.
Определим операции подстановки как замену некоторой подцепочки заданной цепочки α цепочкой β. Пример, α = bcab. Если вместо подцепочки са цепочки α подставить цепочку bbc, то получим новую цепочку bbbcb.
Язык над словарем V – произвольное множество цепочек над словарем V. Язык над словарем V будем обозначать L(V). Очевидно, что любой язык L(V) принадлежит множеству V*. Над словарем V можно определить столько языков, сколько подмножеств содержит V*. Если словарь V – непустой, то существует бесконечное количество различных языков над V.
Это определение языка очень широкое. Под него подходят многие естественные языки и языки программирования. Задать язык в этом определении – значит описать множество цепочек, входящих в этот язык.
Примеры языков:
1) V1 = {a, b}, L1 = {aabb, baa, aaba}. Такой язык называется конечным.
2) V2 = V1 = {a, b}, L2 = {an, bn | n 0}. Очевидно, что aaabbb принадлежит L2, baabbba не принадлежит L2. Такой язык содержит бесконечное множество цепочек.
3) V3 = {a, b, с}, L3 = {an, bn , сn | n 0}. Этот язык похож на L2.
4) V4 = {(, )}, L4 – множество скелетов правильных скобочных выражений (язык Дика). Цепочка ( ( ) ) ( ) ( ( ) ( ) ) принадлежит L4, а цепочка ( ( ( ) ( ) ( ) не принадлежит L4.
5) V5 = {a, b}, L5 – множество всех цепочек, содержащих одинаковое число вхождений символов а и b. Цепочка aababb принадлежит L5, а цепочка abbba не принадлежит L5.
6) V6 = {0, 1}, L6 – все цепочки, в которых непосредственно справа от 0 стоит символ 1. Цепочка 01101 принадлежит языку L6. Цепочка 100101 не принадлежит языку L6.
7) V7 = {a, b, с, d, +, -, *, /}, L7 – множество правильных арифметических выражений языка АЛГОЛ, построенных из букв а, b, с, d. Цепочка а + b * с принадлежит L7. Цепочка - b - * - * - b не принадлежит L7.
8) V8 – множество словоформ русского языка, L8 – русский язык. Цепочка “Яркая зеленая ракета взлетела над ночной тайгой” принадлежит L8. Цепочка “за домой по телеге к” не принадлежит L8.
9) V9 = {a, b, …,z, 0, 1, …,9, ;, :, =, , …, begin, гeal, …}, L9 – язык АЛГОЛ. Цепочка begin end принадлежит L9. Цепочка begin real а; а:=3 end принадлежит L9. Цепочка begin real a; а:=:3 end не принадлежит L9.
Понятие языка как подмножества цепочек является слишком общим и не конструктивным. Это понятие удобно в случае конечного языка (L1). В случае бесконечного языка только в некоторых частных случаях можно задать язык с помощью условий (предикатов), наложенных на структуру цепочек.
Прежде чем перейти к методам решения данной проблемы, рассмотрим структуру компилятора, а затем уже синтаксис и семантику формальных языков.
Структура компилятора. Компилятор сначала анализирует исходную программу и выделяет в ней основные части. Затем синтезирует объектную программу, используя таблицы, построенные на стадии анализа. Для решения этой задачи компилятор разбивается на несколько частей, каждая из которых выполняет конкретную подзадачу за один проход. Для небольших ЭВМ, в которых размеры оперативной памяти (ОП) ограничивают размеры компилятора, каждая часть представляет собой физически отдельную подпрограмму, принимающую на входе данные, выработанные предыдущей частью. На больших ЭВМ, где компилятор может быть размещен в ОП, такое разбиение на части является скорее функциональным, чем физическим. Информация между различными проходами компилятора передается в двух формах: в форме таблиц и в форме скомпилированных команд, существующих в некотором внутреннем символическом формате до тех пор, пока не будет фактически сформирована программа на машинном языке.
Первым проходом процесса компиляции является лексический анализ, который выполняется сканером. Сканер сводит различные входные формы к одной и той же стандартной форме, не содержащей избыточности. Остаются только те символы и литеры, которые необходимы для дальнейшей компиляции. Это позволяет организовать эффективную работу остальных частей компилятора над выработанными сканером данными в хорошо определенном формате.
На втором проходе выполняется синтаксический анализ и интерпретация. Отдельные предложения программы разбиваются на более простые части. Синтаксический анализатор проверяет, является ли программа грамматически правильной, т. е. удовлетворяет ли она законам языка, на котором написана. Первоначальная структура исходной программы преобразуется шаг за шагом во внутреннее представление (дерево, матрицу, список или польскую запись), с которой смогут впоследствии работать оптимизирующая и вырабатывающая объектный код части компилятора.
Первые два прохода анализируют предложения исходной программы. Следующие фазы синтезируют объектную программу, но обычно перед генерацией фактического кода необходимо обработать или изменить некоторым образом внутреннее представление программы. Объектная программа может оптимизироваться в направлении сокращения времени работы или размеров используемой памяти, или же некоторого компромисса между этими двумя требованиями. Такая оптимизация может потребовать нескольких проходов. Оптимизация может быть либо локальной, когда обнаруживаются и приводятся общие подвыражения в одном арифметическом выражении или в соседних предложениях, либо глобальной, когда рассматриваются различные группы команд. Группы исключаются, если они никогда не используются; выражения, вычисляемые внутри цикла и не зависящие от переменной цикла, выносятся за пределы цикла; общие выражения, появляющиеся в нескольких местах, вычисляются только один раз и т. п.
Лексический и синтаксический анализы, а также некоторые из оптимизирующих проходов в основном машинно-независимы, но в большей степени зависят от языка. Следующие фазы, также включающие оптимизирующие проходы, сильно зависят от конкретной вычислительной техники, но не зависят от языка.
За оптимизацией следуют распределение памяти и генерация кода. Они могут быть выполнены на отдельных проходах, но могут быть объединены и в один проход. При распределении памяти рассматриваются заданные программистом описания данных и таблицы, полученные из них и из других предложений исходной программы на предыдущих фазах.
Синтаксис и семантика формальных языков. Синтаксис языка затрагивает только форму элементов языка. Если предложение удовлетворяет формальным правилам, оно независимо от его значения рассматривается как синтаксически правильное. Напротив, семантика языка задает логическое соответствие между различными элементами и значением синтаксически корректных предложений.
Части компилятора анализируют исходную программу литера за литерой для нахождения синтаксических классов, соответствующих элементам исходных предложений, и распознают затем основные синтаксические конструкции, выполняя эти действия с помощью правил. Эти правила лежат в основе определения языка программирования, на котором написана программа.
Точное определение языка программирования важно как для пользователя, так и для реализатора языка. Никаких проблем не возникло бы, если бы язык состоял из конечного числа допустимых формул и предложений. В этом случае было бы достаточно их перечисления. Трудность заключается в том, что все используемые на практике языки содержат неограниченное или очень большое число допустимых предложений. Перечислить и хранить их все по отдельности невозможно. В этом и нет необходимости, если любое предложение может быть сгенерировано с помощью некоторого конечного механизма (алгоритма, устройства, исчисления). Любые конечные механизмы задания языков будем называть грамматиками. Существует две возможности задания конечного механизма:
1) конечный механизм порождает любую цепочку языка за конечное число шагов и не порождает цепочек, не принадлежащих языку;
2) конечный механизм распознает цепочку, т. е. за конечное число шагов отвечает на вопрос: принадлежит ли данная цепочка данному языку?
Стандартный метод описания языка состоит в задании такого генерирующего алгоритма, или грамматики языка, т. е. конечного непустого множества правил, посредством которых могут быть порождены все допустимые предложения языка. Процедура, обратная этой, используется обычно в компиляторе на фазе анализа, когда элементы предложений исследуются на принадлежность данной комбинации соответствующей грамматике.
Формы Бэкуса-Наура. Для описания структуры и правил исследования некоторого языка используется определенная система обозначений, понятий и образованных из них конструкций. Эта система тоже подчиняется некоторым правилам и сама может считаться языком. Такой язык часто называют метаязыком. В настоящее время используется ряд языков для описания синтаксиса языков – метасинтаксические языки. Разрабатываются также метасемантические языки – для описания семантики.
Наиболее распространенным метасинтаксическим языком являются нормальные формы Бэкуса-Науэра (металингвистические формулы) – язык, специально разработанный для описания синтаксиса языка АЛГОЛ-60 и используемый для описания многих других языков программирования.
Основное назначение форм Бэкуса-Науэра (БНФ) – представление в сжатом виде строго формальных и однозначных правил написания конструкций описываемого языка. При использовании этого формализма символ, расположенный слева от знака “::=”, заменяется выражением, стоящим справа от этого знака, причем альтернативные способы замены символов разделяются вертикальной чертой “|”, имеющей значение “или”. В БНФ могут также использоваться следующие обозначения: [а] – необязательное вхождение символа “а”, {а} – последовательность из 0 или более вхождений символа “а”. Символы, используемые в БНФ, подразделяются на два множества:
терминальные символы, или терминалы, которые не могут быть разделены на более мелкие единицы;
нетерминальные символы, или нетерминалы, которые представляют промежуточные состояния процесса генерации и определяются посредством некоторых других символов.
Записанные последовательно символы интерпретируются как следующие друг за другом. Для того, чтобы отличать терминальные символы от нетерминальных, последние заключаются в угловые скобки “< >”.
Терминалы являются символами объектного языка, нетерминалы – символами метаязыка. Каждый нетерминал должен появиться хотя бы в одном правиле подстановки слева от символа “::=”.
Опишем грамматику английских предложений, имеющих следующую структуру:
“The boy has a girlfriend”
или
“The girl has a boyfriend”.
Грамматика ограниченного подмножества английского языка может быть определена следующим образом:
Правило 1: <предложение>::= <именная группа><глагольная группа>
Правило 2: <именная группа>::=The <существительное-1>
Правило 3: <существительное-1>::= boy | girl
Правило 4: <глагольная группа>::= <глагол> <группа дополнения>
Правило 5: <глагол> ::= has
Правило 6: <группа дополнения>::= <артикль> < существительное-2>
Правило 7: <артикль>::= a
Правило 8: <существительное-2>::= girlfriend | boyfriend
Правила 3 и 8 можно объединить в одно, определяющее и <существительное-1>, и < существительное-2>, введя правило подстановки для нетерминала <существительное>:
Правило 3а: <существительное>::= boy | girl | boyfriend | girlfriend .
Отметим, что эти две грамматики не будут эквивалентными. Предложения будут допустимыми в обеих грамматиках, но с помощью правила 3а могут быть порождены предложения, недопустимые в исходном наборе правил.
Синтаксическое дерево. Введенные правила подстановки можно проиллюстрировать на синтаксическом дереве (рис. 3).

1 <предложение>


<именная группа > 2 4 <глагольная группа>

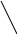


 <сущ.
1> 3 5 <глагол> 6
<группа дополнения>
<сущ.
1> 3 5 <глагол> 6
<группа дополнения>





7 <артикль> 8 <сущ. 2>

The boy | girl has a girlfriend | boyfriend
Рис. 3. Пример синтаксического дерева
Каждый шаг процесса генерации может быть выведен из следующего за ним в иерархии. Начиная с символа <предложение>, применяя правила подстановки можно получить несколько промежуточных форм, содержащих как терминальные, так и нетерминальные символы. Все формы, выводимые с помощью правил грамматики, называются сентенциальными формами. Сентенциальные формы, содержащие только терминальные символы, являются допустимыми предложениями языка.
Применяя правила 1, 2, 4 и 5 можно получить следующую сентенциальную форму: The <существительное-1> has <группа дополнения>.
Одна сентенциальная форма может быть выведена применением правил подстановки в порядке 1, 4, 5, 2 или 1, 4, 2, 5. Однако для любого допустимого в данной грамматике предложения существует единственное синтаксическое дерево, а варьироваться может только порядок применения правил, с помощью которых оно порождается. Предложение некоторой грамматики является неоднозначным, если для него существует более одного синтаксического дерева. Грамматика, содержащая хотя бы одно неоднозначное предложение, неоднозначна. Грамматики языков проектирования должны быть однозначными.
Процедура, используемая при выводе синтаксического дерева для некоторого предложения, называется грамматическим разбором. Для того, чтобы избежать какой-либо неоднозначности, алгоритмы грамматического разбора всегда просматривают сентенциальные формы слева направо. Первый символ слева, идентифицируемый как допустимое выражение, или как терминальный, или нетерминальный символ языка будет первой частью синтаксического дерева. Таким образом, для того, чтобы решить, допустимо ли в нашей грамматике предложение “The boy has a boyfriend”, начиная с левой стороны, следует применить следующие правила подстановки, ведущие к выражению <предложение> – 3, 2, 5, 7, 8, 6, 4, 1.
Грамматический разбор, начинающийся с левой стороны сентенциальной формы, при котором первым применяется правило подстановки, сворачивающее самые левые элементы, называется каноническим разбором. Символ или группа символов, сворачиваемые на первом шаге, называются основой формы. Основой разбиравшегося выше предложения является “boy”. Основой сентенциальной формы, полученной после свертки первого символа (The <существительное-1> has a boyfriend) , является комбинация “The <существительное-1>”, которая сворачивается в нетерминальный символ <именная группа>. Этот грамматический разбор может быть продолжен до тех пор, пока не будет достигнут символ <предложение>. Последней основой будет <именная группа><глагольная группа>.
В однозначном языке существует один и только один канонический разбор для любого предложения языка, а для каждой сентенциальной формы существует единственная основа.
Рекурсия. В рассмотренных ранее примерах порождается только конечное число предложений. Таких грамматик было бы недостаточно для определения даже всех целых чисел и тем более для описания любого языка программирования высокого уровня.
Для того чтобы расширить возможности языка, допускаются рекурсивные определения. Т. е. использование для описания некоторых конструкций языка самих описываемых конструкций. Рекурсия может быть явной и неявной. Явная – когда в правой части некоторой формулы используется металингвистическая переменная из левой части этой же формулы, например,
<константа> ::= <цифра><константа> | <цифра>.
В явно рекурсивном правиле обязательно должна содержаться нерекурсивная часть, т. к. только в этом случае возможен вывод. Неявная рекурсия присутствует в случае, когда при выводе конструкции используется переменная, обозначающая саму выводимую конструкцию, например,
<выражение> ::= <терм>
<терм> ::= <множитель>
<множитель> ::= (<выражение>).
Грамматика языка называется непосредственно леворекурсивной, если она содержит правила вида
<нт-А>::=<нт-А>В,
непосредственно праворекурсивной, если она содержит правила вида
<нт-А>::=В<нт-А>,
и грамматикой с непосредственным самовставлением, если содержит правила вида
<нт-А>::=В<нт-А>С,
где <нт-А> – нетерминальный символ языка;
В, С – символы или комбинации символов языка ( терминальных и (или) нетерминальных).
Для выхода из рекурсии необходимо применять другие правила (варианты правой части). В качестве примера рассмотрим один из вариантов грамматики десятичных чисел:
<десятичное число>::=<смешанное число><цифра> | <десятичное число><цифра>
<смешанное число>::=<целое><десятичная точка>
<целое>::=<знак><цифра> | <целое><цифра>
<десятичная точка>::= .
<знак>::= + | -
<цифра>::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Классификация языков по Н. Хомскому. Формальная грамматика – абстрактное обобщение грамматики естественных языков – рассматривает строки (цепочки) символов. Н. Хомский дал следующее определение :
Формальная (порождающая) грамматика есть упорядоченная четверка
G = (V, T, P, Z),
где
V – конечное непустое множество символов (терминальный словарь);
T – конечное непустое множество символов (нетерминальный словарь);
P – конечное непустое множество правил (продукций), каждое из которых есть цепочка вида α —› β, где α и β – цепочки в объединенном словаре V T, символ “—›” – разделитель правила на левую и правую части (α – левая, β – правая); символ “—›” не принадлежит V T и α ε;
Z – выделенный элемент нетерминального словаря (начальный символ грамматики).
Порождающая грамматика Хомского является механизмом порождения цепочек. Она не задает алгоритм порождения. С этой точки зрения порождающая грамматика Хомского является исчислением, подобно исчислению высказываний: высказывание соответствует символам цепочки, а логические операции – правилам.
Язык, порождаемый грамматикой, – это множество терминальных цепочек, которые можно вывести из Z. Вывод всегда начинается с начального символа Z. Правила грамматики определяют, как конструкции языка строятся из других конструкций и символов. Язык не определяет однозначно грамматику, его порождающую. Один и тот же язык может быть порожден бесконечным числом различных эквивалентных грамматик.
Основная идея синтаксически управляемой трансляции – использование структуры входной цепочки при вычислении ее “смысла”. Структура цепочки определяется порядком ее вывода из начального символа по правилам грамматики. Распознаватель по заданной входной цепочке и грамматике строит структуру входной цепочки и передает ее блоку генерации. Для построения распознавателя необходимо иметь алгоритм, который по заданной грамматике строит вывод любой цепочки языка, порождаемого этой грамматикой.
Доказано, что такого алгоритма для произвольной грамматики Хомского не существует. В связи с этим имеются две возможности:
1) для каждой грамматики Хомского разрабатывать свой алгоритм распознавания;
2) наложить ограничения на правила грамматики и выделить подклассы грамматик, для которых алгоритм распознавания не только существует, но и является достаточно эффективным.
Второй подход является более предпочтительным. Хомский определил четыре основных класса языков в терминах грамматик. Различие четырех типов грамматик заключается в форме правил подстановки допустимых в P.
Грамматика типа 0 или грамматика с фразовой структурой не накладывает никаких ограничений на правила подстановки. Язык, который описывается такой грамматикой, называют рекурсивно-перечислимым. Применительно к языкам программирования такие грамматики обладают излишней общностью.
Грамматика типа 1 или контексно-зависимая, накладывает следующее ограничение на правила подстановки:
xUy ::= xuy,
где U – некоторый нетерминальный символ;
x, u, y – терминальные или нетерминальные символы и (или) их комбинации, причем x не пусто.
Подстановка U::=u имеет силу только в контексте x…y.
Грамматика типа 2 или контекстно-свободная если все ее правила имеют вид:
U::=u.
Символ U можно заменить цепочкой u, не обращая внимания на контекст, в котором он встретится. Большинство языков программирования удовлетворяют этому требованию. Система обозначений БНФ эквивалентна типу 2 по Хомскому.
Грамматика типа 3 или регулярная грамматика (автоматная) допускает только правила вида:
U::=<терминал> или U::=<нетерминал><терминал>.
Сентенциальные формы, генерируемые регулярной грамматикой, могут обрабатываться автоматом с конечным числом состояний, и большинство действий, выполняемых при лексическом анализе, базируются на таких грамматиках.
Отметим, что для 0-го типа грамматик универсального алгоритма распознавания не существует; для 1-го типа алгоритм существует, но он не эффективен; для 2-го типа существует более эффективный алгоритм; для 3-го типа существует простой и эффективный алгоритм.
Как уже отмечалось, язык может быть задан различными грамматиками. Поэтому возникает заманчивая идея – найти для каждого языка автоматную грамматику. Но доказано, что существуют контекстно-свободные языки, не являющиеся автоматными. Пример такого языка L = {an, bn, cn | n 1}. Существуют рекурсивно-перечислимые языки, не являющиеся контекстно-свободными языками.
Отметим, что почти все алгоритмические универсальные языки являются контекстно-свободными языками, а многие специализированные языки являются автоматными. Т. е. контекстно-свободные и регулярные грамматики используются в основном для определения языков программирования и при разработке компиляторов.
Лексический анализ. Первый шаг компиляции заключается в чтении элементов исходной программы и разделении их на надлежащие синтаксические классы. Эти символы или обозначения будут использоваться на более поздних стадиях для интерпретации значений исходных операторов и подготовки объектного кода. Для того, чтобы облегчить построение и работу последующих фаз компилятора, первая его фаза – лексический анализатор вырабатывает из первичных обозначений исходной программы однородные символы фиксированного размера. Основные элементы исходной программы помещаются затем в таблицу однородных символов. Для каждого обозначения указывается его синтаксический класс (целое, идентификатор, ограничитель, зарезервированное слово), и с помощью указателя задается место, в котором хранится его исходная форма. Так выполняется первый шаг построения таблиц литералов и идентификаторов. Последующие фазы компилятора заносят в эту таблицу дополнительную информацию об элементах (точность, длина, класс памяти и отведенное место в памяти). Во время лексического анализа различные представления стандартизируются, а комментарии и избыточные элементы отбрасываются. Выход лексического анализатора представляет собой обычно язык типа 2. Чтобы облегчить задачу последующей работы синтаксического и семантического анализаторов, хороший лексический анализатор заменяет символы исходного языка, имеющие один и тот же вид, но различные значения. При этом становится проще грамматика, определяющая структуру языка, и из последующих фаз компиляции исключаются контекстно-зависимые правила подстановки.
Рассмотрим пример лексического анализа фрагмента программы на языке PL/1.
PLN | : | PROCEDURE | ( | ALFA | , | X | ) | ;
DECLARE | ( | ALFA | , | X | , | R | ) | BINARY | FIXED | ( | 31 | ) | ;
R | = | ALFA | * | ( | X | - | 3 | ) | ** | 2 | + | ( | X | - | 3 | ) | + | 10 | ;
RETURN | ( | R | ) | ;
END | ;
Имеются таблицы:
-
К
Ключевые слова
R
Разделители
1
BEGIN
.
.
2
BINARY
13
:
3
CALL
.
.
4
DECLARE
.
.
.
.
20
(
.
.
21
)
.
.
22
,
21
PROCEDURE
.
.
.
.
.
.
Формируются таблицы:
-
I
Идентификаторы
C
Константы
1
PLN
…
1
31
…
2
ALFA
…
2
3
…
3
X
…
3
2
…
4
R
…
4
10
…
.
.
…
.
.
…
Таблица однородных (стандартных) символов:
-
Класс
Указатель
I
1
—›
PLN
R
13
—›
:
K
21
—›
PROCEDURE
R
20
—›
(
I
2
—›
ALFA
R
22
—›
,
I
3
—›
X
R
21
—›
)
R
…
—›
;
K
4
—›
DECLARE
R
20
—›
(
…
…
…
…
Выделение лексического анализа. Лексический анализ может выполняться как отдельный проход. Лексический анализатор в этом случае выполняет полный анализ исходной программы и вырабатывает в конце прохода таблицу однородных символов. С другой стороны, он может быть запрограммирован в виде подпрограммы синтаксического анализатора, которая вызывается всякий раз, когда анализ предыдущего символа завершен и синтаксическому анализатору требуется новый символ.
В компиляторах используются оба этих подхода, но в любом случае лексический анализ отделяется от синтаксического и семантического. Основная причина заключается в том, что синтаксис лексических анализаторов может описываться очень простыми грамматиками (обычно регулярными грамматиками), и если их функции выделены, то могут быть применены более эффективные методы грамматического разбора. Другая причина в том, что существуют различные представления одного и того же языка на лексическом уровне. Здесь выделение лексического анализа позволяет иметь один общий синтаксический анализатор, а для подключения любого конкретного представления требуется только соответствующий лексический анализатор. Когда язык управления заданиями определяет вводное устройство для исходной программы, компилятор автоматически выбирает соответствующий ему лексический анализатор.
Диаграмма состояний. Правила лексического анализа для большинства языков программирования либо непосредственно описываются регулярной грамматикой, либо становятся пригодными для такого описания после минимальных изменений и (или) переупорядочивания. Графически эти правила можно представить с помощью диаграммы состояний. Первая часть правила подстановки является “текущим” состоянием, вторая (правая) – “следующим”. Правило подстановки представляется посредством стрелки, соединяющей два состояния и указывающей, что возможен переход от текущего состояния к следующему при выполнении некоторого условия. Теоретическая машина, выполняющая переходы между различными состояниями системы, называется конечным автоматом.
Рассмотрим работу конечного автомата лексического анализа распознавания десятичных чисел, грамматику которых мы рассмотрели ранее (рис. 4). Входная строка анализируется элемент за элементом для проверки, удовлетворяет ли она правилам подстановки, определяющим десятичное число.

ЗНАК

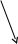 +
+
цифра
цифра . цифра





 СТАРТ
ЦЕЛОЕ СМЕШ. ЧИСЛО
ДЕС. ЧИСЛО
СТАРТ
ЦЕЛОЕ СМЕШ. ЧИСЛО
ДЕС. ЧИСЛО
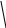


цифра цифра
Рис. 4. Пример диаграммы состояний автомата,
распознающего десятичные числа
Сначала автомат находится в состоянии “Старт”. Если первым элементом является “+” или “-”, он переходит в состояние “Знак”; если первый элемент – цифра, он переходит в состояние “Целое”. Если же первый элемент не является ни тем, ни другим, то идентификация заканчивается неудачей и элемент не является десятичным числом.
Автомат переключается из состояния “Знак” в состояние “Целое”, если во входной строке распознается цифра, и изменяет состояние с “Целое” на “Смешанное число”, если найдена десятичная точка. Если в состоянии “Знак” следующий элемент входной строки не является цифрой, или же в состоянии “Целое” не является ни цифрой, ни десятичной точкой, автомат сигнализирует о том, что строка не является десятичным числом. Когда после десятичной точки обнаруживается цифра, автомат переключается из состояния “Смешанное число” в состояние “Десятичное число” и остается в нем до тех пор, пока будут распознаваться цифры, или пока не исчерпается входная строка, или идентификация заканчивается неудачей.
При анализе следующие строки приведут к соответствующим переходам из одного состояния в другое:
a) 123.45 Ц, Ц, Ц, СЧ, ДЧ, ДЧ;
b) 12.34.6 Ц, Ц, СЧ, ДЧ, ДЧ, не десятичное число;
c) - 0.0001 З, Ц, СЧ, ДЧ, ДЧ, ДЧ, ДЧ;
d) . 123 не десятичное число;
e) А12 не десятичное число;
f) + 91. З, Ц, Ц, СЧ, не десятичное число.
В случаях (b) и (e) ясно, что строку нельзя идентифицировать как десятичное число. В случаях (d) и (f) это не очевидно (накладываются ограничения определения).
Матрица переходов состояний. Введенное понятие диаграммы состояний полезно для лексического анализа, но не может быть достаточно хорошо представлено в ЭВМ. Поэтому вводится матрица переходов состояний. Каждая строка этой матрицы представляет состояние автомата, а каждый столбец соответствует возможному входному элементу. Процесс начинается в состоянии 1 (“Старт”), а появляющиеся во входной строке элементы определяют следующее состояние, в которое переходит распознающий автомат. Десятичное число распознается, если в конце строки достигается положение “ВЫХОД”, или, если символы не отделяются специальными элементами, то положение “ВЫХОД” указывает на конец записи десятичного числа.
Все лексические анализаторы обеспечивают выдачу диагностических сообщений при обнаружении ошибок. Большинство из них параллельно с распознаванием вычисляют также значения числовых констант. Поэтому элементы матрицы переходов состояний могут содержать указатели на подпрограммы, вычисляющие численные значения или выполняющие другую обработку, или обеспечивающие выдачу диагностических сообщений об ошибках. Каждый элемент матрицы задает либо определенные действия, если следующий входной элемент соответствует допустимому переходу, либо конкретную ошибку в формате входных элементов.
Матрица переходов состояний для распознавания десятичных чисел
-
Состояние
Следующий элемент
Знак
Дес. точка
Цифра
Прочие
1. Старт
2, А1
D1
3, А2
D1
2. Знак
D2
D3
3, A2
D4
3. Целое
D5
4
3, A2
D5
4. Смеш. число
D6
D7
5, A3
D6
5. Дес. число
ВЫХОД
D7
5, A3
ВЫХОД
Подпрограммы, выполняемые при распознавании десятичных чисел
(ц – значащие цифры, зн – значение знака во входной строке)
-
Подпрограмма
Действие
инициализация
Ц = 0, З = +, Д = 1.0
A1
З = зн
А2
Ц = 10 * Ц + ц
А3
Д = Д / 10.0 ; Ц = Ц + ц * Д
Диагностические сообщения при распознавании десятичных чисел
-
Обозначение
Текст сообщения
D1
Строка не является десятичным числом, она не начинается с
+, - или цифры
D2
Ошибка. Два знака последовательно
D3
Не десятичное число. Десятичной точке не предшествует
хотя бы одна цифра
D4
Не десятичное число. За знаком не следует цифра. Строка
является ограничителем со значением равным знаку
D5
Не десятичное число. Строка представляет собой целое
число, имеющее значение ЗЦ
D6
Не десятичное число. За десятичной точкой не следует цифра
D7
Ошибка. Две десятичные точки в числе
ВЫХОД
Строка – десятичное число, имеющее значение ЗЦ
Не все сообщения действительно указывают на ошибки. Некоторые из них, такие как D1, констатируют только, что данная строка не является десятичным числом. В этом случае лексический анализатор попытается подогнать данный символ под другой синтаксический класс.
Лексический анализ, описанный с помощью матрицы переходов состояний, легко преобразовывается в программу. Чтобы сделать программу более экономичной, условия не проверяются по отдельности. Переходы и действия занумерованы, и их значения хранятся в двух отдельных матрицах. Текущее состояние и следующий элемент определяют, какие элементы этих матриц должны быть выбраны, а те в свою очередь задают следующую подпрограмму и состояние, в которое должна перейти система.
Распознавание идентификаторов, зарезервированных слов и операторов выполняется аналогично. Зарезервированные слова языка представляют собой специальные идентификаторы, которые определенным образом помечаются в таблице однородных символов. Если зарезервированные слова ограничиваются специальными литерами, эти помечающие литеры опускаются, и только заключенная между ними строка используется для поиска в таблице, содержащей список всех зарезервированных слов. Такие специальные литеры только инициируют и завершают этот поиск. Те же алгоритмы применяются к литерам или символам, которые имеют определенное значение в исходном языке, таким как +, -, = или DO, WRITE и т. д. Здесь необходима определенная осторожность, поскольку двухлитерные символы, такие как /*; */; **; := имеют значения совершенно отличные от значений их отдельных составляющих. Поэтому лексический анализатор всегда строит самый длинный символ из тех, которые можно построить из последовательных литер входной строки. Таким образом, FM138 читается как один идентификатор, а не как идентификатор FM, за которым следует целое 138. Однако здесь существуют исключения. Примером является оператор Фортрана DO10I=1,10, в котором DO10I рассматривается сначала как один идентификатор. Ключевое слово DO может быть распознано лишь после того, как будет обнаружена запятая.
Грамматический разбор. После того, как на этапе лексического анализа программа разбивается на ее основные элементы, следующая фаза компилятора должна распознавать выражения, составленные из этих элементов, и интерпретировать их смысл. Некоторые компиляторы уже на этой стадии вырабатывают код, готовый для выполнения или интерпретации, но большинство из них генерируют промежуточную форму исходной программы, которая будет оптимизироваться перед генерацией машинного кода. Никакой промежуточной формы не генерируется для неисполняемых операторов, таких как DECLARE в PL/1, DIMENSION в Фортране и т. п. Информация, содержащаяся в операторах этого типа, только заносится в таблицы, используемые другими частями компилятора.
Существуют разнообразные методы генерации кода. Рассмотрим два метода: разбор сверху вниз с возвратом, который является наиболее простой процедурой, но сравнительно медленной, и один из способов разбора снизу вверх, связанный с использованием грамматик с операторным предшествованием, который достаточно прост и эффективен, но применение которого ограничено специальным классом грамматик.
Разбор сверху вниз. Грамматический анализатор, работающий сверху вниз, для распознавания и интерпретации допустимых предложений использует синтаксическое определение языка. Он управляется синтаксисом и ориентирован на достижение некоторой цели. На каждой стадии цель заключается в том, чтобы установить, являются ли рассматриваемые строки допустимыми выражениями языка, а предложение – допустимой сентенциальной формой. Если идентифицируемые символы являются нетерминалами, для них аналогичным образом устанавливаются новые подцели до тех пор, пока не останутся одни терминалы, т. е. пока предложение не будет разобрано.
Подцели выбираются слева направо, и если все они удовлетворяются, цель считается достигнутой. Если же удовлетворяются не все подцели, то цель, или хотя бы одна из подцелей, была некорректной. Если грамматика допускает различные правила подстановки для одного и того же нетерминального символа, выполняется возврат для изменения последней альтернативы, давшей некорректную подцель, и процесс продолжается для проверки того, может ли быть реализована новая подцель.
Например, цель заключается в том, чтобы распознавать десятичные числа. Грамматика эквивалентна рассмотренной ранее. Правила подстановки отличаются для иллюстрации того, что одни и те же предложения могут генерироваться различными правилами. Для разбора сверху вниз используются следующие правила подстановки:
a) <десятичное число>::= <целое><дробная часть>
b) <целое>::=<целое без знака> | +<целое без знака> | -<целое без знака>
с) <дробная часть>::= . <целое без знака>
d) <целое без знака>::= <цифра><целое без знака> | <цифра>
e) <цифра>::= 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0
Для облегчения ссылок правила помечены буквами, а альтернативы занумерованы в порядке, в котором они появляются в порождающем правиле. С использованием этих определений алгоритм будет применен к (предполагаемым) десятичным числам - 123.45 и + .123.
Первая цель состоит в доказательстве того, что предложение является десятичным числом, сформированным согласно правилу а). Чтобы сделать это, необходимо доказать, что оно начинается с целого, которое теперь становится подцелью. Первые две пробы, шаги 2 и 3, заканчиваются неудачей, но правило b3) допускает, что символ <целое> начинается с терминала “-” (шаг 4).
Следующая подцель в соответствии с правилом b3) заключается в том, чтобы показать, что литеры, следующие за знаком “-”, образуют <целое без знака>. К первым двум литерам (1, 2) применимо праворекурсивное правило d1), так что 1 и 2 распознаются как цифры с помощью е1) и е2). На шагах 11 и 12 это неверно, поскольку за распознанной цифрой (3) следует десятичная точка вместо целого без знака. Поэтому необходим возврат к ближайшему альтернативному правилу подстановки, в результате которого правило, примененное на шаге 9, заменяется на d2). Литера 3 – <цифра>, так что разбор продолжается со следующей за ней десятичной точки “.”, с учетом того, что подцель <целое> уже достигнута.
Ни одно правило не порождает целое вида “-123.”. Поэтому после шага 12 необходим возврат, означающий, что данная строка не <целое>. В соответствии с правилом а) устанавливается новая подцель, по которой за “целым” должна следовать <дробная часть>. Дробная часть начинается с “.” (десятичная точка, правило с), шаг 12а), за которой следует <целое без знака>. Все это распознается на шагах 13-18 аналогично шагам 5-10. Шаги 17 и 18 необходимы для распознавания конца входной строки, который обозначается в таблице отсутствием вводимой литеры. Входная строка исчерпана, все цели достигнуты, и, таким образом, грамматический разбор символа “-123.45” завершен.
Шаг |
Строка цели или подцели |
Цель или подцель |
Правило |
Справедливо |
После возврата |
||
|
Уже идентифицировано |
Текущая литера |
|
|
|
Правило |
Справедливо |
1 |
|
- |
ДЧ |
a |
ДА |
|
|
2 |
|
- |
Ц |
b1 |
НЕТ |
|
|
3 |
|
- |
Ц |
b2 |
НЕТ |
|
|
4 |
|
- |
Ц |
b3 |
ДА |
|
|
5 |
- |
1 |
ЦБЗ |
d1 |
ДА |
|
|
6 |
- |
1 |
ЦФ |
e1 |
ДА |
|
|
7 |
-1 |
2 |
ЦБЗ |
d1 |
ДА |
|
|
8 |
-1 |
2 |
ЦФ |
e2 |
ДА |
|
|
|
-12 |
3 |
ЦБЗ |
d1 |
ДА |
d2 |
ДА |
10 |
-12 |
3 |
ЦФ |
e3 |
ДА |
|
|
11 |
-123 |
. |
ЦБЗ |
d1 |
НЕТ |
|
|
12 |
-123 |
. |
ЦБЗ |
d2 |
НЕТ |
|
|
10а |
-123 |
|
Ц |
а |
ДА |
|
|
11а |
|
. |
ДЧ |
а |
ДА |
|
|
12а |
|
. |
ДрЧ |
с |
ДА |
|
|
13 |
. |
4 |
ЦБЗ |
d1 |
ДА |
|
|
14 |
. |
4 |
ЦФ |
е4 |
ДА |
|
|
15 |
.4 |
5 |
ЦБЗ |
d1 |
ДА |
d2 |
ДА |
16 |
.4 |
5 |
ЦФ |
е5 |
ДА |
|
|
17 |
.45 |
|
ЦБЗ |
d1 |
НЕТ |
|
|
18 |
.45 |
|
ЦБЗ |
d2 |
НЕТ |
|
|
 9
9
Разбор недопустимого десятичного числа +.123.
1 |
|
+ |
ДЧ |
а |
ДА |
|
|
2 |
|
+ |
Ц |
b1 |
НЕТ |
|
|
3 |
|
+ |
Ц |
b2 |
ДА |
b3 |
НЕТ |
4 |
+ |
. |
ЦБЗ |
d1 |
НЕТ |
|
|
5 |
+ |
. |
ЦБЗ |
d2 |
НЕТ |
|
|
Символ “+” распознается как первая литера целого по правилу b2 (шаг 3). Последующей строкой должно быть <целое без знака>, но не существует правила, по которому оно могло бы начинаться с десятичной точки (неудачи на шагах 4 и 5). Поэтому необходим возврат к шагу 3, заменяющий в нем ДА на НЕТ. Единственное оставшееся на этой стадии альтернативное правило – b3, но и его не удается применить, поскольку входная строка не начинается с литеры “-”. Больше альтернативных правил подстановки нет, т. е. число не является допустимым десятичным числом в этой грамматике.
Проблемы разбора сверху вниз. При разборе сверху вниз существенным является порядок, в котором проверяются правила подстановки. Сначала необходимо проверять более сложные правила. В противном случае могло бы оказаться, что в некотором правиле подстановки, таком как <целое без знака>::=<цифра> | <цифра><целое без знака>, вторая возможность никогда не проверялась бы, поскольку если она имеет место, то всегда имеет место и первая, так что анализатор никогда не достиг бы второй альтернативы.
Другая важная проблема анализатора сверху вниз заключается в его неспособности обрабатывать левую рекурсию. Если должно быть распознано такое правило, как <целое>::=<целое><цифра>, алгоритм зацикливается. Для распознавания целого с помощью такого правила сначала должно быть найдено <целое>, для которого анализатор сверху вниз должен обнаружить предыдущее <целое>, и т. д. до бесконечности.
Первую проблему можно обойти, упорядочив надлежащим образом альтернативные правила подстановки. Вторую – изменив исходный набор определяющих язык правил таким образом, чтобы новые правила порождали те же самые предложения, но не содержали левую рекурсию.
Однако основной недостаток анализаторов, работающих сверху вниз, заключается в их медлительности. Вся информация об уже пройденных подцелях должна сохраняться для возможного возврата, и необходимо перепробовать множество возможностей перед тем, как будет достигнут успех. Разбор можно ускорить с помощью так называемого селективного анализа сверху вниз или с помощью применения алгоритмов разбора с быстрым возвратом.
Анализатор сверху вниз с быстрым возвратом работает по следующему принципу. Каждая поставленная подцель должна быть корректной, или же распознается неудача данной цели. Это позволяет также связать синтаксис и семантику. Если установлена некоторая цель или подцель, идентифицированный символ будет обрабатываться настолько далеко, насколько возможно (например, помещение идентификаторов в таблицу символов, литералов – в таблицу литералов или проверка операндов на совместимость типов). Чтобы избежать возврата при разборе сентенциальной формы, первые несколько литер символа проверяются отдельно, и (или) анализатор “заглядывает вперед” в следующий “неохваченный” символ, чтобы выделить единственную возможную альтернативу из различных правил подстановки.
Грамматики с предшествованием. В отличие от анализаторов сверху вниз распознаватели снизу вверх выполняют разбор с помощью многократного поиска самого левого простого выражения, основы сентенциальной формы. Применяя соответствующее правило грамматики, они сворачивают ее в нетерминальный символ.
Если А и В – два последовательных символа сентенциальной формы, то при рассмотрении основы этой формы могут возникнуть следующие ситуации:
a) A является частью основы, а В – нет; (U::=.......А, В – терминал)
b) A и В принадлежат основе; (U::=.....АВ.....)
c) B – часть основы, А – нет; (U::=В............)
d) основное предложение может быть ошибочным, и комбинация АВ не может встречаться в сентенциальной форме.
В случае (а) А предшествует (старше) В, в случае (с) В предшествует (старше) А, а в случаях (b) и (d) не существует отношений старшинства между этими двумя символами, хотя эти случаи и различны.
Если, принимая во внимание все возможные сентенциальные формы языка, для некоторой пары символов существует более чем одно отношение, то такие отношения предшествования совсем не помогают в грамматическом разборе. Однако если существует однозначное отношение предшествования (включая возможность “отсутствия отношения”) для любой пары символов, справедливое для всех сентенциальных форм, то эти отношения будут указывать начало и конец основы. Грамматики, в которых выполняется это условие, называются грамматики с предшествованием.
Грамматика с операторным предшествованием. В грамматике с операторным предшествованием существует однозначное отношение предшествования между операторами (терминальными символами), не зависящее от операндов (нетерминалов), находящихся между операторами. Только операторы определяют, принадлежат ли они одной и той же основе сентенциальной формы или нет; принадлежащие операторам операнды не влияют на грамматический разбор.
Арифметические выражения, составляющие ведущую часть большинства языков программирования для научных применений, могут быть определены грамматикой с операторным предшествованием, построенной на основе правил старшинства арифметических операций. Встречающиеся во многих языках программирования конструкции, отличные от арифметических выражений, могут быть изменены с помощью лексического анализа и преобразованы таким образом, что вход анализатора целиком будет подчиняться правилам грамматики с операторным предшествованием. Анализаторы для грамматик с операторным предшествованием просты и эффективны.
Будем
обозначать начало и конец основы между
двумя операторами символами “—‹
“ и “›—”
соответственно, а если два оператора
принадлежат одной и той же основе,
используем символ “![]() “.
Правила арифметического предшествования
для некоторого ограниченного набора
операторов могут быть записаны следующим
образом.
“.
Правила арифметического предшествования
для некоторого ограниченного набора
операторов могут быть записаны следующим
образом.
оператор |
|- |
+ |
* |
( |
) |
-| |
|- |
|
—‹ |
—‹ |
—‹ |
|
ВЫХОД |
+ |
|
›— |
—‹ |
—‹ |
›— |
›— |
* |
|
›— |
›— |
—‹ |
›— |
›— |
( |
|
—‹ |
—‹ |
—‹ |
|
|
) |
|
›— |
›— |
|
›— |
›— |
-| |
|
|
|
|
|
|
В строке таблицы указывается первый оператор, в столбце – второй, а элемент таблицы задает их отношение предшествования. Пустые элементы таблицы означают, что данные два оператора не могут следовать один за другим (например, за “)“ не может следовать “(”, поскольку между закрывающей и открывающей скобками должен стоять знак “+” или “*”). Если такая комбинация встречается во входной строке, компилятор выдает сообщение об ошибке.
Алгоритм разбора, использующий эту таблицу, очень прост. Сентенциальная форма просматривается слева направо до тех пор, пока не будет найдена пара операторов, для которых установлено отношение ›—. В этом месте находится конец основы, и сентенциальная форма просматривается влево от этой точки до обнаружения первого отношения —‹. Множество символов между —‹ и ›— является основой данной формы.
Для выполнения грамматического разбора используется стек. Стек, иногда называемый магазинной памятью, является основным механизмом почти во всех анализаторах. Рекурсивные определения в вычислительной машине всегда реализуются с помощью стека. Стек содержит упорядоченный набор элементов. Если в стек помещается новый элемент, он добавляется в конец упорядоченного набора, т. е. на вершину стека. При удалении элемента он тоже выбирается из конца набора или из вершины стека. Последний добавленный элемент является единственным доступным и первым удаляемым элементов (последним вошел, первым ушел).
Примеры разбора арифметического выражения и символьной цепочки. В качестве примера использования отношений предшествования, рассмотренных выше, проанализируем выражение |-X+Y*(Z+X)+A-|.
На практике вместо одного стека могут использоваться два. Один для операторов и один для операндов, при этом ни в одном из них не запоминаются отношения предшествования. Рисунок иллюстрирует процесс грамматического разбора, причем вся информация, связанная с занесением в стек и выборкой из него, привязана к верхнему уровню стека.
—‹X+ |
|
—‹Y* |
|
—‹( |
|
—‹Z+ |
|
X›— |
‹— ) |
|- |
|
—‹X+ |
|
—‹Y* |
|
—‹( |
|
—‹Z+ |
—› Т1= Z+X |
|
|
|- |
|
—‹X+ |
|
—‹Y* |
|
—‹( |
|
|
|
|
|
|- |
|
—‹X+ |
|
—‹Y* |
|
|
|
|
|
|
|
|- |
|
—‹X+ |
|
|
|
|
|
|
|
|
|
|- |
|
|
|
|
|
|
|
|
|
|
|
a) |
|
b) |
|
c) |
|
d) |
|
e) |
|
›— |
‹— + |
Т1›— |
‹— + |
Т2›— |
‹— + |
—‹Z+ |
—› Т1=(Т1) |
—‹Y* |
—› Т2=Y*Т1 |
—‹X+ |
—› Т3=X+Т2 |
—‹( |
|
—‹X+ |
|
|- |
|
—‹Y* |
|
|- |
|
|
|
—‹X+ |
|
|
|
|
|
|- |
|
|
|
|
|
|
|
|
|
|
|
f) |
|
g) |
|
h) |
|
+A›— |
‹— -| |
-| |
—‹T3 |
—› Т4=Т3+A |
|- Т4 |
|- |
|
|
|
|
|
i) |
|
j) |
Фактически элементами стека являются не сами символы, а их однородные представления. Это значительно упрощает программирование занесения в стек и выборки из него. Сначала в стек загружается символ “|-”. Следующим оператором является “+”. Таблица предшествования показывает, что |- —‹ +, так что основа не обнаружена, и стек пополняется этим оператором и принадлежащим ему операндом, т. е. элементом “—‹Х+”. Следующий оператор – “*”. Поскольку + —‹ *, стек опять пополняется (b). Это повторяется до тех пор, пока не появится комбинация “+)” на месте “Z+X)”. Из таблицы предшествования имеем + ›— ), поэтому идентифицируется конец основы. В стек не добавляется никаких новых элементов, и обрабатывается первое выражение. Им является “T1=Z+X”, поскольку первый знак —‹ находится в стеке перед “Z” (e). Т1 и все последующие символы Ti являются временными хранилищами, для которых компилятор выделяет пространство.
На вершине стека теперь находится “—‹(Т1)”. Следующим оператором является “+”. Комбинация “)+” ограничивает основу, поэтому скобки удаляются, и вместо цепочки “—‹(T1)›—” на вершину стека устанавливается “Т1”. Это допустимо, поскольку эти два оператора являются частью одной и той же основы из-за отношения . Следующим оператором является “+”, и для комбинации “*+” выполняется отношение ›—. Поэтому снова идентифицируется основа “T2=Y*T1” (g). На вершине стека теперь “+”, и следующий оператор все еще “+”. Между ними выполняется отношение ›—, поэтому последний символ снова удаляется с вершины стека и заменяется на “Т3=Х+Т2” (h). Так как теперь отношение ›— не выполняется, оператор “+” может быть помещен в стек со своим операндом “А”. Следующий элемент “-|” заканчивает основу, поэтому обрабатывается и помещается в стек “Т4=Т3+А”. На этом завершается также и разбор выражения. Этот пример характерен для использования таблиц предшествования со стеком в синтаксическом анализе, хотя на практике существует множество вариаций этого метода.
Рассмотрим грамматику:
Z ::= bMb
M ::= (L | a
L ::= Ma)
Таблица предшествования для данной грамматики
|
Z |
b |
M |
L |
a |
( |
) |
Z |
|
|
|
|
|
|
|
b |
|
|
|
|
—‹ |
—‹ |
|
M |
|
|
|
|
|
|
|
L |
|
›— |
|
|
›— |
|
|
a |
|
›— |
|
|
›— |
|
|
( |
|
|
—‹ |
|
—‹ |
—‹ |
|
) |
|
›— |
|
|
›— |
|
|
Разбор сентенциальной формы b(aa)b:
Шаг |
Сентенциальная форма |
Основа |
Привести основу к |
Построенный Непосредственный вывод |
1 |
b ( a a ) b |
a |
M |
b(Ma)b b(aa)b |
|
—‹ —‹ ›— ›— |
|
|
|
2 |
b ( M a ) b |
Ma) |
L |
b(Lb b(Ma)b |
|
—‹ —‹ ›— |
|
|
|
3 |
b ( L b |
(L |
M |
bMb b(Lb |
|
—‹ ›— |
|
|
|
4 |
b M b |
bMb |
Z |
Z bMb |
|
|
|
|
|
Матричное представление синтаксического дерева. Результаты работы рассмотренного выше алгоритма грамматического разбора могут быть графически представлены в виде синтаксического дерева (дерева разбора).

Т4 +


Т3 + A


X T2 *

Y T1 +

Z X
“Индексы” временных ячеек памяти Т1, Т2, Т3 и Т4 указывают последовательность, в которой вычисляются промежуточные результаты. Эта структура неудобна для использования в ЭВМ. Вместо нее многие компиляторы используют матричное представление деревьев разбора. В такой матрице операции программы перечисляются в порядке, в котором они разбираются на фазе синтаксического анализа.
Каждая запись матрицы содержит один оператор и два операнда
№ строки матрицы (врем. яч. памяти) |
Оператор |
Операнд 1 |
Операнд 2 |
Т1 |
+ |
Z |
X |
T2 |
* |
Y |
T1 |
T3 |
+ |
X |
T2 |
T4 |
+ |
T3 |
A |
Операндами являются однородные символы, построенные лексическим анализатором и ссылающиеся на фактические операнды с помощью указателей. Матричное представление синтаксического дерева является внутренней формой исходной программы, вырабатываемой первыми двумя проходами компиляторами, лексическим и синтаксическим анализатором.
Генерация кода и оптимизация. Промежуточная форма, вырабатываемая синтаксическим анализатором, оптимизируется двумя способами. В первом из них модифицируются выражения и переупорядочиваются операторы для того, чтобы избежать дублируемых или излишних вычислений. Эта оптимизация машинно-независима и базируется на правилах обычной и булевой алгебры.
Машинно-независимая оптимизация (МНО) включает следующие основные шаги:
– повторные вхождения общих подвыражений в один и тот же арифметический оператор исключаются из матрицы. Их значение вычисляется только один раз при первом появлении. Любое последующее вхождение ссылается на временное место в памяти, отведенное в соответствующей строке матрицы;
– все операции, оба операнда которых константы, выполняются во время компиляции и заменяются вычисленным значением;
– вычисления, включающие только неизменяемые в цикле операнды, выносятся из цикла;
– правила булевой алгебры используются для упрощения сложных условных операторов;
– изменяется порядок вычислений, в особенности при ветвлениях, для того, чтобы сократить вычисления выражений в сложных условных операторах.
Пример МНО. Следующий алгоритм может быть применен для исключения общих подвыражений и для выполнения вычислений, включающих константы, во время компиляции:
a) Определить границы предложений (для арифметических операторов выделить оператор “=“).
b) Для всех записей матрицы упорядочить в алфавитном порядке коммутативные операторы (+, *).
c) Выявить идентичные тройки (оператор, операнд 1, операнд 2) внутри одного предложения. Исключить все кроме первого. Изменить все указатели вперед и назад, расположенные до и после исключенных записей.
d) Исправить остальные записи матрицы, ссылающиеся на исключенные записи.
e) Выявить в матрице записи, оба операнда которых литералы.
f) Вычислить выражение и создать новый литерал.
g) Исключить старую запись и заменить все ссылки на нее однородным символом, представляющим новый литерал.
h) Повторять этот процесс от a) до h) для вновь созданных подвыражений или константных операндов, пока этот процесс приводит к каким-либо изменениям в матрице.
i) Исключить из таблицы временной памяти (часть таблицы идентификаторов) все записи, относящиеся к исключенным строкам матрицы.
Пример оптимизации фрагмента программы: А = А + С + 16 * 25
В = А + С + ( С + А ) * D
Матрица разбора
№ записи (времен. пам.) |
Оператор |
Операнд 1 |
Операнд 2 |
Указатель назад |
Указатель вперед |
|
|
перед оптимизацией |
|
|
|
Т1 |
+ |
А |
С |
0 |
2 |
Т2 |
* |
16 |
25 |
1 |
3 |
Т3 |
+ |
Т2 |
Т1 |
2 |
4 |
Т4 |
= |
А |
Т3 |
3 |
5 |
Т5 |
+ |
А |
С |
4 |
6 |
Т6 |
+ |
С |
А |
5 |
7 |
Т7 |
* |
Т6 |
D |
6 |
8 |
Т8 |
+ |
Т5 |
Т7 |
7 |
9 |
Т9 |
= |
В |
Т8 |
8 |
10 |
Т10 |
|
|
|
|
|
|
|
после шагов а) и b) |
|
|
|
Т1 |
+ |
А |
С |
0 |
2 |
Т2 |
* |
16 |
25 |
1 |
3 |
|
+ |
Т1 |
Т2 |
2 |
4 |
(А) |
= |
А |
Т3 |
3 |
5 |
|
+ |
А |
С |
4 |
6 |
|
+ |
А |
С |
5 |
7 |
Т7 |
* |
D |
Т6 |
6 |
8 |
|
+ |
Т5 |
Т7 |
7 |
9 |
(В) |
= |
В |
Т8 |
8 |
10 |
Т10 |
|
|
|
|
|
|
|
после шагов с) и d) |
|
|
|
Т1 |
+ |
А |
С |
0 |
2 |
Т2 |
* |
16 |
25 |
1 |
3 |
Т3 |
+ |
Т1 |
Т2 |
2 |
4 |
(А) |
= |
А |
Т3 |
3 |
5 |
Т5 |
+ |
А |
С |
4 |
7 |
|
|||||
Т7 |
* |
D |
Т5 |
5 |
8 |
Т8 |
+ |
Т5 |
Т7 |
7 |
9 |
(В) |
= |
В |
Т8 |
8 |
10 |
Т10 |
|
|
|
|
|
|
после машинно-независимой оптимизации |
|
|||
|
+ |
А |
С |
0 |
3 |
|
|||||
Т3 |
+ |
Т1 |
400 |
1 |
4 |
(А) |
= |
А |
Т3 |
3 |
5 |
Т5 |
+ |
А |
С |
4 |
7 |
Т7 |
* |
D |
Т5 |
5 |
8 |
Т8 |
+ |
Т5 |
Т7 |
7 |
9 |
(В) |
= |
В |
Т8 |
8 |
10 |
Т10 |
|
|
|
|
|
 Т3
Т3
 Т5
Т5 Т6
Т6 Т8
Т8
 ----------------------------------------
исключена ---------------------------------------
----------------------------------------
исключена --------------------------------------- Т1
Т1 ----------------------------------------
исключена ---------------------------------------
----------------------------------------
исключена ---------------------------------------В матрице разбора отмечены записи, изменяемые во время оптимизирующих шагов. Кроме того, для ясности вместо однородных символов используются исходные.
Хотя записи 1, 5 и 6 идентичны, и 1, и 5 должны быть сохранены, поскольку они расположены в различных предложениях, и значения А, используемые в строках 1 и 5, не одинаковы.
Оптимизированный машинно-независимым образом код содержит 7 команд и требует 5 ячеек памяти для промежуточных величин в отличие от 9 команд и 9 ячеек для неоптимизированного кода.
Генерация кода. Объектный код может непосредственно генерироваться из матрицы, созданной синтаксическим анализатором и интерпретатором и, возможно, оптимизированной машинно-независимым оптимизатором. Простейшее решение заключается в использовании таблицы порождаемого кода, связанной с объектным кодом, который должен генерироваться для каждого оператора матрицы.
L 1,&OP1 Загрузить OP1 в регистр-1 L 1,&OP1
A 1,&OP2 Прибавить OP2 в регистр-1 M 0,&OP2 Умножить ре-
ST 1,&T1 Записать регистр-1 в Т1 ST 1,&T1 гистр на ОР2
a) b)
Простая таблица порождаемого кода для сложения (а) и умножения (b). &OP1 и &OP2 – первый и второй операнды, &T1 – отведенная под результат временная память. Здесь показаны стандартные определения кода для сложения и умножения операндов с фиксированной точкой. Это наиболее примитивное решение, и в практических реализациях даже для таких простых команд используются более сложные схемы.
На стадии генерации кода компилятор просматривает последовательно строки матрицы, и для каждой из них генерирует код, определенный для оператора, содержащегося в этой строке, и включающий его операнды. Это можно рассматривать как макровызов, в котором имя макроса определяется оператором, а параметрами макроса являются операнды и отведенная под результат временная память, указанные в строке матрицы.
Использование таблицы порождаемого кода, рассмотренной выше, позволяет сгенерировать неоптимизированный код из матрицы разбора для выражения:
X + Y * ( Z + X ) + A.
Номер |
Строки матрицы |
Генерируемый код |
|||
команды |
Оператор |
Операнд 1 |
Операнд 2 |
Неоптимизир. |
Оптимизир. |
1 |
|
|
|
L 1, Z |
L 1, Z |
2 |
+ |
Z |
X |
A 1, X |
A 1, X |
3 |
|
|
|
ST 1, T1 |
|
4 |
|
|
|
L 1, Y |
|
5 |
* |
Y |
T1 |
M 0, T1 |
M 0, Y |
6 |
|
|
|
ST 1, T2 |
|
7 |
|
|
|
L 1, X |
|
8 |
+ |
X |
T2 |
A 1, T2 |
A 1, X |
9 |
|
|
|
ST 1, T3 |
|
10 |
|
|
|
L 1, T3 |
|
11 |
+ |
T3 |
A |
A 1, A |
A 1, A |
12 |
|
|
|
ST 1, T4 |
ST 1, T4 |
Если операнды представлены в формате с плавающей точкой или в десятичной форме, то должны генерироваться другие команды. Если же операнды имеют различные форматы, должны быть сгенерированы команды преобразования, приводящие их к общей форме, над которой можно выполнять операцию, а также преобразующие результат в требуемое представление.
Машинно-зависимая оптимизация. При рассмотрении неоптимизированного кода (см. выше) становится очевидным, что код, генерируемый из оптимизированной матрицы с использованием простой таблицы порождаемого кода, далек от оптимального. Команды 9 и 10 сохраняют и загружают одни и те же данные и, следовательно, являются избыточными. Они сразу могут быть исключены из окончательного объектного кода. Также очевидно, что Y * T1 эквивалентно T1 * Y. Поэтому команды 3 и 4 можно исключить, если команду 5 заменить на M 0, Y, поскольку Т1 уже находится в регистре-1 в качестве результата предыдущей команды. Аналогично, команды 6 и 7 также могут быть опущены. Оптимизированный код будет тогда содержать 6 команд и занимать только 24 байта по сравнению с 12 командами и 48 байтами неоптимизированного кода и потребует только одного слова дополнительной временной памяти (Т4) вместо четырех (Т1, Т2, Т3, Т4).
В большинстве современных вычислительных машин для вычислений могут использоваться несколько регистров. Другим важным моментом в связи с машинно-зависимой оптимизацией является надлежащее использование общих регистров и выбор наиболее эффективных форматов команд.
Генерация кода для выражения (B + D + A) * (D + B + C).
Исходная матрица |
Машинно-независимо оптимизированная |
Код, генерируемый из оптимизируемой матрицы |
||||||||
Н |
О |
О |
О |
Н |
О |
О |
О |
Неоптимизи- |
Оптимизированный |
|
о |
п |
п |
п |
о |
п |
п |
п |
рованный |
код |
|
м |
|
|
|
м |
|
|
|
код |
с использ. |
с использов. |
е |
о |
д |
д |
е |
о |
д |
д |
|
одного |
нескольких |
р |
р |
1 |
2 |
р |
р |
1 |
2 |
|
регистра |
регистров |
|
|
|
|
|
|
|
|
L 1, B |
L 1, B |
L 1, B |
T1 |
+ |
B |
D |
T1 |
+ |
B |
D |
A 1, D |
A 1, D |
A 1, D |
|
|
|
|
|
|
|
|
ST 1, T1 |
ST 1, T1 |
|
|
|
|
|
|
|
|
|
L 1, A |
|
L 3, A |
T2 |
+ |
A |
T1 |
T2 |
+ |
A |
T1 |
A 1, T1 |
A 1, A |
AR 3, 1 |
|
|
|
|
|
|
|
|
ST 1, T2 |
ST 1, T2 |
|
T3 |
+ |
D |
B |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
L 1, C |
L 1, C |
L 5, C |
T4 |
+ |
C |
T3 |
T3 |
+ |
C |
T1 |
A 1, T1 |
A 1, T1 |
AR 5, 1 |
|
|
|
|
|
|
|
|
ST 1, T3 |
|
|
|
|
|
|
|
|
|
|
L 1, T2 |
|
|
T5 |
* |
T2 |
T4 |
T4 |
* |
T2 |
T3 |
M 0, T3 |
M 0, T2 |
MR 2, 5 |
|
|
|
|
|
|
|
|
ST 1, T4 |
ST 1, T4 |
ST 3, T4 |
Оптимизированный код использует три различных регистра для вычисления и хранения промежуточных результатов B + D, B + D + A и B + D + C, и, если это возможно, генерируется более быстрая команда типа RR вместо RX-команды. Вторая оптимизированная версия работает быстрее и занимает на 10 байт меньше (плюс 8 байт временной памяти для Т1 и Т2), чем первая, из-за исключения одной команды и замены трех RX-команд более быстрыми и более компактными RR-командами.
Т. о. цель машинно-зависимой оптимизации состоит в уменьшении как размеров памяти, требующейся для работы программы, так и времени выполнения объектной программы за счет учета аппаратных характеристик машины. Поскольку фактическая генерация кода не управляется программистом, она должна автоматически выполняться компилятором. Это достигается посредством замены простой таблицы порождаемого кода более сложной. Естественно, что более эффективный объектный код получается за счет увеличения размеров компилятора и времени компиляции.
Простой способ оптимизации использования регистра при генерации объектного кода заключается в отслеживании его содержимого во время выполнения программы. Если какой-либо из операндов элемента матрицы, для которого генерируется код, уже находится в регистре, то этот регистр и будет использоваться для выполнения операции (при условии, что его содержимое не должно быть сохранено для последующего использования), и в этом случае отпадает необходимость в загрузке операнда. Для исключения излишних команд засылки в память содержимое регистра сохраняется только в случае, если регистр должен использоваться для некоторых других целей. Нет необходимости записывать в память результат операции для кода, генерируемого по строке матрицы. Он может быть сохранен для следующей использующей его строки на регистре, который в этом случае участвует в формировании команд по этой строке, выполняя между строками функции вспомогательной памяти.
Так как общие регистры используются также в качестве базовых и индексных регистров для адресации, количество регистров, доступных при генерации кода, меньше, чем общее количество общих регистров (около шести, если имеется 16 общих регистров).
“Оптимизированную” таблицу порождаемого кода можно рассматривать как эквивалент условного макроса. Условиями, от которых зависят генерируемые команды, являются:
– один из операндов уже находится в регистре, содержимое которого не должно сохраняться;
– операция может использовать пустой регистр;
– оба операнда имеют одно и то же представление, и над этим представлением допускается операция.
Генерируемый на этой стадии код является машинным кодом, либо помещаемым в фиксированные места основной памяти для компиляторов типа трансляция-выполнение, либо сохраняемым в виде объектного модуля, или же кодом на языке ассемблера, для которого, возможно, уже построена таблица символов.
В первом случае должны быть переопределены только ссылки на метки. Во втором – должна быть передана также дополнительная информация для загрузчика. В третьем случае необходимо выполнить один или два прохода ассемблера для порождения окончательного объектного кода, который может впоследствии обрабатываться загрузчиком. Эта часть процесса компиляции по существу аналогична сборке программы на языке ассемблера.
Распределение памяти. Распределение памяти может быть отдельной фазой, выполняемой перед фактической генерацией кода, т. е. при получении машинного кода относительные (или абсолютные) адреса операндов вставляются в адресные поля машинных команд. Другая возможность заключается в том, чтобы отложить распределение памяти до стадии трансляции с языка ассемблера и предоставить генератору кода возможность работать только с символическими адресами. В этом случае выходом генератора является программа на языке ассемблера, и распределение памяти выполняется так же, как и на ассемблере. Независимо от используемого метода память должна быть выделена под все переменные, явно или неявно определенные в исходной программе; под все временные ячейки, остающиеся в оптимизированной матрице, и под все появляющиеся в программе литералы. Кроме того, должны быть выполнены начальные установки для соответствующих переменных.
В языках высокого уровня распределением памяти в значительной степени управляет пользователь. Раз заданы определения данных, единственным важным решением, остающимся на долю компилятора, является вопрос – где должны хранится эти переменные.
Память распределяется либо в области, непосредственно следующей за рассматриваемой подпрограммой, либо в отдельной части программы, где собираются вместе данные всех независимых сегментов, отделяя таким образом фиксированную и переменную части программы. В таких допускающих блочную структуру языках, как PL/1, необходимы специальные средства для отслеживания определений переменных в различных блоках.
Эффективное использование памяти для переменных, описанных в исходной программе, является задачей программиста. Но временные переменные, требующиеся для промежуточных результатов и определяемые компилятором, должны им и распределяться. То же самое справедливо для использования общих регистров и для эффективного использования базовых и индексных регистров. Эффективность в смысле распределения памяти обычно означает минимизацию количества памяти, используемой во время выполнения программы.
Фаза сборки. Задача, которую должна решать фаза сборки, во многом зависит от того, что было сделано при выполнении фазы генерации кода. В простейшем случае фаза сборки должна обработать все метки объектной программы, сформировать объектный модуль и информацию для загрузчика. В другом случае, если фаза генерации кода оставляет команды и метки в символическом виде, фаза сборки должна:
1) разрешить все символические ссылки;
2) вычислить адреса;
3) сгенерировать двоичные машинные команды;
4) выделить память и преобразовать литералы.
При решении этих задач используются следующие базы данных:
а) таблица идентификаторов. Простая фаза сборки использует эту базу данных для того, чтобы в таблице идентификаторов поместить значения всех меток;
b) таблица литералов. Более сложная фаза сборки приписывает адреса всем литералам;
с) объектный код. Выход фазы генерации кода.
Простая фаза сборки просматривает объектный код, разрешая все символьные ссылки и производя ТХТ файлы. Затем просматривается таблица идентификаторов и создаются ESD-файлы. Файлы словаря внешних символов (ESD) содержат информацию обо всех символах, которые определены в этой программе, но к которым возможно обращение извне, и обо всех символах, к которым имеются обращения в данной программе, но которые определены где-то вне этой программы. RLD-файлы (словарь перемещаемых символов содержит информацию о ячейках программы, содержимое которых зависит от расположения программы в памяти. Для таких ячеек ассемблер должен обеспечить информацию, позволяющую загрузчику скорректировать их содержимое) создаются с помощью объектного кода, ESD-файлов и таблицы идентификаторов.
Более сложная фаза сборки напоминает ассемблер. При практической реализации некоторые функции и базы данных могут исключаться, если они дублируются другими фазами компилятора.
Потоки информации. Информация между различными фазами компилятора передается через таблицы, строящиеся и используемые на отдельных проходах. На рисунке изображена сводка таблиц и других данных, используемых и создаваемых на различных фазах процесса компиляции.
Создаваемые таблицы Проход Постоянные таблицы
или другая информация




 Исходный
Лексический
Таблица
Ди-
Исходный
Лексический
Таблица
Ди-


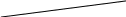
 код
анализ
терминалов
аг-
код
анализ
терминалов
аг-

 но-
но-



 сти-
сти-
Таблица Синтаксический Грамматика чес-
 однородных
анализ (свертки,
табли-
кие
однородных
анализ (свертки,
табли-
кие

 символов
ца
предшество-
символов
ца
предшество-
вания, порожда- со-


 ющие
правила)
об-
ющие
правила)
об-

 Таблица
Стек
ще-
Таблица
Стек
ще-


 идентифик.
ния
идентифик.
ния

 Интерпретация
Вспомогатель-
Интерпретация
Вспомогатель-
 ные
программы
ные
программы
Т аблица
аблица
л итерал.
итерал.
 Матрица
Оптимизация
Матрица
Оптимизация
 (или
дерево, (машинно-
(или
дерево, (машинно-
список, об- независимакя)

 ратная
поль-
ратная
поль-
ская запись) Правила

 оптимизации
оптимизации
 Оптимизиро-
Оптимизиро-
 ванная
ванная
матрица

 Распределение
Распределение
 памяти
Таблица
памяти
Таблица

 порождаемого
порождаемого
 Код
на языке Генерация кода
кода
Код
на языке Генерация кода
кода
 ассемблера
и МЗО
ассемблера
и МЗО
(перемещаемый) Трансляция с
Объектный код языка ассемблера
Некоторые из таблиц и данных постоянно включены в компилятор и используются для всех программ. Другие строятся во время компиляции и представляют интерес лишь на время компилирования конкретной программы.
Рассмотрим их по порядку создания и (первого) использования:
a) исходный код. Основной вход компилятора. Используется для генерации объектной программы. Его первоначальный вид представляет интерес только для лексического анализатора.
b) таблица терминалов. Постоянно существующая таблица, используемая лексическим анализатором. В ней перечислены все ключевые слова и специальные символы языка в их исходной форме и в виде однородных символов, которые помещаются в таблицу однородных символов лексическим анализатором. Последнее представление используется в синтаксическом анализе и интерпретации, первое – в лексическом анализе. Фактические символы доступны для последующих фаз компилятора через указатели, расположенные в таблице однородных символов.
c) таблица однородных символов. Создается лексическим анализатором при распознавании отдельных обозначений исходной программы. Каждая запись имеет стандартный вид и содержит только синтаксический класс элемента языка и указатель на место, в котором хранится дополнительная касающаяся его информация. ТОС используется при синтаксическом анализе и интерпретации.
d) таблица идентификаторов. Содержит все переменные программы, определенные явно или неявно программистом, или же сгенерированные компилятором для хранения промежуточных величин. Записи содержат всю информацию, необходимую для ссылок и распределения памяти под переменные. Создается лексическим анализатором, который помещает в эту таблицу символические имена переменных программы, а соответствующие указатели – в таблицу однородных символов. Расширяется во время интерпретации и распределения памяти за счет включения в нее дополнительной информации, такой, как класс памяти, длина, точность и относительный адрес. Во время оптимизации лишние записи исключаются. Используется на стадии генерации кода и сборки.
e) таблица литералов. Содержит все константы программы. Ее конструкция и использование аналогичны конструкции и использованию таблицы идентификаторов.
f) грамматика. Постоянная таблица, используемая при синтаксическом анализе в сочетании с таблицей однородных символов для выявления синтаксической структуры программы. В зависимости от языка и используемого метода грамматического разбора она может быть представлена в виде таблицы предшествования.
g) диагностические сообщения. Постоянный список текстов, из которого выбирается и печатается соответствующий элемент при обнаружении ошибки во время лексического или синтаксического анализа, или на стадии интерпретации. Поиск в нем обычно сочетается с работой процедуры обработки ошибки.
h) вспомогательные подпрограммы. Подпрограммы, инициируемые синтаксическим анализатором. (Некоторые из них могут вызываться также лексическим анализатором). Ими генерируется шаг за шагом промежуточная форма исходной программы.
i) матрица. Наиболее часто используемая промежуточная форма исходной программы. Другими возможными промежуточными представлениями являются деревья, списки и (обратная) польская запись. Создается вспомогательными подпрограммами на стадии интерпретации. Оптимизируется на проходе машинно-независимой оптимизации с помощью правил обычной и булевой алгебры для минимизации числа команд программы и требований к памяти.
j) оптимизированная матрица. Создается из матрицы на стадии машинно-независимой оптимизации. Является объектом машинно-зависимой оптимизации и используется на проходах распределения памяти и генерации кода.
k) таблица порождаемого кода. Постоянная таблица определений кода. Для каждого оператора матрицы существует подпрограмма, содержащая основу генерируемого кода. На фактический код влияют правила оптимизации (например, какие будут использоваться регистры или какие промежуточные результаты будут сохранены и где). В некоторых реализациях ее можно функционально рассматривать как набор условных макросов.
l) код на языке ассемблера. Версия исходной программы на языке ассемблера, создаваемая на генерирующем код проходе. В некоторых компиляторах эта версия опускается или частично представляется в машинном коде. Является входом ассемблера.
m) перемещаемый объектный код. Окончательный выход компилятора. Является точным отображением операторов исходной программы в машинный код, готовый для обработки загрузчиком, связывающим, загружающим и начинающим выполнение программы.
Форматы записей таблиц компилятора.
Таблица терминалов:
Символ |
Указатель типа |
Таблица однородных символов
Синтаксический класс 1 |
Указатель 1 |
Таблица идентификаторов:
Символическое имя 1, 4 |
Атрибуты данных 2, 3, 4 |
Адрес 5 |
Таблица литералов:
Литерал 1 |
Точность 1 |
Адрес 5 |
Матрица и оптимизированная матрица:
Номер записи |
Однородный символ (оператор) |
Однородный символ (операнд-1) |
Однородный символ (операнд-2) |
Связки (указатели вперед и назад) |
3, 4 |
3, 4 |
3, 4 |
3, 4 |
3, 4 |
Стек:
Адрес текущей вершины стека |
Однородный символ |
Однородный символ |
|
Однородный символ |
2, 3 |
2, 3 |
2, 3 |
|
2, 3 |
Цифры в конце полей указывают на каком проходе в данное поле заносится информация: 1 – лексический анализ; 2 – синтаксический анализ; 3 – интерпретация; 4 – МНО; 5 – распределение памяти; 6 – генерация кода; 7 – трансляция программы на языке ассемблера.
Просмотры компилятора. Рассмотрим компилятор не в терминах его логических фаз, а с точки зрения физических просмотров, которые должны быть сделаны над его базами данных.

Вызов первого просмотра
Компилятор . . . . . . . . . . . . . . . . . . . . . . . .
Вызов N-го просмотра





Просмотр 1 2 3 4 N-3 N-2 N-1 N



Лексичес- Синтакси- Оптимизация Распреде- Генерация Сборка
кий ческий ление кода
анализ анализ памяти

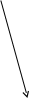






UST



Исходная Матрица
программа
Объектный Объектный

 код
модуль
код
модуль
Таблица Таблица
терминальных идентификаторов
символов и литералов
Первый просмотр соответствует фазе лексического анализа. Он просматривает исходную программу, выделяет идентификаторы, литералы и создает таблицы стандартных символов (UST).
Второй просмотр соответствует синтаксической фазе и фазе интерпретации. Просматривается таблица стандартных символов, создается матрица, и информация об идентификаторах помещается в таблицу идентификаторов. Первый и второй просмотры можно объединить в один, рассматривая лексический анализ как программу интерпретации, которая проводит грамматический разбор исходной программы и размещает лексические единицы по мере необходимости в стек.
Просмотры с 3го по N-3й относятся к фазе оптимизации. Каждый отдельный вид оптимизации может потребовать нескольких просмотров матрицы.
N-2й просмотр соответствует фазе распределения памяти. При выполнении этого просмотра таблицы идентификаторов и литералов используются в большей степени, чем сама программа.
N-1й просмотр соответствует фазе генерации. Просматривается матрица и создается первая версия объектного модуля.
Nй просмотр соответствует фазе сборки. Разрешаются символьные ссылки и создается информация для загрузчика. Этот просмотр в общих чертах соответствует второму просмотру ассемблера. Добавление к компилятору макросредств или других дополнительных возможностей может потребовать дополнительных просмотров.