Симметричные (smp) многопроцессорные вс. Архитектура типа uma, coma, numa
Мультипроцессор Sun Enterprise 10000
Симметричные (SMP) многопроцессорные ВС. Архитектура типа UMA, COMA, NUMA
Мультипроцессор, как и все компьютеры, должен содержать устройства ввода-вывода (диски, сетевые адаптеры и т. п.). В одних мультипроцессорных системах только определенные процессоры имеют доступ к устройствам ввода-вывода и, следовательно, имеют специальную функцию ввода-вывода. В других мультипроцессорных системах каждый процессор имеет доступ к любому устройству ввода-вывода. Если все процессоры имеют равный доступ ко всем модулям памяти и всем устройствам ввода-вывода и каждый процессор взаимозаменим с другими процессорами, то такая система называется SMP (Symmetric Multiprocessor — симметричный мультипроцессор).
В системах с общей памятью все процессоры имеют равные возможности по доступу к единому адресному пространству. Единая память может быть построена как одноблочная или по модульному принципу, но обычно практикуется второй вариант.
Вычислительные системы с общей памятью, где доступ любого процессора к памяти производится единообразно и занимает одинаковое время, называют системами с однородным доступом к памяти и обозначают аббревиатурой UMA (Uniform Memory Access). Это наиболее распространенная архитектура памяти параллельных ВС с общей памятью.
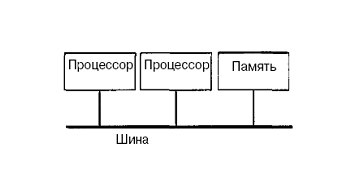
Технически UMA-системы предполагают наличие узла, соединяющего каждый изn процессоров с каждым изт модулей памяти. Простейший путь построения таких ВС - объединение нескольких процессоров (P) с единой памятью (Mp) посредством общей шины (рис.). В этом случае, однако, в каждый момент времени обмен по шине может вести только один из процессоров, то есть процессоры должны соперничать за доступ к шине. Когда процессор Рi, выбирает из памяти команду, остальные процессорыPj (i<> j) должны ожидать, пока шина освободится. Если в систему входят только два процессора, они в состоянии работать с производительностью, близкой к максимальной, поскольку их доступ к шине можно чередовать; пока один процессор декодирует и выполняет команду, другой вправе использовать шину для выборки из памяти следующей команды. Однако когда добавляется третий процессор, производительность начинает падать.
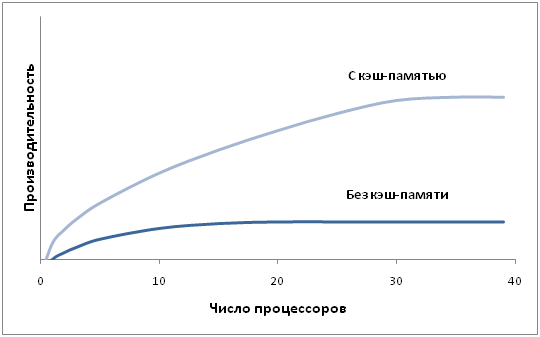
При наличии на шине десяти процессоров, кривая быстродействия шины становится горизонтальной, так что добавление 11-го процессора уже не дает повышения производительности. Нижняя кривая на рисунке иллюстрирует тот факт, что память и шина обладают фиксированной пропускной способностью, определяемой комбинацией длительности цикла памяти и протоколом шины, и в многопроцессорной системе с общей шиной эта пропускная способность распределена между несколькими процессорами. Если длительность цикла процессора больше по сравнению с циклом памяти, к шине можно подключать много процессоров. Однако фактически процессор обычно намного быстрее памяти, поэтому данная схема широкого применения не находит.
Архитектура UMA
Можно оптимизировать архитектуру UMA, добавляя локальный кэш и локальную память к каждому из процессоров.
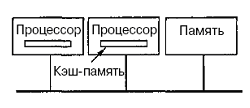
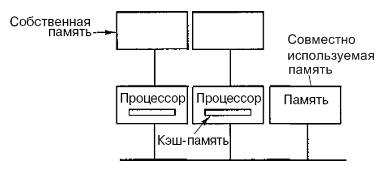
Чтобы оптимально использовать последнюю конфигурацию, компилятор должен поместить в локальные модули памяти весь текст программы, цепочки, константы, другие данные, предназначенные только для чтения, стеки и локальные переменные. Общая разделенная память используется только для общих переменных. В большинстве случаев такое разумное размещение сильно сокращает количество данных, передаваемых по шине, и не требует активного вмешательства со стороны компилятора.
Мультипроцессоры UMA с координатными коммутаторами
Даже при всех возможных оптимизациях использование только одной шины ограничивает размер мультипроцессора UMA до 16 или 32 процессоров. Чтобы получить больший размер, требуется другой тип коммуникационной сети. Самая простая схема соединения n процессоров с к блоками памяти — координатный коммутатор (рис). Координатные коммутаторы используются на протяжении многих десятилетий для соединения группы входящих линий с рядом выходящих линий произвольным образом.
Координатный коммутатор представляет собой неблокируемую сеть. Это значит, что процессор всегда будет связан с нужным блоком памяти, даже если какая-то линия или узел уже заняты. Более того, никакого предварительного планирования не требуется.
Недостаток системы: рост узлов как n2. При наличии 1000 процессоров и 1000 модулей памяти получаем число узлов – 1 млн. Это неприемлемо. Тем не менее координатные коммутаторы вполне применимы для систем средних размеров.
Мультипроцессоры UMA с многоступенчатымисетями
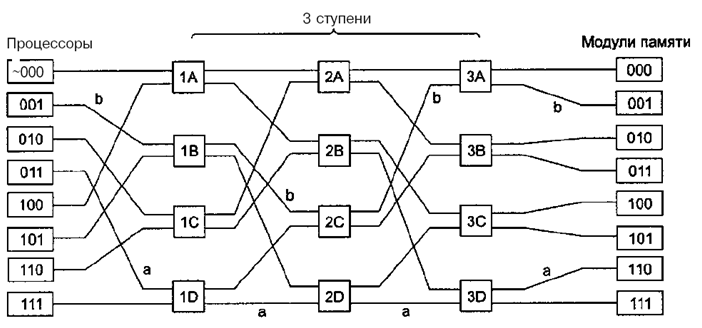
В основе подхода – коммутатор 2x2. Этот коммутатор содержит два входа и два выхода. Сообщения, приходящие на любую из входных линий, могут переключаться на любую выходную линию. В нашем примере сообщения будут содержать до четырех частей.
Поле Модуль сообщает, какую память использовать. Поле Адрес определяет адрес в этом модуле памяти. В поле Код операции содержится операция, например READ или WRITE. Наконец, дополнительное поле Значение может содержать операнд, например 32-битное слово, которое нужно записать при выполнении операции WRITE. Коммутатор исследует полеМодуль и использует его для определения, через какую выходную линию нужно отправить сообщение: через X или через Y.
Наши коммутаторы 2x2 можно компоновать различными способами и получатьмногоступенчатые сети.
Один из возможных вариантов — сеть omega. Здесь мы соединили 8 процессоров с 8 модулями памяти, используя 12 коммутаторов. Для n процессоров и n модулей памяти нам понадобится log2n ступеней, n/2 коммутаторов на каждую ступень, то есть всего (n/2)log2nкоммутаторов, что намного лучше, чем n2 узлов (точек пересечения), особенно для больших n.
Каждая ступень для передачи сигнала в соответствующем направлении использует биты в полеМодуль (0 – верхний выход, 1 – нижний). При этом после прохождения ступени соответствующие биты становятся не нужны и они заменяются на номер входной линии. Рассматривая пути a и b (на рис.), видим, что они используют разные коммутаторы, следовательно, запросы могут выполняться параллельно.
В отличие от координатного коммутатора, сеть omega — это блокируемая сеть. Не всякий набор запросов может передаваться одновременно. Конфликты могут возникать при использовании одного и того же провода или одного и того же коммутатора, а также между запросами, направленными к памяти, и ответами, исходящими из памяти.